


当你看到谷歌刚刚取得的成就时,就不会奇怪 OpenAI 在几个小时后突然发布了 Sora,以转移人们的注意力,让人们忽视他们在大型语言模型 (LLM) 领域不再领先的事实。
谷歌的Gemini 1.5 Pro在多模态大型语言模型 (MLLM) 方面实现了一代人的飞跃,就像 2023 年 3 月的 GPT-4 对 LLM 一样。
具体来说,它一次可以处理数百万个单词、40 分钟长的视频或在几秒钟内处理 11 小时的音频,并且上下文检索准确率高达 99%,这在该领域是前所未有的。
长序列时代已经到来,随之而来的是一个新的主导者首次俯视着OpenAI。
这一见解和其他见解大多之前已在我的每周时事通讯TheTechOasis上分享过。
如果您想了解人工智能的狂热世界,同时又受到启发采取行动,或者至少为我们未来做好充分准备,那么这本书适合您。
国王重夺王位
2022 年 11 月,十多年来人工智能行业无可争议的王者谷歌,看到一家至少对公众来说并不知名的微软支持的公司OpenAI,推出了一款产品ChatGPT,彻底改变了叙事,并将其推到了亚军的位置。
萨姆,谷歌总部最令人讨厌的人
人工智能突然成为最重要的技术,但与此同时,谷歌不再被视为该领域的前沿。
Sam Altman 发布了全球迄今为止最强大的法学硕士 (LLM) ChatGPT。
与此同时,谷歌也没有什么可以提供的。当然,他们在山景城总部内部开展了一些项目,比如LAMDA,但远不及 ChatGPT 的质量和生产准备程度。
最痛苦的部分是什么?
ChatGPT 基于 Transformer,该架构是由谷歌研究人员于 2017 年创建的,当时令许多谷歌股东感到沮丧。
换句话说,谷歌就好像一直无所作为,而下一次技术飞跃的“秘密武器”却藏在布满灰尘的橱柜里。
不可饶恕。
谷歌自然收到了这份备忘录并开始采取行动。
条条大路通双子座
不久之后,谷歌发布了Bard,与 2023 年 3 月发布的 ChatGPT 背后的 OpenAI GPT-4 模型相比,这简直是一场彻底的灾难。
如今,谷歌看起来比以前更加落后了。
然后,在 2023 年底,谷歌终于发布了 Gemini 1.0,这是一系列原生多模态 LLM,原生多模态意味着它们从头开始接受训练以处理视频、图像和文本,同时还能够生成文本、代码和图像,如果我们考虑Gemini 1.0 Ultra,这是最强大的模型,这使这家搜索公司至少达到了 OpenAI 的 GPT-4 的水平。
然而,如果我们考虑时间的话,这根本就没有什么特殊的。
最终,Gemini 于去年 11 月左右发布,刚好能够与 OpenAI 于 3 月份发布的产品进行竞争。
毫不奇怪,为了避免遭到业界的蔑视,他们同时迅速发布了Alphacode 2 ,这是一个革命性的模型,将 Gemini 与搜索算法和测试时间计算相结合,使人工智能能够在竞技编程的高级水平上竞争,并获得了惊人的 85% 的百分位数。
什么是测试时间计算?
测试时间计算意味着,为了最大限度地提高正确答案的机会,Alphacode 2 在运行时会对任何给定的问题生成多达一百万个可能的答案,并使用搜索和过滤算法来获得最佳答案和回应。
与法学硕士 (LLM) 提供的“系统 1”基本响应不同,模型会“探索”各种可能性,直到找到最佳选择,就像人类所做的那样。
被铃声拯救了。
但现在,谷歌终于凭借Gemini 1.5真正“大获成功” ,以至于 OpenAI 被迫在之后立即发布Sora,因为谷歌凭借整体和长序列性能方面的跨代飞跃重新夺回了 AI 王座。
双子座,长程超级模型
简而言之,Gemini 1.5令人印象深刻。
尽管我们只有中型 Pro 型号的结果,这可能表明更好的型号即将推出,但分数令人难以置信。
提醒: Gemini 家族分为三组,从较小(因此较差)到较大(因此最好),Nano、Pro 和 Ultra。
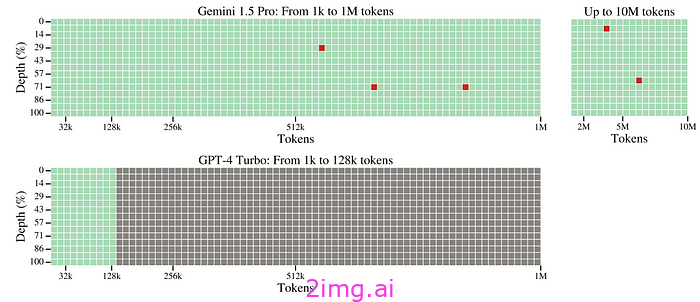
首先,它具有人类已知的最长的计算和性能优化上下文窗口,多达 1000 万个标记。
但是什么是令牌以及什么是上下文窗口?
