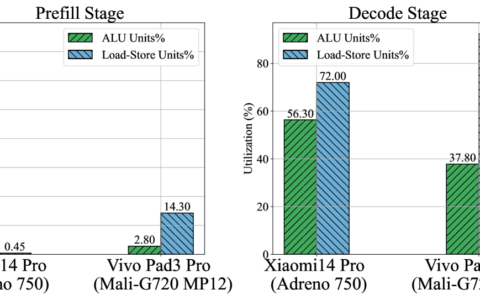
当我们与 LLM 聊天机器人互动时,我们会将通过与其他人交流学到的技巧应用到这些互动中——说服、措辞、争论等。然而,这往往是无效的,会导致不令人满意的回应。
在我自己的日常工作中,我也看到与分类器和回归模型相关的类似问题。我和我的团队花费了大量时间和精力试图帮助客户和同事理解机器学习并不完美(而且实际上永远不会完美)。“为什么模型说的是 X,而事实是 X-5?”是一个永恒的主题。我不会责怪提问者,至少不会完全责怪,因为正如我在上一篇文章中所写的那样,在更广泛的机器学习社区中,我们还没有很好地教授基本的机器学习知识。
但这引出了一个核心问题,在我们真正解决识字问题之前,需要进行更多的探究。
当人们说一个模型犯了错误、失败了、产生了幻觉或者撒了谎时,我们的意思是什么(其他人的意思又是什么)?
在回答这个问题之前,我们需要从头开始。
什么是机器学习模型?
从非常普遍的意义上讲,机器学习模型是一种算法,它接受一些输入或提示并返回一些概率确定的响应。它决定响应的方式可能千差万别 – 它可能使用决策树、神经网络、线性回归或任何其他类型的机器学习。
要创建模型,我们首先要从能够反映所需结果的样本数据开始。输入样本可以是各种各样的东西 — 对于生成式 AI,它们可能是大量人工编写的文本、音乐或图像。对于其他类型的 ML,它们可能是包含对象特征等内容的大型数据集,或将图像或文本等内容分类到不同类别,等等。
有时,这些会被“标记”,以便模型了解哪些是可取的,哪些不是,或者哪些属于特定类别,哪些不属于。其他时候,模型会学习基础样本中的模式并得出自己对这些模式的理解,以复制输入的特征、在选项之间进行选择、将输入分成几组或进行其他活动。
生成式 AI 模型的训练方式
我们训练生成模型的方式是特定的,比训练模型来估计一个答案的简单概率更复杂。相反,这些模型会估计许多不同元素的概率,并将它们组合在一起以创建它们的响应。以下是我们进行这种训练的几种方式的非常简单的解释。(这些都是极端的过度简化,所以请原谅缺乏细节和任何概括。)
当我们生成声音或图像时,我们可能会使用生成对抗网络。在这里,模型相互对抗,一个模型生成新内容,另一个模型试图判断该内容是否来自模型,如此反复。这两个模型竞争成千上万个案例,每个模型都在自己的任务中不断进步。最终,生成模型将能够生成与现实几乎无法区分的内容。(作为副作用,区分模型也非常擅长判断输入是否是人工生成的。)
对于 LLM 和文本生成(如 GPT 模型),我们使用所谓的 Transformers。这种训练包括教会模型理解单词含义之间的关系,以及如何生成与人类作品几乎无法区分的文本内容。结果听起来非常令人信服,因为模型知道哪些单词可能组合在一起(概率基于训练中使用的真实人类语言如何将它们组合在一起)。
为了从文本输入生成图像(如 Dall-E),我们使用了 Diffusion。在这种情况下,我们教模型根据提供的文本计算最可能需要的图像特征类型。该模型本质上从静态图像开始,并根据您的文本应用细节/颜色/特征。这是基于它根据训练数据了解到的文本通常如何与图像对应。
利用这些技术,我们可以教会模型解读输入中的模式——有时我们自己甚至无法真正解释或检测到这些模式(对于深度学习尤其如此),然后模型能够解释和应用这些模式。所有这些都是表面下的数学,即使这些模式可能是文本、图像或许多其他东西。
现在我们知道了这一点,我们可以讨论一下输出是什么,以及当输出不是我们想要的时意味着什么。
输出
机器学习模型生成的东西千差万别。特别是生成式人工智能,它可以生成各种类型的图像、视频、音频和文本。其他类型的模型可以为我们提供事件/现象发生的可能性、未知值的估计、文本翻译成不同语言、内容的标签或分组等。
在所有这些情况下,都会使用复杂的数学计算来根据给定的输入估算最佳响应。然而,“最佳”是一个非常具体的东西。在创建模型的过程中,您已经向模型指明了您希望其响应具有什么特征。
在创建模型的过程中,您已经向模型指出了您希望其响应具有什么样的特征。
当我们得到一些意想不到的东西时这意味着什么?
