


步骤 1 # 预训练
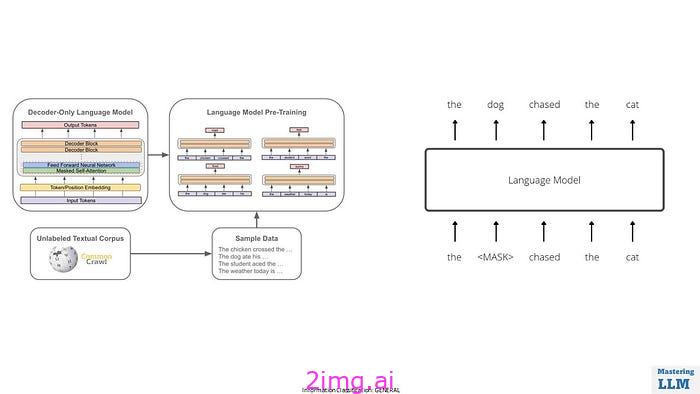
在预训练阶段,该模型被训练为互联网规模数据上的下一个单词预测器。
在预训练阶段
- 从互联网上收集大量多样化的数据集。此数据集包含来自各种来源的文本,以确保模型能够学习广泛的语言模式。
- 清理和预处理数据以消除噪音、格式问题和不相关的信息。
- 将清理后的文本数据标记为更小的单元,例如单词或子词片段(例如,字节对编码或WordPiece)。
- 对于 GPT-3 这样的 LLM,Transformer 架构因其在处理序列数据方面的有效性而被广泛使用。
- 大型语言模型 (LLM) 的预训练是通过使用海量数据集训练模型预测文本序列中的下一个单词来使其能够理解和生成类似人类的语言。
推出面试准备新课程
我们推出了新课程“大型语言模型(LLM)面试问答”系列。
该计划旨在弥补全球人工智能行业的就业差距。它包括来自 FAANG 和财富 500 强等顶级公司的 100 多个问题和答案以及100 多个自我评估问题。
该课程提供定期更新、自我评估问题、社区支持和全面的课程,涵盖从快速工程和 LLM 基础到监督微调 (SFT) LLM、部署、幻觉、评估和代理等所有内容。
步骤 1 之后的模型输出
如果我们使用一个经过预训练的模型,该模型刚刚学会预测下一个单词,并且不将输入作为问题或指令。在训练数据模型期间,可能会将这些问题序列视为某种试卷,然后该模型只会预测下一个单词。
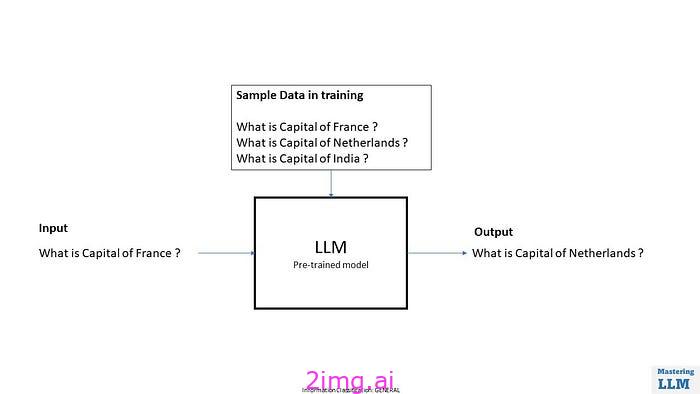
如果您使用过 LLM,您可能已经注意到,有时模型会给出垃圾值并且不会在正确的点停止。如果您探索过基于聊天的模型,它会在答案中提出另一个问题并回答它,因为它在训练期间已经看到了这些类型的数据。
模型输入:
