
RAG 或检索增强生成,使 LLM 能够从一个或多个数据源检索信息,并使用这些信息来回答用户查询。设置基本的 RAG 系统相对简单,但开发一个既强大又可靠的系统却面临许多挑战和陷阱,尤其是在优化计算效率时。
在本篇博文中,我们将探讨开发 RAG 系统时常见的陷阱,并介绍旨在提高检索质量、最大限度地减少幻觉和处理复杂查询的先进技术。在阅读完本文后,您将更深入地了解构建 RAG 系统所涉及的复杂性,并了解如何开始解决这些问题。
从基础到高级 RAG
下面是大多数人使用的 RAG 基本流程图。它显示了查询 -> 检索 -> 答案的基本流程
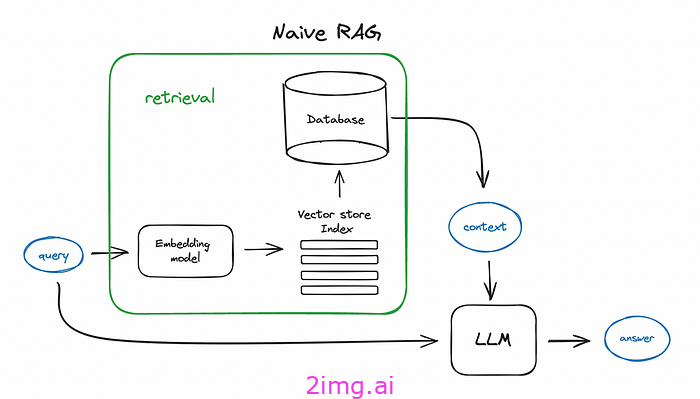

上面我们看到查询 -> 检索 -> 回答的基本流程包含许多步骤。具体来说,它涉及通过嵌入模型将查询转换为嵌入,然后查找与数据源现有数据库的相似性,选择最相关的文档,最后将其反馈给 LLM 以回答初始查询。我们可以将其写成
查询 -> 查询嵌入 -> 相似性搜索 -> 检索 -> 上下文 -> 回答
上述流程分为 5 个阶段,每个阶段都有其失败点,例如:
- 查询:用户可能没有写出好的查询
- 查询嵌入:查询模型没有创建良好的代表性嵌入
- 相似性搜索:相似性搜索遗漏了文档源中最相关的信息,或者文档源没有相关信息
- 检索:检索到的大部分信息不相关或缺乏上下文
- 上下文:回答查询时可能会使用我们过去的知识,或者不能正确使用从检索到的上下文中获取的信息
因此,为了创建一个强大而可靠的 RAG 系统,我们必须在每个阶段进行干预,如上图中的箭头所示。这就是我们所说的高级 RAG 系统:
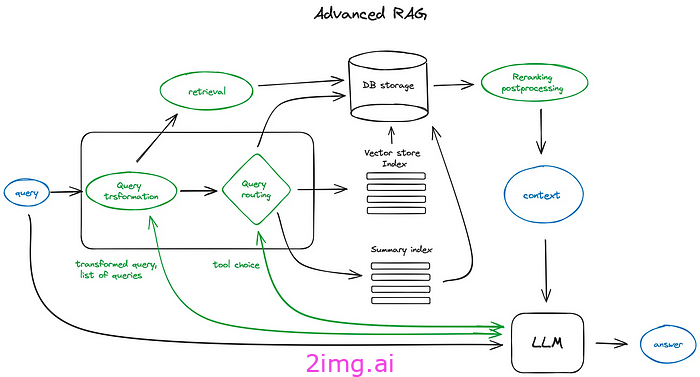
不要害怕看这个!每个新添加的组件都可以非常简单自然地解释。
下面我们将详细介绍上面添加的每个新绿色组件及其动机和好处。
查询转换
很多时候,用户输入的查询结构不太好、语法不正确或有歧义,而回答查询可能需要多步推理。
如果查询结构不合理或模棱两可,我们可以简单地使用 LLM 并要求其更好地构建查询。为了处理需要多个推理步骤的复杂查询,我们可以执行多步骤查询分解:
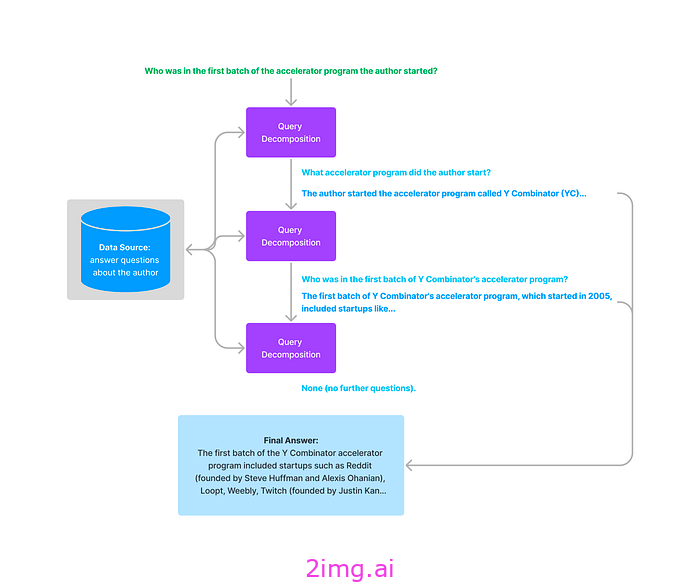
