


在人工智能和机器学习领域的所有流行语中,似乎没有一个能像神经网络那样具有“酷炫因素” 。
这在很大程度上是因为科幻世界一有机会就借用这个词来描述无数电影和电视节目中超级先进机器人和仿生人的内部工作原理。谁不记得《终结者 2:审判日》中阿诺德饰演的终结者与康纳一家之间的这段对话呢:
约翰·康纳:
你能学习一些你没有被编程的东西,这样你就能……你知道,更像人类吗?而不是一直这么呆头呆脑?
终结者:
我的 CPU 是一个神经网络处理器;一台学习型计算机。但当我们单独被派出去时,天网会将开关预设为只读。
莎拉·康纳:
不想让你想太多,是吧?
终结者:
不。

或者可能是因为神经网络的概念似乎模糊了机器世界和人脑世界之间通常僵硬的界限。这些打破人机界限的想法总能让我们着迷或兴奋。
当今神经网络概念的存在,完全是受到人类大脑本身的启发。
从大脑到字节
“我认为大脑本质上是一台计算机,意识就像一个计算机程序。”——斯蒂芬·霍金
早在 1943 年——第二次世界大战正酣、苏联在斯大林格勒战役中战胜了纳粹德国的一年——神经生理学家沃伦·S·麦卡洛克和认知心理学家沃尔特·H·皮特撰写了一篇论文,试图用抽象的数学术语来描述大脑的工作原理。

这篇论文的标题是“神经活动中内在思想的逻辑演算”(不,我也不会因为这些朗朗上口的标题而加分),其中的见解之一就是提出了对大脑中神经元的简化看法,将它们更多地视为根据输入触发或不触发的简单逻辑门。
很容易看出,将大脑的运作方式转化为抽象数学这一想法自然会推动机器学习的发展。大脑被转化为数学,数学通过编程语言被转化为计算机代码。
神经网络的概念以及随后多年的创新 – 从50 年代弗兰克·罗森布拉特(Frank Rosenblatt)的模式识别感知器和 70 年代反向传播的引入,到 2010 年代基于 GPU 的深度学习的出现 – 已经将我们带入了一个人工神经网络 (ANN) 及其在机器学习中的作用 – 简而言之 – 无处不在的世界。
神经网络在实践中与其他形式的机器学习类似,其目标是输入数据并提取模式或根据该数据进行预测。预测房价就是一个经典用例。您可以输入有关面积、卧室数量和地块大小的数据,然后输出数据集中房屋的预测价格。
神经网络将从训练数据中学习如何最好地做出这些预测,最终学习到足够的知识以做出具有合理准确性的预测。