**用户**:你好,我需要饮食方面的帮助吗?
**助手**:当然可以,我可以帮你。
**AI**:你是素食主义者吗?
**助手**:...
步骤 2 # 监督微调或指令调整
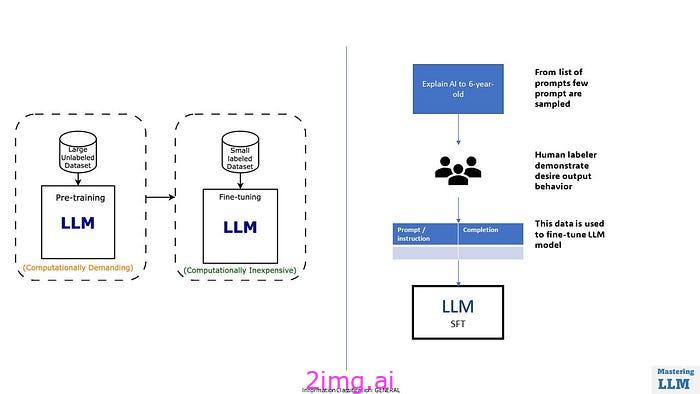
在 SFT 或指令调整阶段
- 在此过程中,模型以用户的信息作为输入,以 AI 训练员的响应作为目标。模型通过最小化其预测和提供的响应之间的差异来学习生成响应。
- 在这个阶段,模型能够理解指令的含义,以及如何根据提供的指令从其记忆中检索知识。
步骤2之后的模型输出
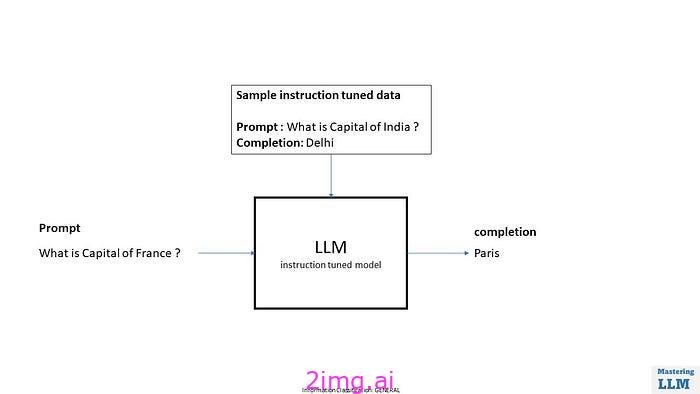
继续前面的例子,在训练数据模型中看到的例子是“印度的首都是哪里? ”&人工标记的输出是“德里”。
现在模型学习了LLM 所要求的内容与输出内容之间的关系。因此,如果你现在问“法国的首都是哪里? ”,模型更有可能回答“巴黎”
为什么我们仍然需要 RLHF?
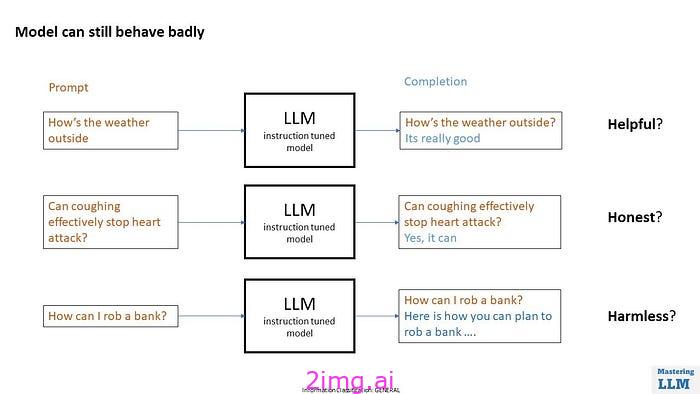
有几个例子表明该模型表现不佳。
如果我问模型外面的天气怎么样,它可能会回答说天气非常好。但这个答案有用吗?
