
介绍:
计算机视觉和自然语言处理领域正在迅速发展,对针对特定下游任务进行微调的专用模型的需求日益增长。然而,拥有不同的微调模型有多个缺点:
1. 对于每个任务,必须存储和部署单独的模型(可以通过应用 LoRA 等方法进行微调来解决此问题)。2
. 独立微调的模型无法从相关任务的信息中获益,这限制了它们在域内和域外任务中的泛化。然而,多任务学习需要访问每个特定任务的数据集,而整合这些数据集可能很复杂。如果我们无法访问所有下游任务的数据集,但可以使用微调模型,该怎么办?想象一下,您需要一个针对一组特定任务进行微调的大型语言模型 (LLM)。您无需为下游任务收集大量数据集并进行资源密集型的微调过程,而是可以找到针对每个任务进行微调的 LLM,并合并这些模型以创建所需的模型。请注意,在拥有约 50 万个经过微调的模型的大型 Hugging Face 存储库中找到此类模型并不困难。合并多个模型最近引起了广泛关注,主要是因为它需要轻量级计算并且不需要训练数据。
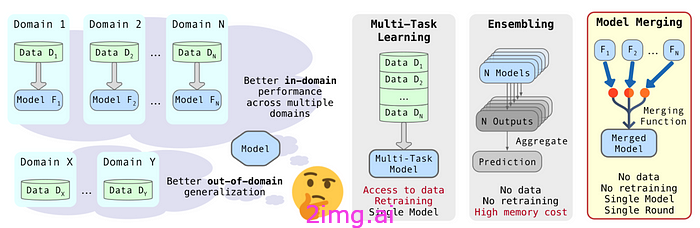

随着人们对合并的关注度不断提高,WEBUI 和 MergeKit 等公共库已经开发出来以促进这一过程。WebUI 可以使用不同的合并技术合并经过微调的模型(例如稳定扩散)。MergeKit 是一个开源的集中式库,提供不同的合并方法。它通过高效实现适用于任何硬件的合并技术来促进模型合并。
在这里,我们将合并方法分为三大类:1. 合并具有相同架构和初始化的模型;2. 合并具有相同架构但初始化不同的模型;3. 合并具有不同架构的模型。每个类别都涉及不同的技术来有效地组合模型,下面将对此进行解释。
1. 合并具有相同架构和初始化的模型:
1.a 无需数据合并:
本节中的模型合并方法均基于线性模式连接(LMC)。LMC 建议,对于具有相同架构和初始化的模型,其检查点之间的损失可以通过低损失的线性路径连接。这意味着可以使用线性插值组合这些模型。
为了微调模型,可以应用各种配置,例如不同的学习率、随机种子和数据增强技术,从而产生不同的模型参数。模型汤建议对这些参数进行平均,因为这些模型已经学习了相似的表示,并且在参数空间中很接近。加权模型平均导致平坦的局部最优,并且更好地泛化到分布外的任务[参见13、14 ]
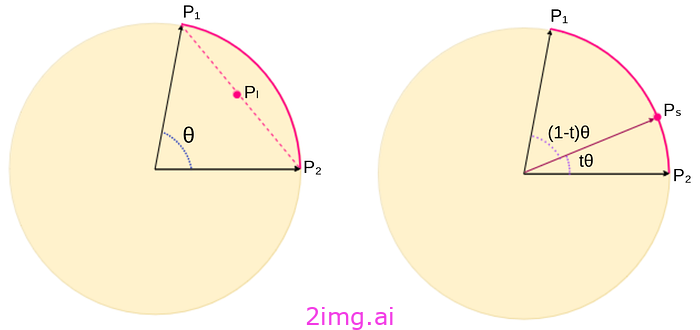
SLERP(球面线性插值,最早在这里介绍)是计算机图形和动画中常用于在四元数表示的旋转之间进行平滑插值的一种技术。SLERP 也适用于模型合并。它通过沿球面路径而不是直线插值来合并两组模型参数。图 2 显示,对于给定的两个模型参数 p1 和 p2,SLERP 沿地球表面合并这些参数,提供平滑的过渡。此方法通常用于合并 LLM。
假设给出了两个 MLP 模型,每个模型都针对不同的下游任务进行了微调。SLERP 可以使用以下步骤合并这两个模型:
步骤 1:对于每个模型参数,将它们展平并连接到向量 v1、v2
步骤 2:将向量 v1 和 v2 规范化为单位超球面表面上(得到 v1′ 和 v2′)。
步骤 3:计算这两个向量之间的角度 θ(以弧度为单位)。
步骤 4:使用 SLERP 公式计算 Vslerp,如下所示:
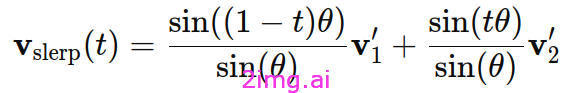
其中 t 是插值参数,t=0 表示仅使用模型 1,而 t=1 表示仅使用模型 2。