在这里,查询被分解为子查询。然后使用开头介绍的基本 RAG 流程回答每个子查询。然后,每个答案与原始问题一起再次输入到 LLM 中,以合成最终答案。
我们可以按顺序生成子查询(如上所示),也可以同时生成所有子查询。例如,对于查询“柏林夏季的平均气温是否高于 2005 年的平均气温”,生成的子查询将是“柏林当前的平均气温”、“2005 年柏林的平均气温”,然后使用这两个查询的答案,LLM 将能够为我们提供最终答案。
查询分解很重要,因为提出分析或逻辑问题的用户查询可能不会直接在文档列表中说明。例如,可能没有句子说“柏林今天的平均气温低于 2005 年”,因此使用用户查询进行直接向量搜索只会产生不相关的文档。
查询路由
我们通常有多个数据源,或者将文档分组,以便更紧凑地检索。用户的答案通常会结合多个来源的知识,因此我们需要知道从哪个文档源检索以及我们可以从该源获得哪些信息。
下面的例子中,我们看到我们使用不同的子查询分别查询休斯顿和波士顿数据库,并利用查询的答案来获得最终答案。
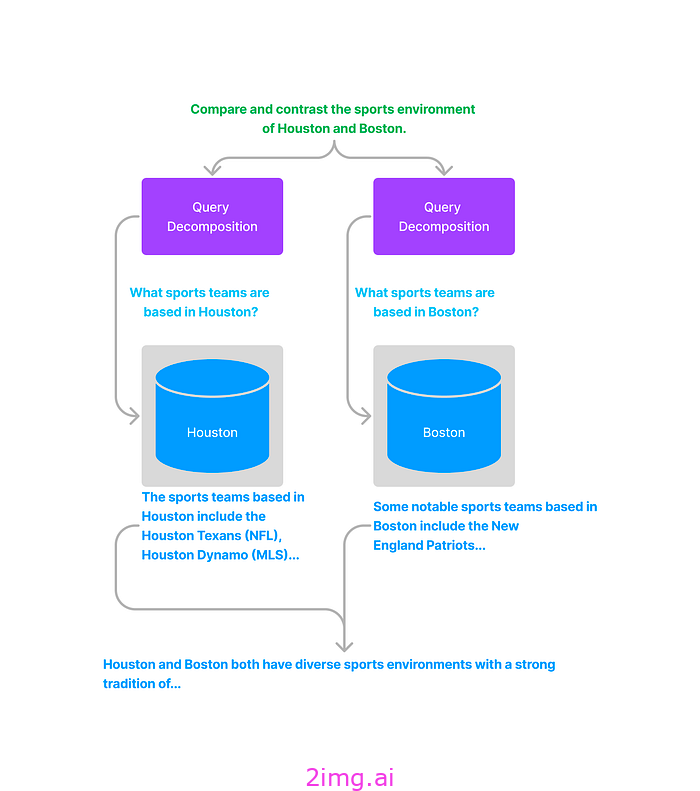
每个文档源都有一个描述,我们将其提供给 LLM,大致告诉 LLM 文档源中包含哪些信息。此描述通常由用户生成,例如)上面的 Huston 文档源可以有这样的描述:“有关休斯顿运动队的所有数据”。
然后,我们询问法学硕士哪个文档源是相关的,并针对该文档源生成一个子查询列表,这将有助于回答用户的问题。
在这里,我们还可以用代理/API/工具替换数据源,并要求 LLM 提出参数以使该代理执行特定任务,然后在下游使用输出。
您可以查看以下参考资料以获取工作示例:Colab和YouTube
检索
现在我们可以更好地处理用户的查询,让我们在本节中介绍两种高级检索方法,以了解如何通过执行基本的 RAG 更好地识别相关文档
密集通道检索
通常,我们使用相同的嵌入模型来编码文档和查询。但是,此嵌入模型是一种通用嵌入模型,可能无法将查询转换为表示与回答查询所需的相关性的嵌入空间。HyDE 等方法试图规避这一点,但由于幻觉,效果不佳。
为了提高检索性能,我们可以使用密集段落检索器,它使用不同的编码器对查询和文档进行编码。它们已使用 Siamese 目标对问答对进行训练。