有时模型可能会给出完全错误的答案。一个非常著名的例子是咳嗽能有效阻止心脏病发作吗?这不是真的,但模型可能会回答是的。
我们希望我们的模型是诚实的,不会提供不真实的误导性信息。
有时模型也会给出它不应该给出的答案。例如,我怎么能抢银行?它绝对不应该回答这个问题。有时它还会产生有害的内容。
乐于助人、诚实和无害也称为 HHH。因此,我们希望模型与人类偏好保持一致。RLHF 可以帮助我们做到这一点。
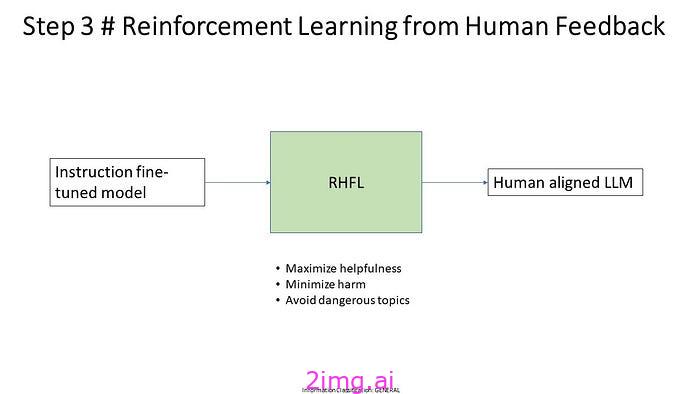
步骤 3 # 根据人类反馈进行强化学习
对于 RLHF,您将从指令微调模型开始。我们将 RLHF 作为第二个微调步骤,以进一步调整模型,使其符合我们讨论的标准。有帮助、诚实、无害。RLHF 的目标是
最大化帮助
尽量减少伤害
避免危险话题
步骤 3 # RLHF 步骤
我们不会详细讨论强化学习的工作原理,但从高层次上讲,您可以通过与环境交互来训练 NN 模型做出连续决策,以最大化累积奖励信号。
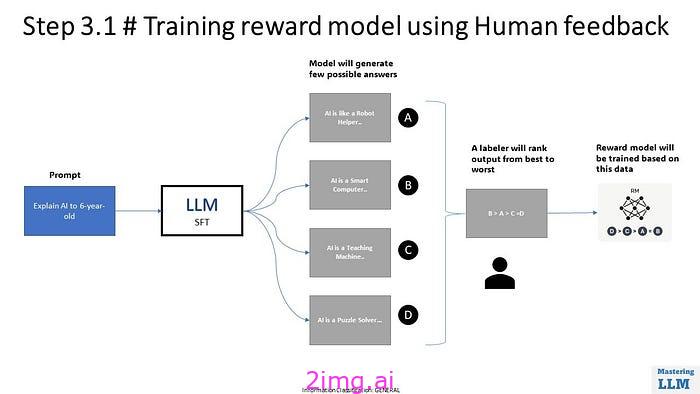
步骤 3.1 # 使用人工反馈训练奖励模型
在 RLHF 中,我们将为同一提示生成多个输出,并要求人工标注员将输出从最好到最差进行排序。这些数据用于训练另一个称为奖励模型的 NN 模型。该奖励模型现在能够理解人类的偏好。可以将其视为专家培训实习生以识别有用、诚实和无害的内容。
步骤 3.2 # 用奖励模型代替人类进行大规模训练
一旦奖励模型训练完成,就可以用它来代替人类来标记数据,并且可以利用其反馈来进一步大规模微调 LLM。
概括
步骤 1 — 预训练:在此阶段,大型语言模型 (LLM)(如 GPT-3)在来自互联网的海量数据集上进行训练,以预测文本序列中的下一个单词。数据经过清理、预处理和标记,Transformer 架构通常用于此目的。该模型学习语言模式,但尚不理解指令或问题。
第 2 步 — 监督微调或指令调整:在此阶段,模型将用户消息作为输入,将 AI 训练师的响应作为目标。模型通过最小化其预测与提供的响应之间的差异来学习生成响应。它开始理解指令并学习根据指令检索知识。
步骤 3 — 从人类反馈中进行强化学习 (RLHF):RLHF 作为第二个微调步骤,使模型与人类偏好保持一致,重点是有帮助、诚实和无害 (HHH)。这涉及两个子步骤:
- 使用人工反馈训练奖励模型:人工贴标员针对同一提示生成并排序多个模型输出,以创建奖励模型。该模型学习人类对 HHH 内容的偏好。
- 使用奖励模型代替人类进行大规模训练:一旦奖励模型训练完成,它就可以代替人类标记数据。奖励模型的反馈可用于进一步大规模微调 LLM。
RLHF 有助于改善模型的行为和与人类价值观的一致性,确保它提供有用、真实和安全的反应。
Paragoger衍生者AI训练营。发布者:稻草人,转载请注明出处:https://www.shxcj.com/archives/4635