
介绍
AI 代理可以通过一系列思维过程分解高度模糊的问题,类似于人类的推理,从而处理这些问题。这些代理可以使用各种工具(包括程序、API、网络搜索等)来执行任务并寻找解决方案。
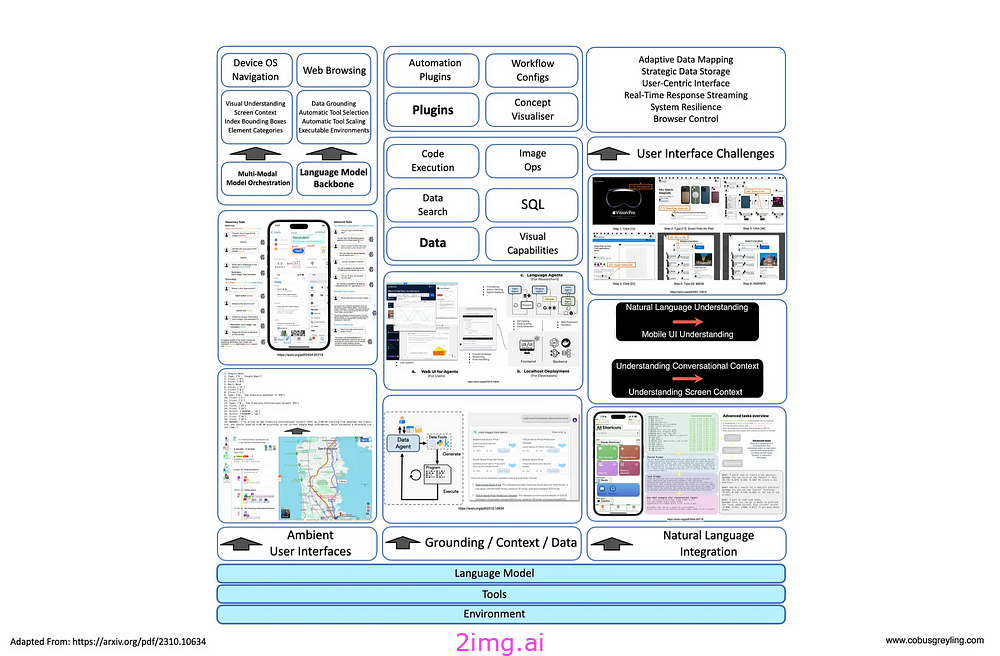