标记是 Transformers 用来处理和生成数据的单位。对于文本,它们通常为 3 到 4 个字符。例如,虽然这取决于您使用的标记生成器(将文本划分为标记的模型),但“London”可以划分为“Lon”和“don”标记。
另一方面,上下文窗口是 LLM 在任何给定时间内可以处理的最大标记数量。它是实时内存,类似于计算机处理器中的随机存取存储器 (RAM)。
上下文窗口存在的原因很简单,长序列成本高昂且难以建模。
具体来说,运行 LLM 的成本相对于序列长度具有二次复杂度。通俗地说,如果你将给定的序列长度加倍,成本就会翻四倍。
此外,当处理比训练时间更长的序列时,Transformer 的性能会大大下降。
这个问题被称为外推(尽管其他设计特征,如选择正确的位置嵌入也会被考虑进去,但这是另一个话题了)。
想象一下,如果你训练自己每天跑 5 英里,突然有一天你意外地跑了 15 英里。自然,额外的 10 英里会更加困难,你的表现也会更差。
但是,要了解 Google 的上下文窗口增加的大小,1000 万个标记是多少?
那是:
- 大约 750 万字,或约 15,000 页 500 字的页面,远远超过了整个哈利波特传奇。
- 44 分钟的无声视频
- 6-8 分钟的标准帧 YouTube 视频
一气呵成。
作为参考,目前该方面的领先者是 Claude 2.1,其 token 数量高达 200,000。这相当于约 150,000 个单词,比 Gemini 1.5 少 50 倍。
不仅如此,他们还在从极长的序列中恢复特定的一次性事实时实现了 99% 的检索准确率,如下图所示(他们忍不住在这个过程中让 ChatGPT 汗颜):
另一个令人惊叹的结果是,该模型仅通过少量文档就学会了卡拉曼语(Kalamang) ,这是最稀有的语言之一,尽管两者都具有相同的信息,但其表现几乎与人类相当。
在此过程中,他们彻底摧毁了其他用于完成这一任务的前沿模型:
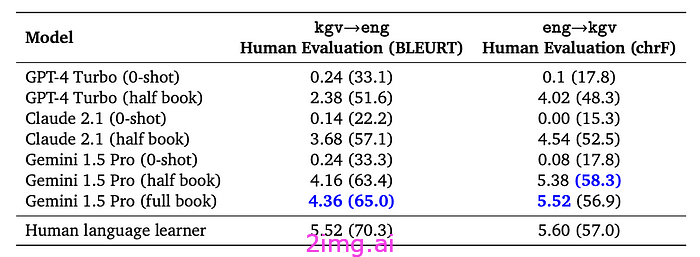
这一壮举不容小觑,因为这意味着人工智能在学习效率方面正在慢慢变得“和人类一样好”。
但真正的问题是,他们是如何做到这一点的?
专家加冕
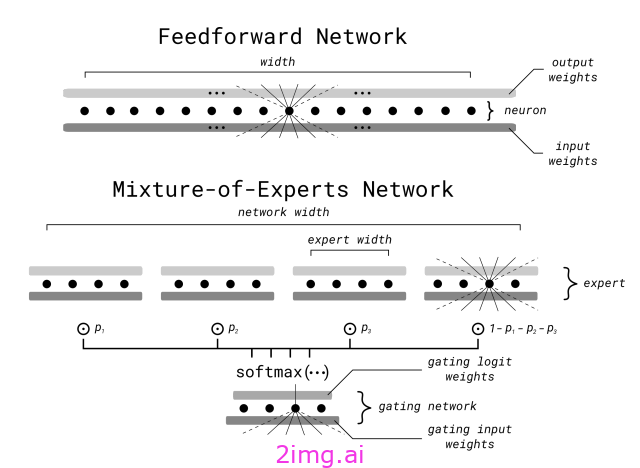
在技术报告中,谷歌将其成功主要归功于 Gemini 1.5 采用 Mixture-of-Experts (MoE) 作为其成功的主要架构驱动。
分而治之
MoE 是一种相对知名的技术,如今已成为一种标准,例如 Gemini 1.5、Mixtral-8x7B 或 GPT-4(或多或少已证实的传言)。
其原理很简单。
您不需要拥有一个大型的专家模型,而是组建一组专门针对输入的某些区域的小型专家模型。
但是我们所说的输入区域化是什么意思呢?
神经网络背后的秘密在于,它们能够近似(学习)输入和输出之间的非常复杂的映射。就语言而言,这意味着它们能够根据前面的单词仔细映射序列中的下一个单词。
输入空间,即所有可能输入的空间(您可以发送给 ChatGPT 的所有可能的文本序列)是巨大的,但神经网络实际上能够创建一个函数或映射来“分解”这个空间,这样,无论序列的特殊性如何,它仍然可以准确地预测,无论输入序列多么不常见。
但是是什么让 MoE 如此优秀呢?
