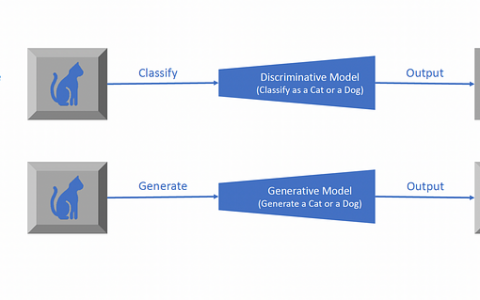
当前的语言模型不仅受到标记数据数量的限制,还受到标记数据质量的限制。在我们之前的博客中,我们讨论了DPO,这是一种比 RLHF 更稳定、更高效的模型优化方法。问题是 DPO 要求您拥有大量标记的人类偏好数据才能训练模型。本文介绍了可以同时执行以下两项操作的代理:充当指令遵循模型,根据提示生成响应,以及生成和评估新的指令遵循示例以添加到自己的训练集中。
因此,事不宜迟,让我们立即开始吧。

目录
- 大语言模型(LLM) 培养流程概述
- 标记数据的问题
- 自我奖励语言模型
- 结果与结论
大语言模型 (LLM) 培养流程概述
在了解 Self-Reward 之前,我们应该快速了解一下 LLM 培训流程。以下是不同的步骤:
步骤 1:预训练
- 数据收集和多样性:从互联网收集大量数据集,确保文本来源的广泛性。数据的多样性对于模型理解各种语言风格、主题和细微差别至关重要。
- 数据清理和预处理:这涉及删除不相关的内容、格式问题和噪音。这是一个微妙的过程,因为它需要在清理数据和保留有意义的上下文之间取得平衡。
- 标记化:使用字节对编码或 WordPiece 等技术将文本分解为可管理的单元(单词、子单词)。此步骤对于处理语言的细微差别(包括形态和语法)至关重要。
- 使用 Transformer 架构:之所以选择 Transformer,是因为其能有效地处理顺序数据,并且能够捕获文本中的长程依赖关系。
- 训练下一个单词预测:训练模型预测序列中的下一个单词。此步骤是模型学习语言结构和生成连贯文本的基础。但是,在此阶段,模型缺乏深入理解上下文或用户意图的能力。
步骤 1 之后的输出:
- 该模型可以生成文本,但可能会产生与上下文无关或不适当输出,因为它尚未学习特定的用户交互模式或指令。
第 2 步:监督微调/指令调整
- 从有针对性的输入和响应中学习:现在使用成对的用户输入和适当的响应来训练模型。这种训练对于模型学习响应的上下文和相关性至关重要。
- 理解指令和知识检索:模型开始理解指令的含义,并学习如何有效地检索和利用其预先训练的知识。
第 2 步后的输出:
- 该模型现在可以更准确地理解和回答问题。它开始在问题和适合上下文的回答之间建立联系。
步骤 3:通过人类反馈进行强化学习(RHFL)
- 符合人类偏好(乐于助人、诚实、无害):这里的重点是完善模型的输出,使其符合道德和实际的人类标准,包括乐于助人、诚实和无害。
- 使用人工反馈训练奖励模型:针对同一提示生成多个输出,然后人工标记员对其进行排序。此排序数据训练另一个神经网络,即奖励模型,该模型可了解人类对内容的偏好。
- 用奖励模型代替人类以实现可扩展性:奖励模型一旦经过训练,就会接管人类提供反馈的角色,从而实现对 LLM 进行大规模、高效的微调。
RHFL 的目的:
- 此阶段对于改进模型的行为至关重要。它确保模型不仅提供准确且相关的响应,而且还以符合人类价值观的方式提供响应,避免误导、有害或危险的内容。
总之:
- 预先训练为理解语言奠定基础。
- 监督微调/指令调整教导模型对特定指令做出适当的反应。
- RHFL 将模型的响应与道德和以人为本的标准相结合,增强了其在实际应用中的可靠性和安全性。

