
这有什么大不了的?
LLAMA 3.1 的发布标志着 AI 开发的一个重要里程碑。开源模型首次接近领先的闭源模型的性能水平。这一转变预示着未来开源模型同样有效,任何人都可以灵活地修改和调整它们。马克·扎克伯格将此与 Linux 的开源性质进行了比较,并暗示 LLAMA 3.1 可能成为未来创新的基础技术。
关键见解
LLAMA 3.1 论文内容丰富(长达 92 页),包含大量有价值的信息。虽然这篇博文不会涵盖所有细节,但以下是我的一些主要亮点:
简单的训练食谱
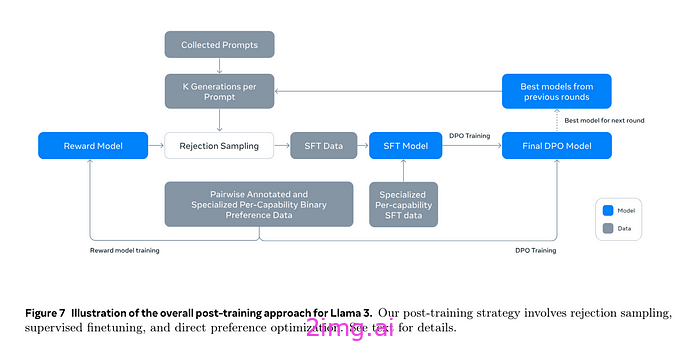
Meta 通过简化训练过程来优化训练过程。他们使用简单、稳定的方法,虽然收敛速度较慢,但中断更少,稳定性更高。通过选择标准密集 Transformer 模型架构并进行细微调整,他们最大限度地提高了训练稳定性,优于更复杂的模型,例如混合专家模型。训练后程序涉及监督微调 (SFT)、拒绝抽样 (RS) 和直接偏好优化 (DPO),避免了更复杂的强化学习算法的不稳定性。
训练前退火
机器学习中的退火涉及在训练过程中逐渐降低学习率,类似于在冶金学中缓慢冷却材料以消除缺陷。这种方法有助于精确微调模型参数,防止可能破坏模型稳定性的大规模更新。在退火阶段,将优先考虑高质量的数据源,使用最佳数据完善模型并提高其性能和泛化能力。
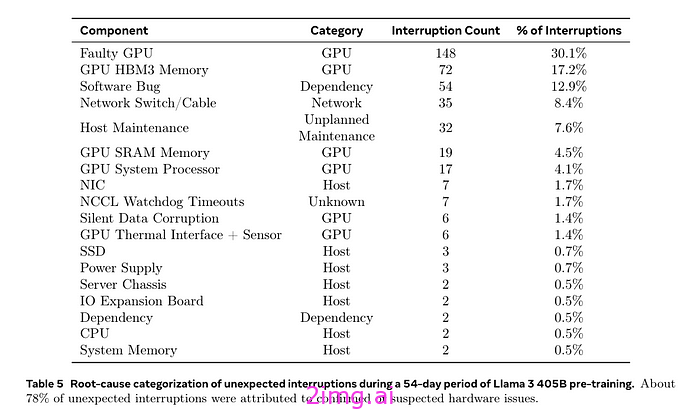
训练中断
在 LLAMA 3.1 预训练的 54 天快照中,出现了 466 次作业中断。其中大多数是意外的,并归因于硬件问题,尤其是 GPU 故障。尽管中断次数很多,但大多数问题都由自动化处理,仅需要三次大量人工干预。
有趣的是,其中两次中断是由于服务器底盘问题造成的,这为这个故事增添了人为因素。想想看,有人不小心撞到了服务器底盘,导致了这些中断,真是有趣。

奖励模型的作用
在 LLAMA 3.1 框架中,奖励模型主要用于拒绝抽样,而不是人工反馈强化学习 (RLHF)。拒绝抽样涉及过滤掉低质量数据以提高数据集的整体质量,这是预训练和监督微调 (SFT) 期间的关键步骤。
RLHF 上的拒绝采样
Meta 选择使用直接偏好优化 (DPO) 而不是 RLHF,这意味着奖励模型不直接用于模型对齐。相反,它根据人类偏好评估响应的质量。这种评估使模型能够过滤掉低于标准的响应并保留高质量的响应,从而确保数据集保持一流水平。
不同阶段采用不同的奖励模式
- 预训练:此阶段使用的奖励模型基于 distilBERT。该模型有助于有效地对数据质量进行分类,确保仅使用最佳数据进行初始训练。
- 训练后:使用了更复杂的奖励模型,具体来说是 LLAMA 3.1 检查点。这种容量更大的模型确保在训练的后期阶段进行更精细的质量控制,强调了数据质量的重要性。
注释者编辑步骤
为了进一步提高数据质量,在偏好排序之后加入了一个编辑步骤。注释者将审查首选响应并直接编辑它们或提示模型根据反馈完善其响应。此过程通常会导致三个排序的响应:已编辑、已选择和已拒绝。通过加入此步骤,Meta 确保数据集不仅包含高质量的响应,而且还受益于人类专业知识和迭代改进。
改进解析
我们开发了高质量的 HTML 解析器,以确保抓取的代码和数学文本的质量。这些解析器针对样板删除和内容调用的精确度进行了优化,保留了数学和代码内容的结构。这种一丝不苟的方法有助于保持训练数据的高标准,这对于主要在网络数据上进行训练的模型来说至关重要。
