
大型语言模型 (LLM)在推理领域表现出了令人感兴趣的能力。随着它们的使用,一个新的应用领域应运而生:提示工程。事实上,与这些模型的交互是通过使用提示进行的,因此,已经开发出了一些技术来改进 LLM 的这些能力。
最有趣的技术之一是思路链 (CoT) 提示;这种技术提高了推理问题的正确性,并解释了模型如何得出解决方案(或它犯了哪些推理错误)。CoT 是一种通过中间步骤提示模型得出解决方案(而不是生成解决方案)的技术
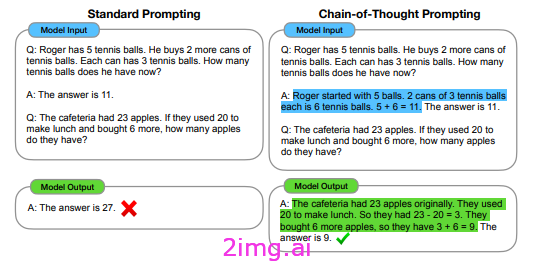

这种技术非常有趣 [2–3],因为它在零样本设置中也有效。只需强制模型逐步推理(只需在提示中添加“让我们逐步思考”即可),推理问题的结果就会显著改善。
当然,这种技术也有缺点:模型会产生较长的输出,并且系统延迟(完成响应所需的时间)会增加。这源于模型的自回归性质,该模型一次解码一个单词。当模型必须与用户交互时,这种额外的计算成本和时间延迟是不可取的。
这些推理步骤真的有必要吗?模型的措辞难道不能强制吗?
如您所见,当今的模型越来越冗长。尽管答案过去要短得多,但新的 LLM 却用于创建越来越长的输出。在某种程度上,这是一种可取的行为,因为从理论上讲,这些响应总是更完整,可以更好地剖析问题主题。另一方面,响应通常不必要地冗长(尤其是当问题需要简短回答时)。对于用户来说,过长的答案可能会令人沮丧,尤其是在多轮问答设置中。此外,较长的响应并不总是更好。它通常充满了离题、不相关的细节,并且更容易产生幻觉。
问题之一是,没有考虑到输出的简洁性的评估指标,也没有惩罚避免过长的推理链的行为。直观地说,推理链越长,中间结果错误的风险就越大。因此,错误的中间结果对于 LLM 来说可能很难纠正(同样是因为其自回归性质)。
LLM 答复的长度取决于什么?
生成的响应的长度受多种因素影响。主要因素包括:提出的问题、体系结构、大小、预处理和后处理步骤、提示工程技术以及提示中添加的上下文。
很容易想象,生成的 token 越多,生成时间就越长。此外,模型越大,生成相同响应所需的时间就越长(70B 参数的模型生成相同数量的 token 所需的时间与 7B 参数的模型相比更长)
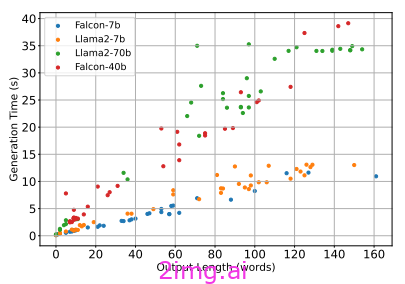
CoT 增加了模型的生成时间,因为还必须生成中间推理步骤。因此,标记数量越多意味着每个响应的生成时间越长。
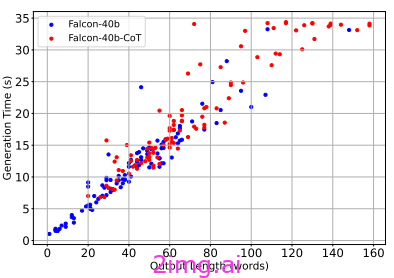
