
缓存生成变压器的键(K)和值(V)状态已经存在了一段时间,但也许您需要了解它到底是什么,以及它提供的巨大的推理加速。
Key 和 Value 状态用于计算缩放的点积注意力,如下图所示。


KV 缓存发生在多个 token 生成步骤中,并且仅发生在解码器中(即,在 GPT 等仅解码器模型中,或在 T5 等编码器-解码器模型的解码器部分中)。BERT 等模型不是生成式的,因此没有 KV 缓存。
解码器以自回归方式工作,如本 GPT-2 文本生成示例所示。
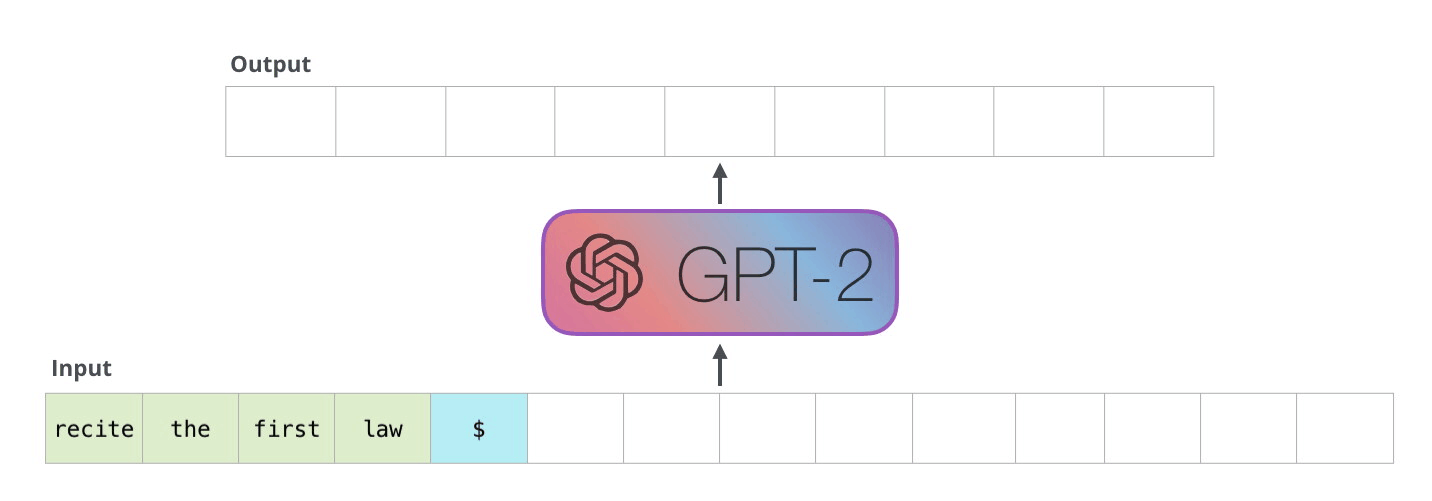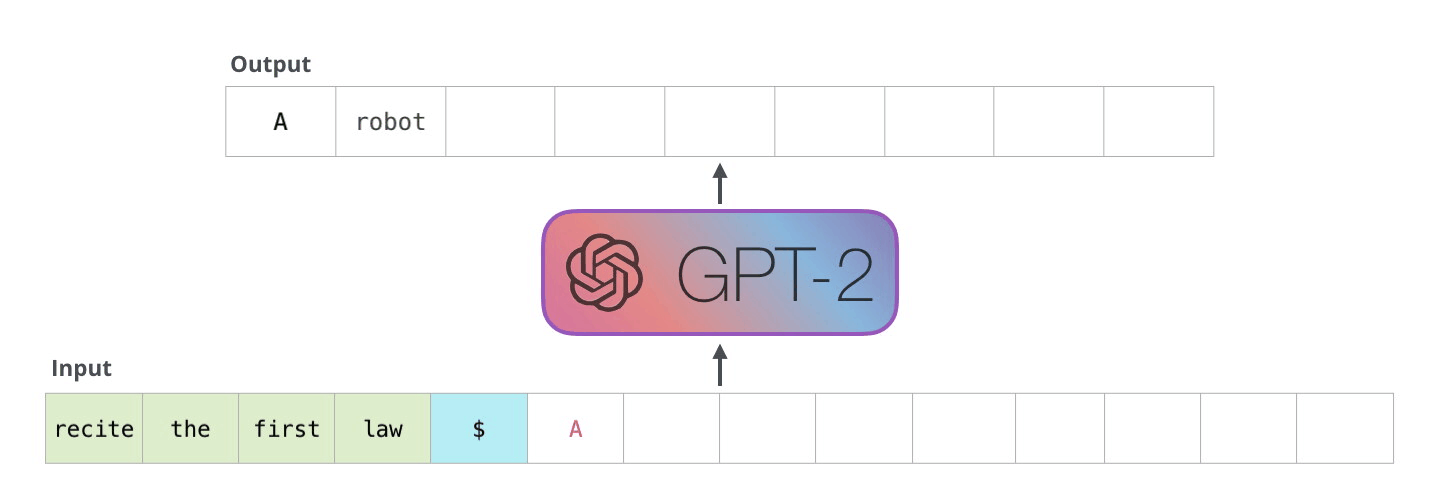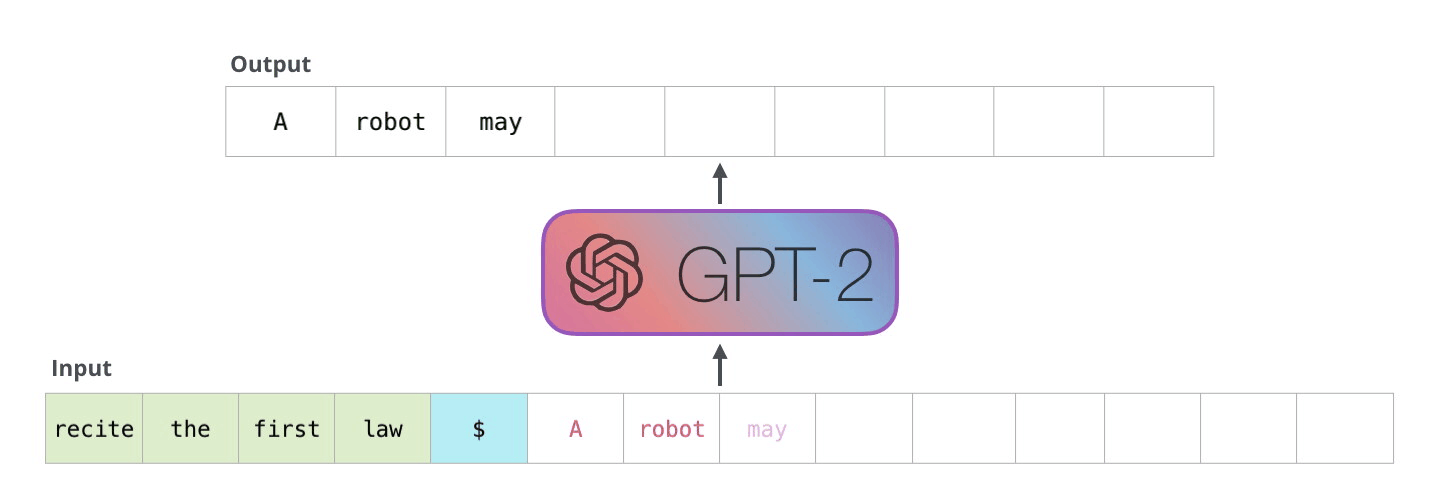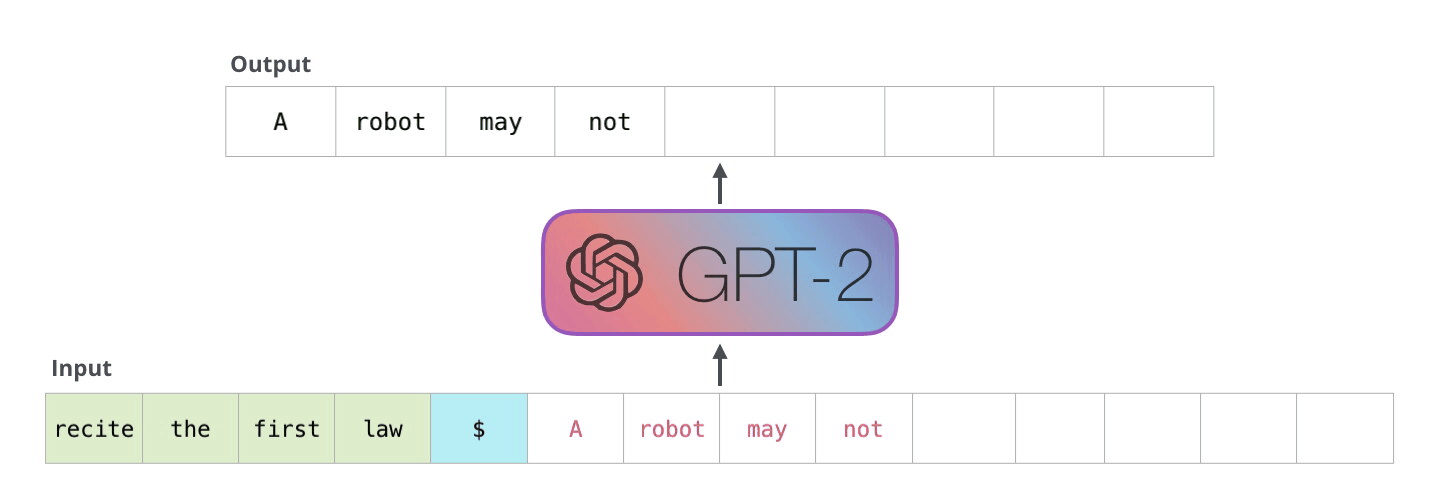
这种自回归行为重复了一些操作,我们可以通过放大在解码器中计算的掩蔽缩放点积注意力计算来更好地理解这一点。

由于解码器是因果的(即,一个标记的注意力仅取决于其前面的标记),因此在每个生成步骤中,我们都在重新计算相同的先前标记的注意力,而实际上我们只是想计算新标记的注意力。
这就是 KV 发挥作用的地方。通过缓存以前的 Keys 和 Values,我们可以专注于计算新 token 的注意力。