标记数据的问题
那么,我们的想法是,我们可以使用合成数据来训练我们的语言模型吗?首先,这看起来有点违反直觉,如果 LLM 将要生成的数据已经以某种方式来自互联网上的数据,那么它有什么帮助呢?如果在 LLM 的相关过程中,它学习数据分布,然后使用相同的分布来生成数据,我们还能得到什么?这是一个完全合理的问题。从理论上讲,自我改进的语言模型不应该起作用,但我们开始看到合成数据在新论文和即将发表的论文中成为一种成功的技术。
最简单的思考方式是,鉴于这些模型本质上已经接触了互联网上可用的大量分布(整个互联网),因此重点转向战略性地影响模型的输出。这不仅涉及扩大模型的曝光度,还涉及以与期望结果相符的特定方式引导其响应。区别至关重要:拥有一个理论上能够生成任何响应的模型是一个方面,但引导它产生特定的、有针对性的响应是一个更加微妙的挑战。
能够让模型生成自己的合成数据,感觉更像是技能的调整或磨练,而不是学习新东西。
那么,让我们牢记这个问题:语言模型能否创建全新的文本,为庞大的知识库添砖加瓦?还是它只会充斥着我们已经知道的想法,只是经过过滤和重新表述?这是一个有趣的思想实验,在我们深入研究时最好将其牢记在心。
自我奖励语言模型

首先,我们从一组提示开始。然后,我们为监督微调 (SFT) 模型植入两种技能:
- 生成响应
- 评估回应。
然后我们使用 SFT 模型生成提示和响应以及排序偏好对形式的数据。每个提示都有多个可能的完成方式,因此我们需要生成多个响应,然后使用同一模型对哪个响应更好进行排序。
他们使用巧妙的“LLM-as-a-Judge”提示来帮助生成和过滤重新添加到训练数据集中的数据,从而在正反馈循环中改进模型。
遵循指令
我希望您熟悉监督微调,以使您的模型遵循指令并与偏好对保持一致。
将指令或系统消息与用户提示分开是很好的,这样我们就可以定制用户体验或开发人员输出。例如,我们还可以有一条指令说“总是像海盗一样回应”,现在每个回应都有一点幽默,如果这就是我们想要的。
对于自我奖励语言模型,我们希望我们的模型遵循指令来生成新数据并反馈到模型中。
大语言模型法官专业
让模型遵循指令后,第二步是让模型与人类偏好保持一致。由于每个提示都有多个有效答案,因此了解我们更喜欢哪些答案会将语言模型从遵循机器指令的基本模型转变为更强大、更一致的模型。事实证明,DPO 或 RLHF 等技术比简单的指令微调更能改进语言模型。
在这种情况下,第二个偏好优化步骤使用相同的 LLM 作为其自身输出的判断者。例如,我们可能有一个句子的开头有两个有效的完成,其中一个比另一个更正确。
x:钢铁侠是…… 👍有史以来
最好的 MCU角色 ,因为他的角色弧线从自我痴迷到牺牲自己的生命👎 一个好角色
我们希望模型生成第一个完成的句子,而不是第二个,所以我们会给它更高的排名。我们可以让人类标记这些由模型生成的句子对,但这既耗时又费钱。如果语言模型可以判断自己的输出并给出质量分数,那么我们就可以在自我改进的循环中反馈数据。
以法官身份提示

