
同行评审是科学的基础支柱。科学文献是一种可靠的信息手段,它让该领域的专家审查和检查其他方面的工作。说现代科学(从自然科学到计算机科学的任何科学学科)都基于同行评审,这并不是夸张。文章通过同行评审是一种保证文章可靠性和准确性的印章。尽管同行评审在科学过程中至关重要,但它远非完美。
通常,不同的论文(或科学会议)有不同的流程。不过,几乎总是将稿件发送给编辑,编辑评估文章的整体信息,然后将其发送给两到三位审稿人。审稿人是该领域的科学专家,与作者没有任何关系。这些专家阅读并评估稿件,并向作者和编辑提供反馈。然后,作者必须回应这些反馈,如有必要,根据审稿人的建议进行进一步的实验、修正或更改稿件的其他元素。完成这些操作后,编辑后的稿件将发回给审稿人和编辑。审稿人建议是接受还是拒绝,然后由编辑做出决定。如果审稿人认为需要更多修正,则流程重新开始 [1]。
我认为同行评审阻碍了科学的发展。事实上,我认为它已经成为一个完全腐败的体系。它在很多方面都是腐败的,科学家和学者把对科学和科学家的判断权交给了这些期刊的编辑。——悉尼·布伦纳
这通常意味着一篇文章至少需要三个月才能被接受[2]。这些数据没有考虑到被拒绝的文章比例非常高,因此需要在不同期刊上多次经历这一过程。
审稿人没有报酬,而且审阅稿件需要花费大量时间 [3]。因此,许多研究人员不愿意全身心投入。近年来,能够进行同行评审的研究人员越来越少。与此同时,提交给期刊的文章数量却在不断增加 [4]。
多年来,同行评审已被证明存在许多问题:
- 判断不够严谨,决策不稳定,经常受到外界因素的影响,且评审人员的判断也经常存在分歧[5–6]。
- 研究人员的所属关系往往比其工作质量更具影响力[7]。
- 由于大多数评论者都是男性,因此存在性别偏见[8–9]。
出于这些原因,人们开始怀疑这个过程是否可以自动化。分析一篇文章并提供反馈(简而言之,同行评审过程)可以定义为自然语言处理(NLP) 任务。更准确地说,我们可以将其定义为生成式人工智能任务,在给定上下文(手稿)的情况下,我们希望生成反馈。
以前,人们尝试过在狭窄的方面和有限的范围内实现自动化。这些方法侧重于提取材料和方法、提供文章摘要以及参考文献的文献计量分析。这是因为科学文章的分析因特定技术语言的知识而变得复杂(许多通用模型很难适应科学领域)并且需要具有该主题的先验知识的模型(并且可以适应该领域的新发展)。
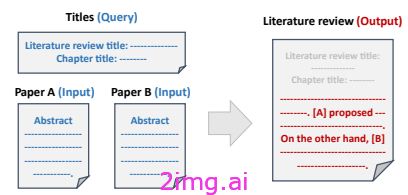

例如,在这项研究 [10] 中,他们将文章中的关键词提取(通过使用BERT)与文章的引文分析相结合。输出是系统生成的评论:
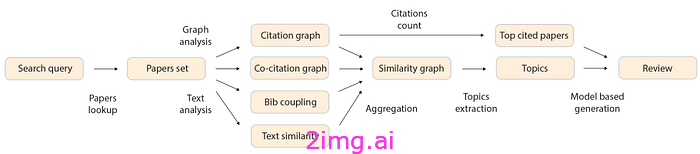
但这些方法都有严重的局限性:没有推理而是基于提取,往往重复或冗余,依赖于固定模板,没有信息的整合。
一些作者认为大型语言模型 (LLM)是解决这些问题的方案。毕竟,LLM 在零样本和小样本学习、常识和逻辑推理方面表现优异,并且可以多种方式用于 NLP 任务。
另一方面,使用 LLM 也存在一些问题:
- 无法继续学习,从而失去学习新知识的可能性。
- 适应科学领域,是使用大量非特定文本训练的通用模型。
- 产生幻觉,从而生成听起来绝对合理但充满不准确信息的文本。
显然,这些问题是众所周知的,并且已被研究界解决。已经开发了几种系统来尝试纠正这些行为,例如检索增强生成 (RAG)。
Galactica [12]就是这些问题如何导致科学界惨败的一个例子。这个法学硕士项目由 Meta 创建,重点关注科学领域,作者声称它能够生成自动评论。该模型后来在三天后被撤回,正是因为它产生了幻觉 [13]。
Galactica 的一个根本问题是它无法区分真假,而这是生成科学文本的语言模型的基本要求。人们发现,它编造了假论文(有时将其归为真实作者),并生成了关于太空熊历史的维基文章,就像生成关于蛋白质复合物和光速的文章一样容易。——来源