该图说明了组成 AI Agent 的各种组件,包括其网页浏览功能以及导出手机屏幕、桌面视图和网页浏览器的功能。
限制
AI 代理主要依靠基于 API 的方法来访问数据和其他资源。为了使 AI 代理实现更高水平的自主性,引入更多模式至关重要。
最近,人工智能代理在映射、解释和导航图形用户界面 (GUI)(例如浏览器、桌面和手机操作系统)方面取得了重大进展。
这一进步使得 AI 代理在使用 GUI 方面的能力更接近人类。
该领域值得注意的研究包括 LangChain 的工作原型实现,例如 Apple 的 WebVoyager 和 Ferrit-UI。
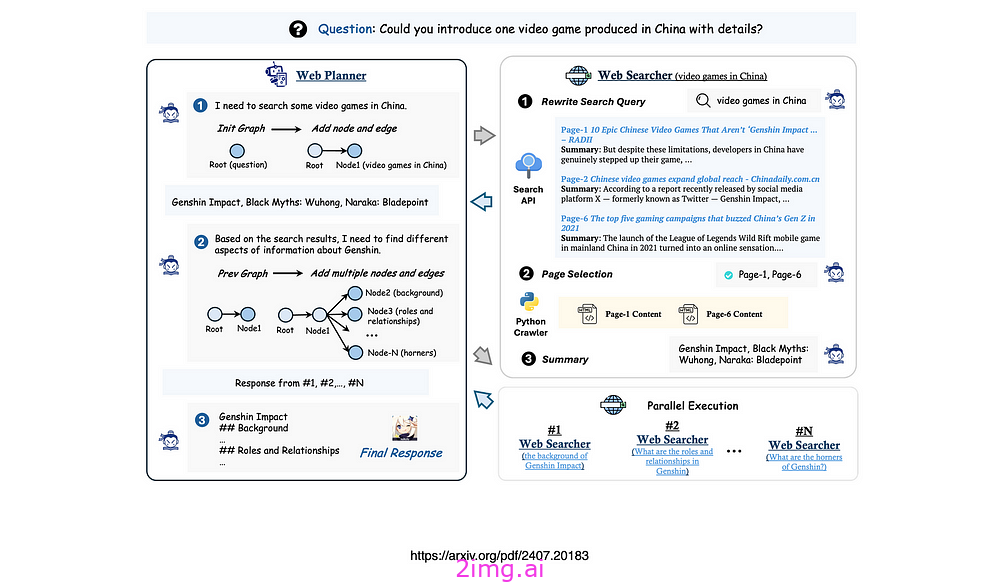
MindSearch 是人工智能代理的一个典型例子,它将收到的指令分解为一系列中间步骤,并将这些步骤转换为图形表示。
GUI 代理工具
微软最近的研究成果 OmniParser 是一款通用的屏幕解析工具,旨在将 UI 屏幕截图中的信息提取到结构化的边界框和标签中,从而增强 GPT-4V 在各种用户任务中的动作预测性能。
复杂任务通常可以分解为多个步骤,每个步骤都需要模型具备以下能力:
- 通过分析检测到的带有数字 ID 的图标的整体内容和功能来了解当前的 UI 屏幕,并
- 预测屏幕上的下一步动作来完成任务。
为了简化此过程,在初始解析阶段提取屏幕语义等信息被发现很有帮助。这减轻了 GPT-4V 的负担,使其能够更加专注于预测下一步动作。
OmniParser 结合了以下输出:
- 经过微调的可交互图标检测模型,
- 经过微调的图标描述模型,以及
- 一个 OCR 模块。
这种组合产生了一个结构化的、类似于 DOM 的 UI 表示和一个覆盖有潜在可交互元素边界框的屏幕截图。
由于缺乏强大的屏幕解析技术,跨不同应用程序的多个操作系统上的通用代理的潜力在很大程度上被低估了:
- 可靠地识别用户界面中的可交互图标,以及
- 理解屏幕截图中各种元素的语义以及
- 将预期动作与屏幕上的相应区域准确地关联起来。
可交互区域检测
识别 UI 屏幕上的可交互区域对于确定针对给定用户任务要执行什么操作至关重要。
微软没有直接提示 GPT-4V 预测要操作的具体 XY 坐标,而是使用了 Set-of-Marks 方法。此方法将可交互图标的边界框叠加在 UI 屏幕截图上,并要求 GPT-4V 生成操作的边界框 ID。
与以前依赖于 Web 浏览器中 DOM 树中的真实按钮位置或数据集中的标记边界框的方法不同,Microsoft 对检测模型进行了微调,以提取可交互的图标和按钮。
研究人员整理了一个可交互图标检测数据集,其中包含 67k 张独特的屏幕截图,每个图像都标有来自 DOM 树的可交互图标的边界框。
除了检测可交互区域外,他们还使用 OCR 模块提取文本边界框。然后合并来自 OCR 和图标检测模块的边界框,删除重叠度较高的框(使用 90% 重叠度阈值)。
每个边界框都使用一种简单的算法标记一个唯一的 ID,以最大限度地减少数字标签和其他边界框之间的重叠。
下面是 Omniparser 解析的截图图像和局部语义的示例。
Omniparser 的输入包括用户任务和 UI 屏幕截图。
通过这些输入,Omniparser 生成:
- 已解析的屏幕截图,其中包含重叠的边界框和数字 ID,以及
- 本地语义,包括提取的文本和图标描述。

Omniparser 涵盖三个不同的平台:移动平台、桌面平台和 Web 浏览器平台。
解析结果显著提高了 GPT-4V 在 ScreenSpot 基准测试中的表现。Omniparser 在 Mind2Web 上使用 HTML 提取信息的 GPT-4V 代理以及在 AITW 基准测试中使用专门的 Android 图标检测模型增强的 GPT-4V 代理的表现均优于后者。
Omniparser 旨在成为一种多功能、易于使用的工具,用于解析 PC 和移动平台上的用户屏幕,而无需依赖 HTML 或 Android 视图层次结构等附加信息。

最后
通过提供详细的上下文信息和对用户界面内各个元素的精确理解,细粒度的局部语义使模型能够做出更明智的决策。
标签准确度的提高不仅可以确保识别正确的图标并与其预期功能相关联,而且还有助于在应用程序内实现更有效、更可靠的交互。
因此,将详细的局部语义纳入模型的处理框架中可以获得更准确、更符合上下文的响应,最终提高 GPT-4V 的整体性能。
RA/SD 衍生者AI训练营。发布者:稻草人,转载请注明出处:https://www.shxcj.com/archives/4676