但这些神经网络到底是什么?人工神经元又是什么?它们如何解决这些机器学习用例?
您可以在网络上的其他地方找到许多复杂且数学性很强的答案来回答这些问题。我们在这里要做的是以初学者友好的方式探索这些概念。这意味着初学者友好的语言和初学者友好的代码。
你不会成为机器学习忍者,但你一定能够自信地想象神经网络如何应用于人工智能,甚至可以通过代码进行一些实验。
考虑到这一点,让我们开始吧!
基础
人工神经网络的核心是神经元的概念,因此这似乎是我们开始旅程的最佳地点。下面是一张很棒的图片,左侧显示了有机神经元的结构,右侧显示了人工神经元的结构:
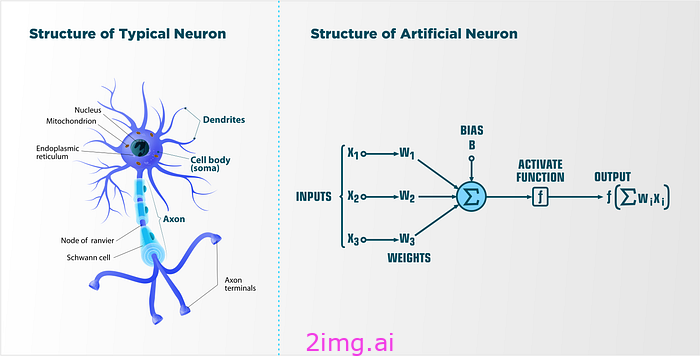
在生物神经元中,树突(细胞体周围的那些小卷须状物体)可以被认为是“输入”,而轴突可以被认为是输出。
不过,我们对探索人工神经元很感兴趣,所以让我们把注意力集中在右边的图像上。它看起来超级吓人——对吧?或者我第一次看到它的时候确实如此。字母下面有很多小数字,可能代表数字,更不用说希腊符号了。
这里有数学……
但是,我们可以将这个神经元概念简化到最基本的程度。让我们看看我们是否可以去掉一些(不是全部)令人生畏的字母(你开始意识到高中数学给我留下了终生的伤疤了吗?)。
下面是我们为一个非常简单的神经网络生成的视觉图。它仅由一个“神经元”组成。它是神经网络最简单的表示,通常被称为感知器,这个术语是由深度学习之父Frank Rosenblatt 创造的。
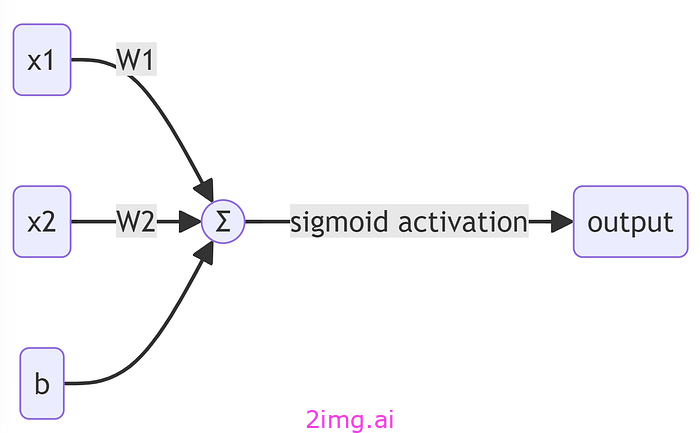
好的,这张图片看起来更容易理解一些。
现在我们知道神经网络是为了学习而设计的,它基于生物神经元,所以我们可以合理地推断我们的神经元需要接受输入(信息)并提供输出。我们已经可以在图片中看到这一点了。左边有一些框——中间是一些东西——右边有一个输出。
让我们从输入开始,它们位于左侧,通常用“x”表示。所以我们有 x1 和 x2。这只是意味着我们的输入是具有 2 个特征的“事物”。例如,我们可以根据甜度和硬度预测一块水果是苹果还是香蕉。
目前,我们的输入是什么并不重要,只是它有 2 个特征。
权重和偏差
如你所见,我们的每个输入特征(x1 和 x2)都有对应的 w 值(w1 和 w2)。这些表示权重。

权重是我们神经元中非常重要的一部分,它们决定了每个输入特征的重要性。这就是为什么每个特征都有一个权重。如果在房价预测示例中,卧室数量比位置更能预测房价,那么训练神经网络后,该特征的权重就会更高。
我之所以提到“训练的结果”,是因为一开始,你的神经网络并不知道哪些特征对于我们的预测最重要,哪些特征不重要。这就是为什么这些权重参数的值一开始都是小的(随机)值。我们的神经网络对输入数据的持续训练使得这些权重能够随着时间的推移而变化(并变得更加准确)。选择这些随机值的方法取决于配置神经网络时使用的方法,但一些常见的例子包括:
- 均匀分布:数字将在一个较小的范围内均匀分布,例如在 -0.05 和 0.05 之间。
- 正态分布:这些值可能是从正态分布(也称为高斯分布)中得出的小数字,其平均值为 0,标准差较小,如 0.01。
现在,我们假设 w1 和 w2 中有一个数字在训练之前并不是特别有用,但随着训练会变得更有用。
顺便说一句——我们说的“训练”是什么意思?实际上发生了什么?通常,训练机器学习模型需要经过多个时期。一个时期只是一种说法,即“对你提供的所有训练数据进行一次传递”,在我们的例子中,将数据传入神经元并从另一端输出。
在每个时期结束时,参数都会得到更新,这样理想情况下——下一次传递——我们的损失(错误的预测)就会减少,一遍又一遍,直到我们获得良好的预测能力!