尽管先例尝试都以失败告终,但人们对自动生成评论仍然特别感兴趣。事实上,这将减少需要分析的文章积压,节省文章提交者的时间,可用于标准化流程,减少偏见等等。

总结一下自动审核的步骤:
- 我们应该有一个了解该主题主要文献的模型。
- 该模型应该能够对文献进行批判性阅读。
- 该模型应该尽量减少幻觉。
- 该模型应该能够对文章提供反馈。
我们将研究如何解决前三个问题。
一些研究人员认为,导致 Galactica 失败的原因是其自大。事实上,在这项研究中,他们试图创建一个适用于所有科学领域的模型,低估了其异质性。相反,在最近的一项研究 [14] 中,他们试图使用 LLM 自动生成文献综述,从而将 LLM 的使用限制在一个科学任务上,也限制在一个科学领域(丙烷脱氢 (PDH) 催化剂)。
这更好地模仿了审稿人的工作,审稿人必须执行有限的任务,并且对科学领域具有深入但具体的知识。
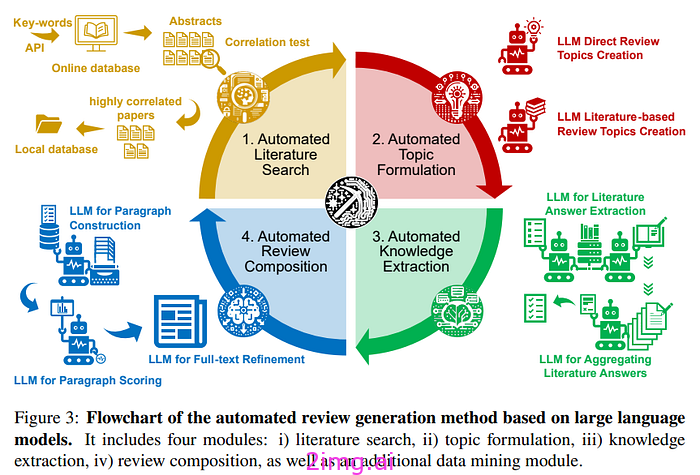
作者首先查找了 1980 年至今特定领域的所有文章(尤其是来自优质化学和化学工程期刊列表的文章)。然后,他们首先过滤掉明显的重复内容(得益于标题和摘要),然后使用 LLM 进行分析以选出与项目相关的所有文章。
为了应对 LLM 中的幻觉问题,我们高度重视对此类现象的检测和预防。在整个自动评论生成过程中,我们采用了多级过滤和验证质量控制策略,类似于检索增强生成 (RAG) 的概念 —来源
由于幻觉是 LLM 在科学领域应用的主要限制因素,作者特别关注如何尽可能减少幻觉。他们从提示开始,选择严格而明确的指示来指导 LLM 产生最科学准确的输出。此外,他们没有执行单一任务,而是将流程分解为几个特定的子任务(阅读、总结等)。这背后的想法是保持事实一致性,但同时又具有灵活性。因此,作者建立了一个问题列表,以帮助模型提取相关内容,并同时根据内容进行回答。然后,作者对文本进行分段,并继续进行,就像与模型对话一样。
此外,他们还采取了以下步骤:
- 文本格式过滤。幻觉也源于文本结构中断,因此他们验证了文本结构(许多情况下是 XML)是准确的。
- DOI 验证。DOI 是每篇文章的唯一标识符;使用它作为验证系统可以让他们过滤掉一些潜在的幻觉。
- 相关性验证。在 RAG 文档中,冗余或包含不相关信息的文档会影响性能。作者分析响应是否偏离主题。
- 自洽性验证。由于幻觉往往具有随机性,因此,如果存在多个交互,则正确答案应该是最频繁的。因此,作者使用聚合来消除随机幻觉。
- 完整的数据流可追溯机制。一旦生成,您就可以追溯到生成的路径,这样您就可以验证系统
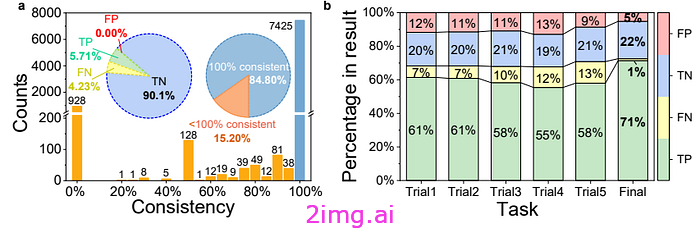
在此过程结束时,作者会检查幻觉,重点检查两种类型的不准确性:
误报包括虚假或不一致的信息,以及漏报,指忽略或部分提取的内容。我们的重点主要是减少误报,同时对漏报采取相对宽容的态度。 —来源
结果表明,该过程大大减少了幻觉。
因此,到目前为止,我们已经有了一个能够了解先前文献并尽量减少幻觉的系统。下一步是建立一个能够对稿件进行批判性阅读、提出更正、潜在实验并提供反馈的系统。最后一步可以通过向模型提出具体问题来完成(“文章中使用的统计分析是否正确?作者是否考虑了最近的文献?结果是否存在不一致之处?等等”)。
然而,这一步需要额外的推理技能,目前超出了法学硕士的能力范围。这意味着法学硕士一方的完整同行评审仍然不完全可行。此外,极少数幻觉仍然不是零幻觉。
但这并不意味着我无法提供帮助,比如标记文章中的潜在错误或问题。目前,该系统已经可以识别与文献不一致的地方、一些潜在错误,并提供一些潜在反馈。进行同行评审是一个需要集中精力且劳动密集型的过程;使用法学硕士进行快速的首次评审可以减轻研究人员的工作负担。
Paragoger衍生者AI训练营。发布者:稻草人,转载请注明出处:https://www.shxcj.com/archives/4796