这个提示对于整个流程的顺利运行至关重要。在结果部分的后面,他们引用了其他已经尝试过的提示,与人类相比,这些提示的配对准确率只有 26%,而这个特定的提示的起点是 65.1%。
这并不是第一次提出使用 LLM 作为评判者的方法。论文“使用 MT-Bench 和 Chatbot Arena 评判 LLM 作为评判者”研究了 LLM 如何评判其他 LLM 的输出,其结果是:
像 GPT-4 这样的强大 LLM 评判者可以很好地匹配受控和众包的人类偏好,实现超过 80% 的一致性,与人类之间的一致性水平相同。
这篇论文的有趣之处在于,最初的 LLM 学会了自己做评判者。他们没有使用 GPT-4 等单独的、更智能的语言模型作为评判者。因此,基础模型不仅在遵循指令方面变得更好,而且在判断自己的输出方面也变得更好。这意味着,随着我们迭代训练,每次我们训练一个新模型时,我们都会拥有比上一次迭代更高质量的偏好数据集。
这里需要注意几个关键事项:
- 初始模型已经需要能够生成合理的响应才能实现这一点
- 奖励提示必须对输出进行良好的评分,以启动反馈循环
如果我们不满足这两个条件,我们就会产生垃圾、对垃圾进行排名,并将垃圾反馈到模型中。
然后,模型本身可以通过以下方式修改自己的训练集:
- 生成新的提示,给出一些显示提示
- 针对每个提示生成 N 个候选答案
- 评估每个候选人的回答,使用相同指导调整模型的 LLM-as-a-judge 技能来评估其自己的回答
结果与结论
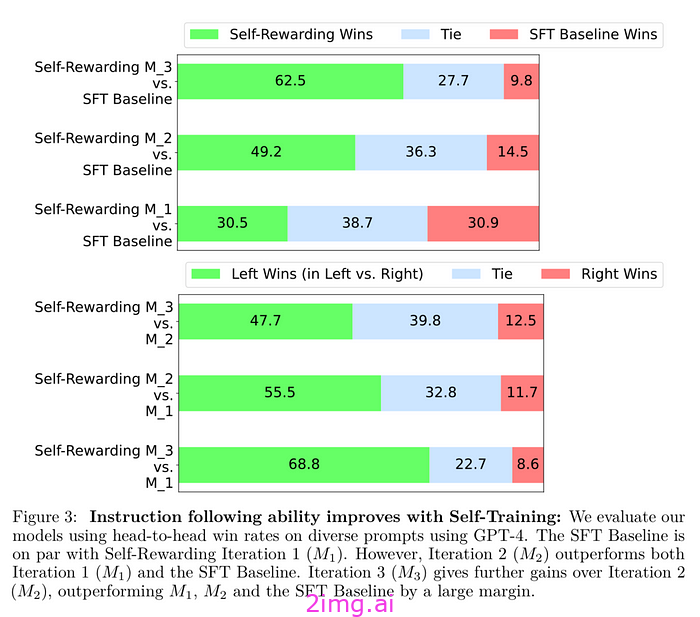
他们表明,使用 EFT+IFT 数据的第一次迭代 M1 并没有比 IFT 数据好太多(30.5 vs 30.9)。他们说这很好,因为这意味着添加自我奖励技能不会影响指令遵循技能。
然后他们表明,第二次迭代 M2 在迭代 1 之后提供了更出色的指令。添加这个新的 AIFT(M1) 偏好数据有助于提高性能,这很有希望。当使用 GPT-4 进行评估时,迭代 3 也比迭代 2 有所改进。
它不仅战胜了基线,而且根据 GPT-4 的评估,每次迭代都开始获得比 GPT-4 Turbo 更高的胜率。

这令人兴奋,因为这里排行榜上的一些模型(Claude 2、Gemini Pro、GPT4 0314)通常包含大型数据集,有时超过 100 万条注释,或使用从更强大的模型中提炼的目标来生成数据集。自我改进技术从小得多的数据集开始,不使用任何外部模型来生成或对响应进行排名。
总体而言,这篇论文很有趣,因为所需的数据集很大。他们从几千个示例开始,并能胜过使用这种迭代过程训练了数百万个示例的模型。他们看到随着时间的推移,性能不断提高,而无需任何人参与,这一事实也令人鼓舞。这个虚拟循环在这个小环境中很有前景,但这只是一项初步研究。
有几件有趣的事情值得一看:
- 这种方法什么时候停止改进?为什么他们只停留在 3 步?
- 这种方法适用于较小(7B)的模型吗?
- 在 LLM 评委阶段,我们可以使用哪些其他提示来引导模型朝不同的方向发展?这对安全性和性能都有影响。
Paragoger衍生者AI训练营。发布者:稻草人,转载请注明出处:https://www.shxcj.com/archives/4408