如果我们回顾一下我们的简单图表,您会注意到一些标有“ b ”的东西被输入到我们的输入中。b 代表偏差,这是另一个重要的机器学习概念,就像我们的权重一样,它是一个在训练神经网络的过程中发生变化的“参数”。
在我们的简单示例中(以及在许多实际用例中),偏差将在我们进行任何训练之前从 0 开始,但随着我们处理每个时期,偏差可能会更新。但会更新到什么?为什么?
好吧,如果你查阅任何关于偏差的特别深入的解释,你可能会得出这样的结论:“偏差项允许激活函数向左或向右移动”。但我们可以让这个解释更简单一点。
每次训练迭代时,我们都会遇到错误,这就是机器学习的本质,也是我们必须一遍又一遍地对相同数据进行训练/学习的原因。我们的目标是随着时间的推移减少这些错误。
偏差(与权重一样)可能会随着每次训练而调整为一个值,该值基本上会从非“中性”位置开始下一次迭代。本质上,您会在下一次训练中引入轻微的偏差(因此得名),该值有助于最初将预测向一个方向或另一个方向移动,目的是帮助最大限度地减少错误。如果您的模型在预测香蕉(用 0 表示)时犯了太多错误,而实际值是苹果(用 1 表示),那么偏差可能会从 0 稍微调整为 1,以协助下一个时期。
哦,是时候解决 Σ
瞧,我尽力了——好吗?我尽量不让希腊字母出现在你和我面前。我充当了盾牌,抵御那些漂浮在数字上或附近的滑稽小符号。
但是时候了。我们必须解决神经元中的“Σ”。不过没关系,我会很温柔的。
幸运的是,这个问题相当简单。希腊字母“Σ”称为Sigma,在数学术语中,它代表求和。基本上就是把东西加起来。所以在我们神经元的这个连接处:
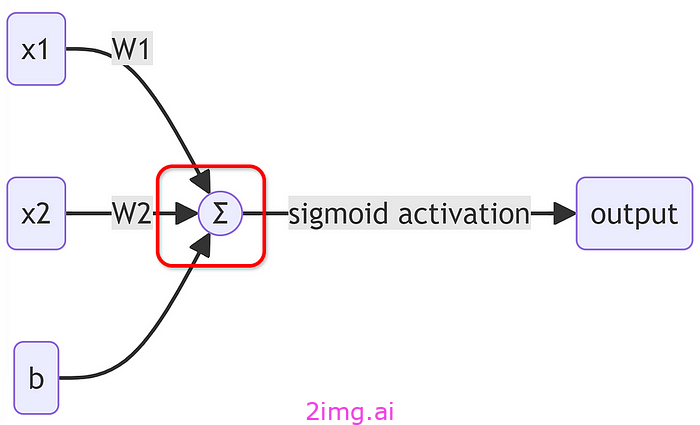
我们正在总结我们的加权输入并添加我们的偏差。
它的计算公式为Σ(Wi * xi) + b,其中 Wi 和 xi 是权重和输入,b 是偏差。用英语来说,我们将每个输入乘以其相应的权重,将它们相加,然后加上偏差。
之后,我们将数据传递给“S 形激活函数”。S 形激活函数(或 S 形函数)也称为“压缩”函数,这是有原因的。完成所有求和和加法运算后,我们可能会得到一些非常大的负值或正值,这些值可能很难解释。
我们的 S 型函数将这个数字“压缩”为 0 到 1 范围内的数字,这为我们提供了一个有意义的数字,这对于我们在这里理论上讨论的机器学习问题类型特别有用:例如确定一个物体是香蕉还是苹果。一个是另一个。这是一个二元分类问题。
然后是时候把这个东西收尾了!输出!这只是获取我们最终的预测值并将其输出!这样就结束了通过我们的神经元的冒险。
看到了吗?这还不算太糟!当然,值得回顾一下我们一开始所说的内容。这是一个非常非常简单的例子。它是一个单神经元神经网络——一个“感知器”。它对于简单的分类问题很有用,但神经网络的真正威力在于你开始添加更多神经元/节点。
当你开始在“层”中添加更多神经元时,它们会获得针对更复杂问题的更强的预测能力:
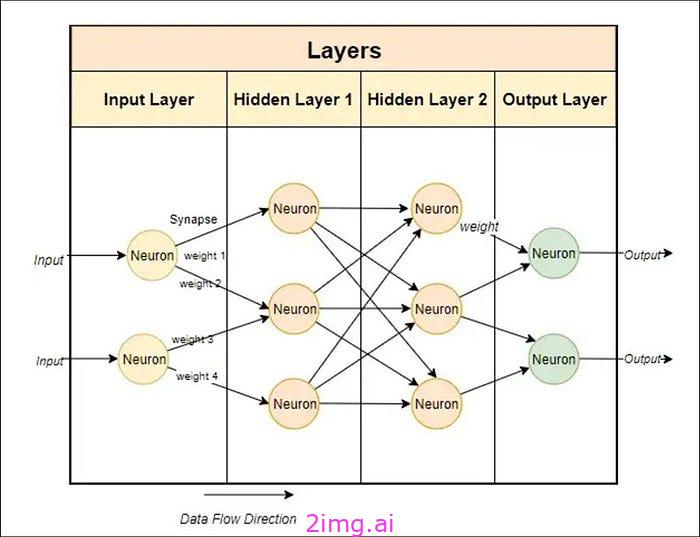
上图中还有很多事情要做。这个神经网络有多个层——除了输入层和输出层外,还有两个隐藏层——每个层内都有多个神经元。除此之外,更复杂的神经网络中的神经元之间存在称为突触的连接,突触具有自己的“权重”,并影响一个神经元的输出如何影响另一个神经元的输入。
人类大脑有 1000 亿个神经元,每个神经元都与 1 万个其他神经元相连。你肩上坐着的是已知宇宙中最复杂的物体。—— Michio Kaku
但深入研究这一切 – 虽然很诱人 – 却远远超出了本文的范围,所以我们将回到单个神经元的例子,让我们用最好、最有趣的部分 – 代码来完善我们的发现!
构建神经元