很简单,你不需要强迫模型学习所有可能输入到所有可能输出的全局映射,而是创建“专家”,即专注于特定输入区域的小型神经网络。
例如,一位专家可以熟悉欧洲城市,而另一位专家可以成为格陵兰动物群的专家。
实际上,由于专家数量有限,这些专家仍然是多方面的,并且精通数千种不同的输入主题,但他们结合起来比只有一位全球专家的特异性要高得多。
以Mixtral-8x7B Mistral 的 MoE 模型为例,该模型被分为 8 位专家。因此,对于任何给定的输入,都会选择 2 位专家做出响应,而其余专家则保持沉默。
因此,MoE 是两全其美的,因为:
- 你仍然可以训练一个庞大的神经网络,这是创建良好 MLLM 的基本要素
- 在推理时,只有一小部分网络运行,从而节省成本并减少延迟
如果你有兴趣了解如何做到这一点,请查看Mistral 的论文。
简而言之,MoE 的工作原理是将 Transformer 中必不可少的前馈层分成几组,并在前面设置一个门。这个门通常是一个按概率顺序对专家进行分类的 softmax 函数,它决定哪些专家参与了每个输入,激活这些专家并抑制其他专家。
然而,MoE 架构并没有解释他们如何实现经济实惠且性能卓越的长序列建模。
他们没有解释如何做到这一点,但我们可能确实知道。
缓存压缩
如前所述,处理长序列的问题之一是成本巨大,而降低成本的最佳方法之一是通过量化。
量化会降低模型参数的精度以节省内存。例如,对于 500 亿个参数的 float32 精度模型(每个参数 32 位,即 4 字节),您的权重文件占用 200 GB,仅托管该模型就需要至少 3 个最先进的 80GB GPU 。
在 Transformers 中,每次预测都要运行整个模型,因此需要将其存储在 RAM 中。Apple的Flash LLM等一些技术可以帮助将模型的某些部分存储在闪存中。
但是如果我们将参数精度降低到 4 位,这意味着我们的模型现在占用 25 GB(从 32 到 4),这意味着您可以在一个 GPU 中高效地运行该模型。
但是对于长序列,会出现另一个问题,即KV 缓存。
Transformer 基于注意力机制,这是一个计算密集型系统,对于 Gemini 或 ChatGPT 处理语言至关重要。
幸运的是,在下一个单词预测任务中,此过程中进行的计算非常冗余。因此,这些冗余计算被缓存到内存中,避免整个过程变得过于昂贵。
然而,正如斯坦福研究人员在最近的一篇论文中所解释的那样,在这种情况下,KV 缓存是主要的内存瓶颈:
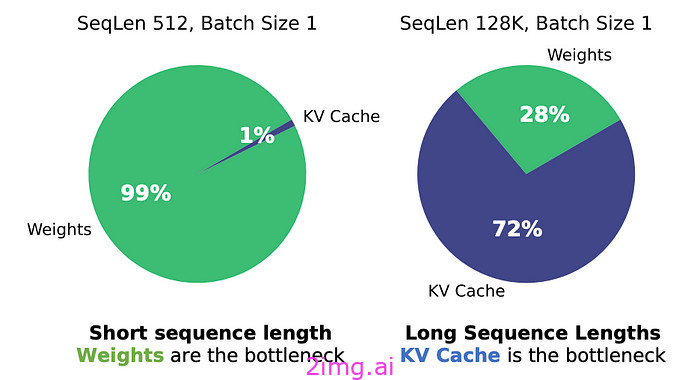
因此,这些研究人员所做的就是实现了第一个高性能的KV缓存量化。换句话说,不仅可以以较低的精度存储模型的权重,而且缓存也可以。
这使得仅在一个 GPU 中就可以运行百万个令牌序列,这是闻所未闻的。
考虑到时间因素,我敢打赌,谷歌一定使用了类似的方法或取得了类似的突破来解释 Gemini 1.5 的结果。
一些人怀疑谷歌还引入了一种计算强度较低的注意力机制变体,尽管这一点尚未得到证实。
Transformers的伟大胜利
总而言之,谷歌在 Gemini 1.5 上的突破不容低估。
事实上,这一步功能的改进清楚地预示着即将到来的人工智能伴侣。
很快,人类将拥有一个可以绝对准确地记住数月(甚至数年)对话的模型。
这个榜样总是愿意倾听,总是愿意提供帮助,总是记住您的想法、问题和顾虑。
真正的数字朋友。
这看起来似乎是一件坏事,但我最终觉得,有些人,那些处在越来越孤独的时代的人们,需要有人或“某物”来交谈,并愿意随时倾听。
然而,当人类决定只与人工智能对话时,这是否会反过来使人类越来越疏远呢?也许,这会让事情变得更糟。
那您呢,这让您有何感受?
RA/SD 衍生者AI训练营。发布者:稻草人,转载请注明出处:https://www.shxcj.com/archives/4425