到目前为止,大多数研究都忽略了效率而注重准确性,因此我们没有考虑效率的指标。在这项研究 [4] 中,他们提出了三个指标来评估模型的准确性和简洁性:
- Hard-k 简洁准确度。它测量正确且不超过一定长度 k 的输出的比例。
- Soft-k 简洁准确度。与前一个类似,但会惩罚超过一定长度的正确答案。
- 一致的简洁准确度。对先前指标的概括,考虑到所有输出的长度变化。
现在我们有了一种方法可以同时衡量准确性和简洁性,我们可以尝试找到一种方法来在使用 CoT 时限制 LLM 中的推理步骤。本文 [4] 的作者建议在 CoT 中明确这一要求,以迫使模型压缩其推理。因此,这是一个 ZeroShot-COT 提示,添加了短语“并将答案的长度限制为 n 个单词”(其中 n 是所需的单词数)。

一旦你得到一个迫使模型更简洁地响应的提示,你可能会想知道这是否会影响模型的准确性。在研究中,他们分析了 5 个预先训练的模型(Vicuna-13B、Falcon 7B和 40B、Llama2 7B和 70B)。然后他们在GSM8K 基准数据集(推理问题最广泛使用的数据集)上对它们进行测试,并尝试不同的 n 值(15、30、45、60、100)。
结果表明,强制使用 token 数量可显著减少生成时间(这当然是意料之中的,因为模型产生的 token 数量要少得多)。如果模型不正确,这个结果将毫无意义(我们只会得到一个快速但错误的答案)。令人惊讶的是,对于像 Llama2–70B 和 Vicuna-13B 这样的模型,添加长度约束可以提高准确率(Falcon 7B 和 40B 并非如此)
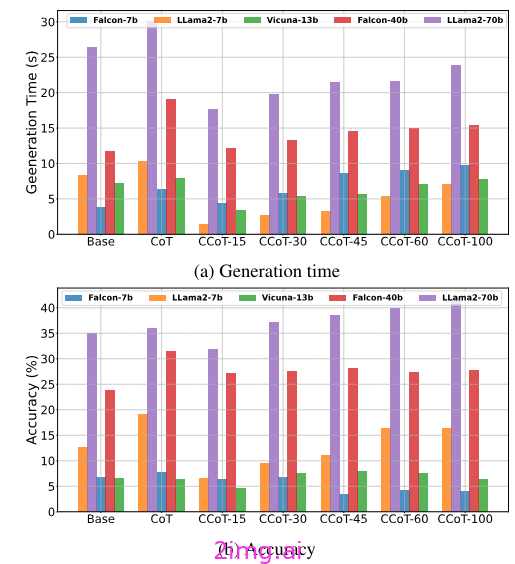
对于作者来说,这种可变性取决于模型本身的因素,例如大小和训练。较小的模型似乎从这种方法中获益较少(实际上它们的表现更差)。此外,Llama2–70B(获益最多的模型)已在庞大且更加多样化的数据集上进行了训练。而且,它从更高的推理基线开始。
这是 Llama2–70B 对数学问题的响应示例。在这种情况下,我们可以观察到基本响应,包括 CoT 或不同的约束。有趣的是,即使只有很少的 token 可用于生成正确答案及其推理中间体,它也能得出正确答案。

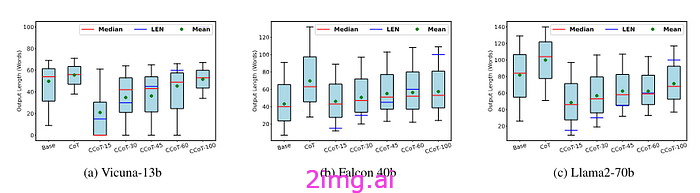