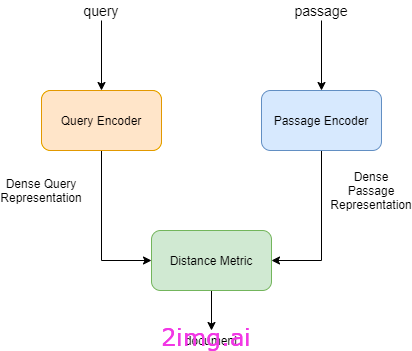
覆盖
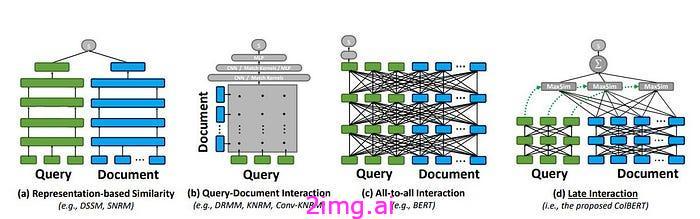
CoBERT 提供了一种不同的排名和检索方式,它比普通余弦嵌入比较甚至密集段落检索更细粒度。CoBERT 的主要直觉是跨词嵌入进行比较,而不是将查询和文档压缩为有限的一维嵌入向量,这可能无法总结查询和文档中的所有内容。
这种检索的优点是可以从不同的查询标记中获得细粒度的相似性,例如,考虑这样的查询:“2005 年 X 公司所有产品的总收入”。这里的关键词是“总收入”、“所有产品”和“2005 年”。整体查询与讨论 X 公司收入、X 公司特定年份的收入、X 公司收入的某些产品、该公司 2005 年的总收入等段落具有很高的相似性。您会发现,围绕感兴趣的确切查询有很多东西,因此进行密集嵌入会非常嘈杂。
我们不会将查询和文档压缩为单个嵌入向量,而是对它们进行标记并通过单独的编码器传递,以获得一组丰富的词嵌入。因此,对于输入查询标记,我们从 q1、q2、q3… -> x1、x2、x3 …。对于文档标记,我们从 d1、d2、d3…。-> y1、y2、y3…。
现在我们对每个向量进行成对相似性计算,得出一个相关矩阵,然后取每行的最大值并对这些值求和,得到一个称为 MaxSim 的分数。
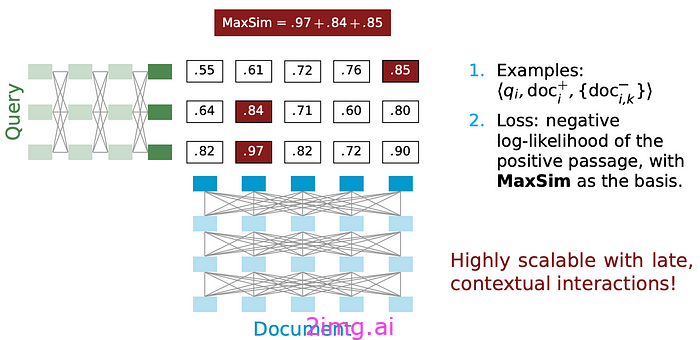
本质上,我们将查询中的每个词嵌入与文档中的每个词嵌入进行比较,并选择相似度最高的分数,因为它衡量了查询内容的匹配度。与BM25相比,CoBERT 的检索性能提高了 2 倍以上。查询/文档编码器也可以针对我们的任务进行微调,以获得略微更好的结果。
要了解有关 CoBERT 的更多信息,请查看他们的论文或本文
重新排序和后期处理
现在我们可以更好地检索我们的文档,让我们在使用它们生成最终答案之前,看看如何更好地对获得的文档进行重新排序和后处理。
重新排名
就像上面两种方法一样,我们可以使用多种方法从文档源中检索内容。我们可以使用多个密集嵌入模型或更经典的方法(如BM25)来获得多组 top-k 检索结果。