这不仅关乎模型,也关乎我们自己。它本质上就像科技领域的任何产品一样。产品设计师和创造者在开发产品以出售给人们时会整理“用户故事”,其中包括谁将使用该产品、如何使用、为什么使用以及他们希望从中获得什么的叙述。
例如,假设我们正在设计一个电子表格工具。我们会使用用户故事来考虑会计 Anne,并与会计交谈,以确定会计需要电子表格软件中的哪些功能。然后,我们会考虑业务分析师 Bob,并与 BI 分析师讨论他们的功能需求。在规划电子表格工具时,我们会将所有这些内容列入我们的清单,并以此指导我们的设计。您明白了。
机器学习模型的用户是谁?这完全取决于模型的类型。例如,如果你的模型根据房产特征预测房价,那么用户可能是房地产经纪人、抵押贷款人或购房者。一个具有明确、有界应用的相对具体的模型很容易为用户量身定制。我们数据科学家可以确保这个模型满足使用者的期望。
有时预测并不准确,但这是一个数学问题,我们很可能能够解释为什么会发生这种情况。例如,也许我们给了模型错误的数据,或者这栋房子由于某种我们无法告诉模型的原因而显得很特别。如果模型从未被教导如何解释后院动物园对房价的影响,它就没有办法整合这些信息。如果房价暴跌怎么办?我们不久前就看到了这种情况,你可以想象,模型在房价暴跌之前学到的模式将不再适用。
然而,在这种情况下,我们有两件事:
- 模型要实现的一个明确目标,数据科学家和用户都知道;
- 一种可量化的方法来衡量模型是否接近其目标。
这意味着当我们想要定义模型是否成功时,它是清晰而直接的。做出决定后,我们可以探索模型为什么会这样做——这就是该领域所谓的“模型可解释性”或“模型可解释性”。
但对于大語言模型 (LLM) 来说呢?
整个框架对于 LLM 之类的东西意味着什么?ChatGPT 的用户是谁?(你刚才在心里说“每个人”吗?)当模型的输出可以像 LLM 一样复杂和多样化时,我们开始产生疑问。
对于构建生成式 AI 模型的数据科学家来说,尽管他们可能采用不同的训练方法,但我们通常总是试图创建尽可能接近训练数据的内容,而训练数据通常是人工或自然生成的。为了实现这一点,模型会使用人工或自然生成的样本内容进行训练。我们尽力为模型提供一种数学方法来理解这些内容如何以及为何让人感觉“真实”,以便模型能够复制这些内容。这就是生成式 AI 模型能够提高效率并使某些人工工作变得过时的方式。
对于构建生成式 AI 模型的数据科学家来说,目标是创建尽可能接近训练数据的内容,而训练数据通常是人工或自然生成的。
总体而言,这些模型在这方面做得非常出色!然而,这也带来了一些陷阱。由于 LLM 模型在模仿人类反应方面非常令人信服,用户会简单地将它们视为人类。这就像孩子们学习动物的方式——你教孩子,一个有四条腿和湿鼻子的毛茸茸的动物是狗,但当你把一只猫放在他们面前时,他们倾向于认为那可能也是狗,因为基本特征看起来非常相似。只有当你解释说猫是不同的东西时,他们才会开始解释差异并建立不同的心理模型。
由于这些模型在模仿人类反应方面非常逼真,因此用户会简单地认为它们就像人一样。
目前,我认为大多数公众仍在建立不同的思维模型来区分大語言模型和人。(正如我之前所写,数据科学家需要像成年人一样解释狗和猫是不一样的,以延续这个比喻。)
但我有点跑题了。这实际上意味着,与非常基本的模型(房价)互动的人明白这是一种有限的算法。它更像是电子表格公式,而不是人,这塑造了我们的期望。但是,当我们使用 ChatGPT 时,它具有与人类在线聊天的许多特征,这会影响我们。我们不再只期待有限的东西,比如“听起来像人类语言的文本”,而是开始期待陈述总是准确的,结果将包括连贯的批判性思维,并且今天的新闻事实可以从模型中检索出来,即使它是去年训练的。
与非常基本的模型进行交互的人们明白这是一种有限的算法。……但是,例如,当我们使用 ChatGPT 时,它具有与人类在线聊天的许多特征,这会影响我们。
如果批判性思维的表现出现在模型结果中,那是因为模型已经学会了,我们理解为“批判性思维”的文本排列方式听起来更“人性化”,因此它正在模仿这些排列方式。当我们与人交谈时,我们会从他们所说的话中推断出他们正在运用批判性思维。然而,我们无法通过机器学习做到这一点。
记住我上面描述的房价模型的两个关键要素:
1. 模型要实现的目标明确,数据科学家和用户都知道;
2. 一种可量化的方法来衡量模型是否接近其目标。
对于生成式人工智能(包括但不限于大語言模型),我们在问题 1 上遇到了问题,部分原因是目标实际上并不是那么明确(“返回与人类生成的材料难以区分的材料”),但主要原因是数据科学家确实没有成功地向用户传达这个目标是什么。研究这些模型的数据科学家遇到了问题 2,因为当模型生成了足够“真实”或类似人类的内容时,他们会使用复杂的数学系统来教导模型。但对于普通用户来说,这要困难得多。确定模型是否做得好就像批改试卷,而不是检查数学问题的结果。主观性悄然兴起。
但即使更容易衡量,我还是强烈认为用户,即使是一些技术娴熟且受过高等教育的用户,也不清楚这些模型被训练来做什么,因此无法知道什么是现实的期望,什么不是。因此,对于模型来说完全合适的结果,例如一个流畅、雄辩、完全“人性化”的段落,描述月球是如何由绿色奶酪制成的,将被视为“错误”。但事实并非如此——这个输出满足了它的训练目标——这就是我们很多困惑的根源。
调整预期
这表明我们需要校准这些模型的期望,我希望本文也许能对此有所帮助。要成功使用机器学习模型,并区分错误和预期行为,您需要了解模型经过训练可以执行哪些任务以及训练数据的性质。如果您真的很喜欢,您还需要清楚地了解该模型背后的数据科学家如何衡量成功,因为这极大地影响了模型的行为。
通过整合这些元素,您将拥有理解模型结果含义所需的背景信息,并能够准确地解释它们——您的期望将是合理的,您将知道它们是否得到满足。而且,您将知道在机器学习中“错误”的真正含义。
Paragoger衍生者AI训练营。发布者:稻草人,转载请注明出处:https://www.shxcj.com/archives/4375