分析模型输出的长度分布会显示一些有趣的结果。红线是中位数,而蓝线是根据假设的长度约束,LLM 应该满足的标记数。如果没有长度约束,模型会产生更长的响应,但同时模型不满足约束(中位数超过蓝线)。
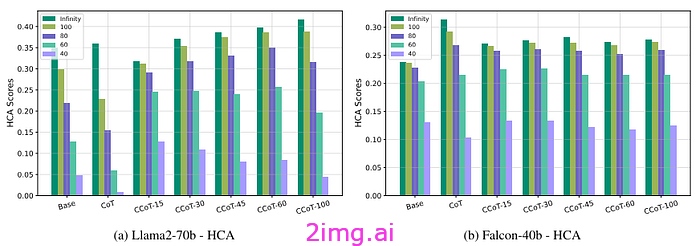
之前,我们定义了三个指标来评估我们的模型,既要准确,又要简洁。通过评估 Hard-k 简洁准确度,准确度会降低。如果我们选择的 k 值太低(超过该字数,即使答案是正确的,也会被视为错误),即使使用受约束的 CoT,我们也会得到较低的结果(这在一定程度上是因为模型没有达到所需的长度)。对于合理的 k 值,我们发现使用新提出的 CoT 的答案既准确又简洁。
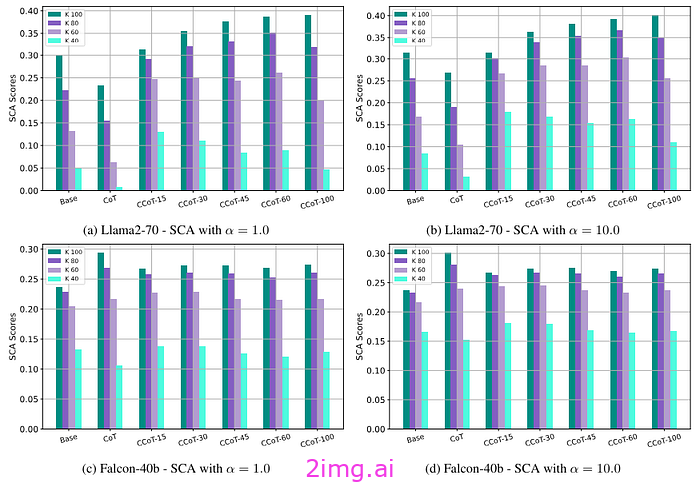
当我们查看软简洁性准确度 (SCA) 时,这些结果得到了证实。在这种情况下,α 的值表示接受比所需限制 k 更长的答案的容忍度。换句话说,即使答案超出了一定的字数限制,我们也会接受或不接受正确答案。这些结果表明,即使 CoT 受到限制,一些正确答案也会超出一定长度。也可能有些答案仍然需要更多的推理步骤才能回答,并且不能压缩到某个阈值以上。或者,由于模型的冗长性质,它们很难满足严格的限制。
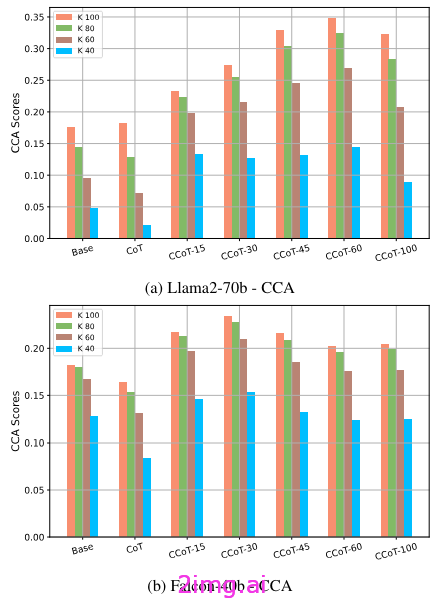
相反,一致简洁准确度衡量的是平均长度是否一致,从而衡量它们是否平均满足约束。值得注意的是,长度约束增加的模型在要生成的输出长度方面具有更大的自由度(并使用这种自由度)。
正如我们在本文中看到的,LLM 天生冗长,往往会产生不必要的长响应。一方面,现代 LLM 会写出更丰富、更完整的答案。另一方面,感兴趣的答案隐藏在未经请求的细节中,您必须等到生成完成,并且存在相当大的延迟。推理链对于解决数学问题或当您拥有带有代理的系统时非常有用。由于自回归性质,这些链可能非常长,LLM 无法纠正错误的中间体。此外,LLM 还可能卡在推理链的一代中(例如,使用 ReAct 提示和代理)。因此,强制模型遵守一定的长度具有一定的吸引力。
将 CoT 强制为特定的输出长度 [4] 不仅不会降低推理能力,而且似乎还能提高某些模型的性能。目前尚不清楚为什么会发生这种情况(机制研究会很有趣),以及为什么它在较大的模型中效果更好。另一方面,研究是否与幻觉有关也很有趣(当然,生成的标记越多,风险就越大)。
RA/SD 衍生者AI训练营。发布者:稻草人,转载请注明出处:https://www.shxcj.com/archives/4808