好的,时间到了!让我们卷起袖子,构建我们的第一个单神经元神经网络。
为此,你需要两样东西:
- 掌握 Python 技能。(没什么难的)
- Jupyter 笔记本环境。有很多选择 — 本地机器/VS Code、Azure Machine Learning Studio、AWS Sagemaker Studio/Lab — 我们将使用Google Colab,因为它免费且非常容易运行。
好的,对于那些已经到达这一步的人来说,我已经整理了一个存储库,您可以使用它来快速掌握知识:
GitHub – kknd4eva/my_first_neuron
通过在 GitHub 上创建账户来为 kknd4eva/my_first_neuron 开发做出贡献。
但是如果您打开 repo 并且发现没有任何意义,请不要担心,我们将检查数据和代码并逐步解决问题,这样代码现在对您来说会更有意义,因为您花了一些时间来了解神经元、神经网络和训练循环的基础知识。
对于我们的实验,我们将使用来自 Kaggle 的合成数据集,其中包含以下内容:
数据的想法是,每一行都是学生在考试 1 和考试 2 中的考试成绩。通过列表示学生是否通过了第 3 次考试。这一列是我们想要使用神经网络进行预测的。我们基本上是试图根据学生在前两次考试中的成绩来预测他或她是否会通过第三次考试。
您可以在存储库中找到文件exam_scores.csv。我们将使用这些数据来训练和测试我们的模型。存储库中唯一的其他内容是我们实际的 Python 笔记本。让我们一步一步地查看它!
首先,我们安装一个笔记本上默认没有的库:
# 1) 添加我们需要但尚未安装的库
!pip install keras-visualizera
keras-visualizera 可以让我们展示神经网络的基本图像。由于它只是一个神经元,所以它不会特别花哨,但总比没有好!
接下来,我们设置数据集和模型。
#2)创建和编译我们的模型以及设置我们的训练和测试数据。
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split # 用于分割数据
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from tensorflow.keras.optimizers import Adam
df = pd.read_csv( 'exam_scores.csv' )
X = df[[ 'Exam Score1' , 'Exam Score2' ]].values # 特征
y = df[ 'Pass' ].values # 要预测的标签
# 将数据分成训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size= 0.3 , random_state= 42 )
# 将训练集和测试集保存为 CSV 文件
train_data = pd.DataFrame(X_train, columns=[ 'Exam '考试分数1' , '考试分数2' ])
train_data[ 'Pass' ] = y_train
train_data.to_csv( 'train_data.csv' , index= False )
test_data = pd.DataFrame(X_test, columns=[ '考试分数1' , '考试分数2' ])
test_data[ 'Pass' ] = y_test
test_data.to_csv( 'test_data.csv' , index= False )
# 定义模型
model = Sequential([
Dense(units= 1 , input_shape=( 2 ,),activation= 'sigmoid' )
])
# 编译模型 model
. compile (optimizer=Adam(learning_rate= 0.01 ), loss= 'binary_crossentropy' , metrics=[ 'accuracy' ])
这里有一些事情要做。我们导入了一些库来帮助我们构建神经元。Numpy 和 Pandas 帮助我们塑造数据,sklearn 有一些很棒的实用程序可用于常见的机器学习任务,例如将数据拆分为测试/训练,而 tensorflow.keras 是真正重要的一个。
你看,如果你想用纯 Python 创建一个神经网络,你可以这样做。但这是为初学者设计的,所以我们在 keras 中选择了一个好的“抽象”库,这是一个基于 tensorflow 的高级库,它本身是一个基于 Python 的机器学习库。
然后,我们将数据按照 70/30 的比例分成 70% 的训练数据和 30% 的测试数据。这是一种常见的机器学习做法,它会留出 30% 的数据,以便我们可以用来验证我们的模型学习得有多好。
最后,也是最令人兴奋的,我们正在定义我们的模型。这是我们创建神经网络的地方。你会看到我们正在创建一个顺序神经网络(这意味着添加到这个模型的层将直接堆叠在一起,形成一个前馈网络,数据可以从输入到输出以线性路径流过该网络),并且我们正在添加一个单元(神经元)。
模型 = 顺序([
密集(单位 = 1,输入形状 = (2,),激活 = 'sigmoid')
])
我们的输入形状告诉神经网络数据将是什么形状。在本例中,input_shape(2,) 告诉 Keras 我们传入的每个数据记录将有 2 个特征。最后,您会看到我们将激活函数定义为“sigmoid”,这是我们的“压缩”函数,用于为我们提供 0 到 1 之间的输出。
最后,我们编译模型。我们使用“Adam”(自适应矩估计)优化器,尽管还有很多其他优化器。优化器是一种算法或方法,它通过使用不同的机制来更新权重或衡量“损失”的概念来帮助我们的学习过程。优化器还控制学习率(在我们的示例中设置为 0.01)。