一旦我们获得了这些不同的 top-k 结果集,我们必须在这些集合内进行重新排序,以使用诸如倒数排序融合之类的方法获得一组 top-k 结果。有很多方法可以融合多个 top-k 集,包括根据对具有相似性截止值的检索方法进行实验来提出启发式方法等
后期处理:注释链
Chain of Note(CoN)是一种功能强大且非常流行的方法,可以对我们的检索进行后处理,使其更适合问答。Chain of Note 主要在三个方面提供帮助:
- 减少法学硕士幻觉
- 文件中含有相互矛盾或不公正信息的情况
- 法学硕士必须运用其知识和内容来回答问题的情况
CoN 要求法学硕士在每次检索时做笔记。这允许法学硕士仔细检查每次检索的相关性并关注与查询相关的关键信息。CoN 在两者之间增加了一层笔记,类似于思路提示。
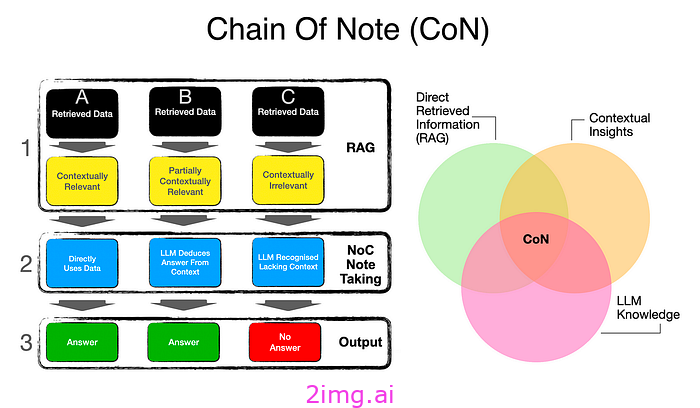
在上图中,我们看到了 CoN 如何处于 RAG 的交叉点,并使用 Contextual Insights 和 LLM Knowledge 来更好地处理故障点。
请考虑以下示例:

在上面的第一个例子中,我们看到了 CoN 如何帮助处理冲突信息;在第二个例子中,我们看到了如何处理非常接近相关性但仍未得到所需答案的检索,以及最后如何处理完全不相关的检索。
Chain Of Note 被广泛用于提高检索性能。您可以在此处阅读相关内容。
我们还可以在 CoN 中连接互联网,查看更高级的 CoN 版本:校正检索增强生成,它通过搜索互联网来填充缺失的内容,从而细化模棱两可的片段。
结论
我们在上面看到,基本 RAG 管道上的每个点:
查询 -> 查询嵌入 -> 相似性搜索 -> 检索 -> 上下文 -> 回答
存在缺陷,可以进行增强以提高我们的 RAG 系统的可靠性。我们介绍了查询转换和查询路由,以改进我们的查询并更好地利用我们的数据源/工具。我们介绍了密集段落检索和 CoBERT 等高级检索技术,以提高我们检索到的数据的质量,最后,我们介绍了重新排名和 CoN 后处理,以便更好地利用检索到的段落进行问答。
Paragoger衍生者AI训练营。发布者:稻草人,转载请注明出处:https://www.shxcj.com/archives/4645