为什么这种优化很重要?如上图所示,使用 KV 缓存获得的矩阵要小得多,从而可以加快矩阵乘法的速度。唯一的缺点是它需要更多的 GPU VRAM(如果不使用 GPU,则需要 CPU RAM)来缓存 Key 和 Value 状态。
让我们使用transformers 🤗来比较有和没有 KV 缓存的 GPT-2 的生成速度。
import numpy as np
import time
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
device = "cuda" if torch.cuda.is_available() else "cpu"
tokenizer = AutoTokenizer.from_pretrained("gpt2")
model = AutoModelForCausalLM.from_pretrained("gpt2").to(device)
for use_cache in (True, False):
times = []
for _ in range(10): # measuring 10 generations
start = time.time()
model.generate(**tokenizer("What is KV caching?", return_tensors="pt").to(device), use_cache=use_cache, max_new_tokens=1000)
times.append(time.time() - start)
print(f"{'with' if use_cache else 'without'} KV caching: {round(np.mean(times), 3)} +- {round(np.std(times), 3)} seconds")在 Google Colab 笔记本上,使用 Tesla T4 GPU,生成 1000 个新令牌的报告平均时间和标准差时间如下:
使用 KV 缓存:11.885 +- 0.272 秒,不使用 KV 缓存:56.197 +- 1.855 秒
正如这里所报告的,推理速度的差异很大,而 GPU VRAM 的使用率可以忽略不计,因此请确保在您的 Transformer 模型中使用 KV 缓存!
值得庆幸的是,这是transformer中的默认行为🤗
RA/SD 衍生者AI训练营。发布者:稻草人,转载请注明出处:https://www.shxcj.com/archives/4528