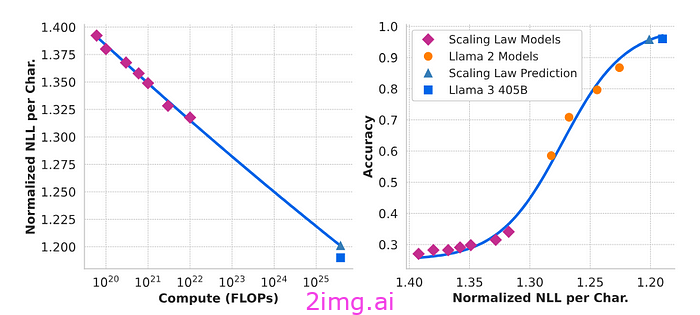
下游任务的缩放定律
为了预测 LLAMA 3 在下游任务上的表现,Meta 采用了计算优化模型来分析和预测基准数据集的结果。这涉及两个关键步骤:
- 与训练 FLOP 的相关性:
- 负对数似然:Meta 将正确答案的负对数似然与训练期间使用的计算工作量(以浮点运算(FLOP)衡量)相关联。
2. S 形关系:
- 对数似然和准确率:通过在基准任务上建立负对数似然和准确率之间的 S 形关系,Meta 可以更准确地预测性能。该方法外推了四个数量级,略微低估了旗舰 LLAMA 3 模型的最终性能,但仍提供了有价值的见解。
这种预测方法代表了模型性能评估方式的重大变化。传统上,仅使用负对数似然并不能可靠地预测下游任务的性能。然而,Meta 的方法表明,只要有正确的相关性和转换,就可以有效地使用它来预测模型的成功。
合成数据
合成数据在 LLAMA 3.1 等模型的训练和微调中发挥着越来越重要的作用。虽然密集的人工注释可以解决数据质量问题,但合成数据生成提供了一种可扩展且经济高效的替代方案。
后期培训的重要性
合成数据可以实现更快、更可扩展的训练过程。它有助于快速生成大量数据,这对于需要大量多样化数据集的模型至关重要。然而,关键挑战是确保这些合成数据的质量,因此需要使用拒绝采样和过滤等方法。
数据生成专家模型
元训练专用模型(特别是针对代码和数学数据)可生成高质量的合成数据。这些专家模型有助于创建和过滤更准确、更相关的微调数据。这种专业化可确保使用的合成数据具有最高质量,从而提高整体性能。
自生成数据的挑战
使用同一模型生成的合成数据进行自身微调通常不会带来显著的改进。这是因为模型本质上是从已知的数据中学习,这不会提供新的信息或挑战。
执行反馈
为了解决这个问题,Meta 引入了执行反馈。这涉及模型检查其错误、纠正错误,然后使用这些纠正后的答案进行进一步微调。这个迭代过程使模型能够从错误中吸取教训并显著提高其性能。
数据清理和处理
高质量、多样化的数据是 LLAMA 3.1 成功的核心支柱。Meta 团队实施了许多过滤和质量检查步骤,以确保数据符合其严格的标准。以下是他们使用的一些关键策略:
1.基于规则的数据清理:
- 在最初的几轮中,团队发现了几种不良模式,例如过度使用表情符号或感叹号。他们实施了基于规则的策略来删除或修改有问题的数据。例如,为了解决过度道歉的语气,他们平衡了数据集中“我很抱歉”或“我道歉”等短语的比例。
2.主题分类:
- 该团队将 LLAMA 3 8B 微调为主题分类器。该分类器用于将数据分为大类(“数学推理”)和更具体的子类(“几何和三角学”)。这种分类使他们能够抽取需要改进的正确数据分布。
3.质量评分:
- 奖励模型评分:使用奖励模型对数据进行评分,其中位于上四分位数的样本被视为高质量。
- 基于 LLAMA 的评分:LLAMA 3 检查点对一般英语数据(准确性、指令遵循和语气/表达)采用三分制评分,对编码数据(错误识别和用户意图)采用两分制评分。得分最高的样本被认为是高质量的。
- 结合分数:尽管奖励模型和基于 LLAMA 的分数之间存在很高的不一致率,但结合这些信号可以在内部测试集上产生最佳的回忆效果。
Paragoger衍生者AI训练营。发布者:稻草人,转载请注明出处:https://www.shxcj.com/archives/4746