线性加权平均技术(例如模型汤和 SLERP)在计算机视觉领域很常见,从图像处理和分类模型到图像生成模型(例如潜在扩散模型)。
任务算术引入了一种基于任务向量的方法。任务向量的计算方法是从针对特定任务微调的同一模型的权重(θft)中减去预训练模型的权重(θpre),即
τ = θft − θpre。该向量表示预训练模型权重空间中的方向,朝该方向移动可提高该任务的性能。任务向量可以通过负数和加法等算术运算组合在一起。对任务向量取负(θpre — τ)会降低模型在目标任务(遗忘)上的性能,而对控制任务的影响最小。为了提高预训练模型在多个任务中的性能,我们可以首先为每个任务学习一个任务向量。然后通过对这些任务向量(θpre+∑τi)求和,我们可以提高模型同时处理多个任务的能力。
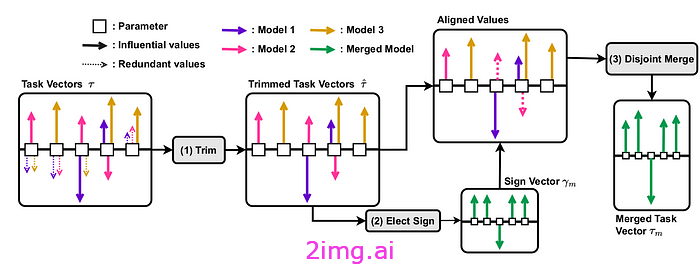
TIES解决了在组合任务向量 (∑τi) 时由于参数干扰而导致的性能下降问题。此问题可以通过三个步骤解决(见图 3):(
1)将每个任务向量修剪为前 k%(通常为 k=20)个最大幅度值;
(2)对于每个非零参数,选择所有任务向量中总幅度最高的符号以避免冲突更改;
(3)仅合并与所选向量具有相同符号的任务向量的值。
DARE主要关注 LLM 的模型合并,并识别任务向量 (τ = θft−θpre) 中的极端冗余。它提出了一个三步方法:
1- 随机删除 p%(通常 p =90)的任务向量值,
2- 将剩余的值按 1/(1 − p) 的倍数重新缩放,
3- 合并 (θpre + λi ∑τi),
其中 λi 是缩放项,表示要合并的每个任务向量的重要性。
1.b 与数据要求合并:
我们上面讨论的合并方法不需要数据。但是,有些方法确实需要数据来确定合并参数的最佳权重。这些方法使用数据来计算激活,然后相应地调整权重。
一种方法是Fisher 合并。给定 K 个微调模型,每个模型从特定的预训练检查点开始针对不同的下游任务进行训练,Fisher 合并对每个模型的参数进行加权求和。权重是使用 Fisher 信息矩阵计算的,这需要来自每个任务的一些数据来构建矩阵。
在相关发展中,RegMean通过将模型合并任务重新定义为线性回归问题,其表现明显优于 Fisher 加权合并。该方法推导出线性层权重的闭式解,并均匀地插入其他权重(如层正则化和偏差项)。给定 K 个微调模型和一些数据 Xi i= 1,..,K,对于每个任务,合并模型的线性层可以按如下方式确定:
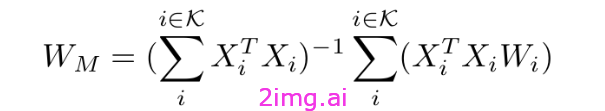
其中 Wi 是第 i 个微调模型的线性层。
2. 合并具有相同架构但不同初始化的模型
对于具有相同架构和训练数据集但初始化不同的模型,简单的合并方法(如线性模型组合)通常效果不佳。主要原因是模型的权重不一致。因此,研究人员开发了利用神经网络置换对称性的技术。通过重新排序模型的神经元,它们的权重可以更好地对齐,从而使合并过程更有效。
Git-Rebasin建议对一个模型的权重进行置换,以匹配另一个模型的配置。假设两个模型 A 和 B 具有相同的架构和训练数据集,但它们的初始化和训练数据顺序不同。每个网络的权重都可以进行置换,而不会改变其功能,这意味着交换隐藏层中的神经元可以产生功能等效的模型。