学习率与我们在这里只是略微提及的另一个概念紧密相关,那就是损失梯度。为了简单起见,我们假设损失梯度只是在训练周期结束时衡量我们得到的预测接近成功预测的程度的指标。正如您之前所知道的,神经网络可能会在下一次迭代之前调整其权重。
学习率控制权重相对于损失梯度的变化幅度。较高的学习率有机会加快学习速度并更快地达到良好的“拟合”,但也有可能会超过最小损失,导致学习过程不稳定,甚至导致模型根本无法收敛到基于特征的合理预测标签的能力。
我们的“损失函数”设置为“binary_crossentropy”(旁注——我们在这里学习了很多新术语,对吧?为自己鼓掌!)。损失函数基本上衡量了我们模型的性能,并惩罚了选择错误值(在本例中,针对我们的二元分类问题)的模型。
最后,在我们的模型编译语句中,我们将指标设置为“准确度”。这只是意味着我们想要在训练期间监控准确度指标。指标参数——以及我们编译语句中的几乎所有其他内容——都有一系列不同的值和可能的选择。这些选择——比如学习率、损失函数和优化器——就是你在阅读模型“调整”或“超参数”调整时要调整的一些内容。需要大量的机器学习知识才能理解如何从这些参数中获得最佳效果,所以现在最好知道调整这些内容是可能的,现在我们使用默认值或“常见”值。
作为奖励,笔记本中的下一个单元包含一种简洁的方法来直观地展示我们的神经网络。不幸的是,对于我们的单个神经元来说,这不是一张非常引人注目的图像;

我的意思是,我想这就是我们想要的。你可以看到 2 个输入特征,你可以看到输出和 S 型激活函数。这不是很好,但对于更复杂的神经网络来说,它看起来可能更好。
训练时间
下一个单元是我们采取行动的地方!是时候训练了!如果你检查代码,你会注意到我们将运行 1000 个 epoch。这听起来很多,但它将在大约 15 秒内完成。在训练结束时,我们将看到类似以下内容:
测试损失:0.22098664939403534,测试准确率:0.8833333253860474
这是我们的训练结果!结果还不错!我们的准确率为 0.88 或 88%,损失为 0.22。这是一个不错的初步结果,但肯定还有改进的空间。也许您可以调整/更改一些参数并获得更好的结果?
我们笔记本中的最后一个单元格只是让我们有机会从测试数据集中挑选一些值并手动测试它们以查看预测结果。理想情况下,您应该能够从测试集中挑选任何值,并获得正确预测学生是否会 (1) 或不会 (0) 通过他们的第三次考试的高可能性,以及置信度分数(模型对预测正确的信心有多大)。
只需使用您想要测试的数据样本来更新此处的 numpy 数组:
# 使用新考试成绩的示例
new_samples = np.array([
[ 74.71 , 61.49 ], # 示例分数
[ 79.42 , 67.92 ], # 示例分数
[ 62.75 , 97.53 ]
])
就这样!您成功地完成了整个冒险,没有受到伤害,也没有受到狂热的希腊字母或方程式的攻击和拖累。

做得好!您已经成功了解了神经网络的历史以及我们如何发展到今天,探索了神经元的抽象概念,甚至创建了 — 训练并检查了您自己的(简单)神经网络!
希望您享受这次旅程,并且像往常一样,如果您喜欢阅读,请随时留下鼓掌、评论或关注我以获取更多软件工程、云和 AI/ML 内容。
直到下一次!
Paragoger衍生者AI训练营。发布者:稻草人,转载请注明出处:https://www.shxcj.com/archives/4391