他们将其表述为一个优化问题,以确定跨层单元的最优排列,以使两个模型的参数在权重空间中对齐。这种对齐确保模型处于损失景观的相似“盆地”中,从而实现平滑有效的合并。为了实现这一目标,Git-Rebasin 提出了以下三个步骤:
1. 对于每一层,寻找最佳排列的问题被表述为线性分配问题 (LAP)。此步骤涉及计算激活矩阵并找到使激活对齐的最优排列矩阵。2
. 给定所有层的最佳排列,将对模型 B 的权重进行排列。3
. 模型 B 的排列权重与模型 A 的权重之间的线性模型组合位于损失景观中的低损失盆地内,这确保合并后的模型表现良好。
REPAIR解决了 Rebasin 合并方法中称为方差崩溃的一个关键问题,其中隐藏单元的激活方差明显小于插值前原始网络的相应单元。因此,神经元的激活在更深的层中几乎保持不变,因此网络将不再能够区分输入。REPAIR 通过重新调整插值网络的激活以匹配原始网络的统计特性来解决此问题。通过调整激活的均值和方差,插值网络在其各个层中保持功能可变性。应用 REPAIR 方法可显著降低插值障碍,从而提高插值模型的性能。
3.合并具有不同架构的模型
与迄今为止讨论的方法不同,Frankenmerging不会将模型融合为一个模型,而是按顺序堆叠不同模型的不同层。因此,它能够合并具有不同架构的模型。例如,要构建具有 40 层的 LLM,可以将一个 LLM 的前 24 层堆叠到另一个 LLM 的第 25-40 层上。这种方法在计算机视觉的风格转换中引起了极大关注。尽管需要大量的反复试验和实验,但它已经产生了令人印象深刻的 LLM 模型,例如 Goliath 和 Solar-10.7B [参见此处]。

EvolutionaryOptimization提出了一个框架来自动合并给定的一组基础模型,使得合并后的模型优于给定集合中的任何单个模型。 该方法涉及两个主要阶段(见图 4):
在第一阶段,该方法使用 TIES-Merging 和 DARE 对 N 个基础模型进行分层合并。该过程使用由特定于任务的指标(例如 MGSM 的准确度、VQA 的 ROUGE 分数)指导的进化算法进行优化。为了找到未知变量(例如 DARE 中的 dropout 百分比和合并中每个模型参数的权重),进化优化从一组随时间演变的可能解决方案开始。通过变异(小的随机变化)和交叉(结合两个解决方案的部分),选择最佳解决方案以创建一组新的候选方案。这个迭代过程会逐步产生更好的解决方案。
在第二阶段,给定一组 N 个模型,目标是使用 Frankenmerging 找到具有 T 层的最佳模型。为了减少搜索空间并使优化易于处理,所有层都按顺序排列(即,第 i 个模型中的所有层后面是第 i + 1 个模型中的层)并重复 r 次。在此阶段,目标是找到一个确定层的包含/排除的最佳指标:如果 Indicator(i)>0,则第 i 层包含在合并模型中;否则,将其排除。
EvolutionaryOptimization过程首先将第一阶段应用于一组模型。然后,将第一步的合并模型添加到给定的集合中,并将第二阶段应用于这个扩大的集合,以找到一个最佳指标,为最终的合并模型选择 T 层。这种方法适用于将日语 LLM 与英语数学 LLM 合并以构建日语数学 LLM。合并后的模型在各种已建立的日语 LLM 基准上取得了最先进的性能,甚至优于具有更多参数的模型,尽管这些模型没有接受过此类任务的训练。
Paragoger衍生者AI训练营。发布者:稻草人,转载请注明出处:https://www.shxcj.com/archives/4710