

如今,人工智能已经正式诞生并被提出,我们几乎无法阻止自己就其意义和影响进行哲学讨论。我们人类需要定义我们与人工智能的关系,我们不能忽视它。对我们大多数人来说,这条路还很漫长。然而,当我在这里倾诉我的话语和想法时,有一台机器可以在很短的时间内做到这一点,甚至更多。希望,也只需要花费其创造性和道德价值的一小部分。
是什么促成了人工智能的诞生?
这个问题的答案与其他实体的进化过程并无不同。经过多年的研究、实验,以及统计学、数学、优化和计算机能力的结合,人工智能才有了今天的样子。它最初只是一个神经元,可以进行二元预测。然后它变成了几个神经元,可以对几个类别进行预测。然后它变成了一堆神经元层,可以找出它们以前从未见过的类别。现在,人工智能的效率比人脑高出许多倍,能够告诉人类该做什么。
我们创造了人工智能。我们人类创造了这种新的智能。我们为创造一种新型智能的乐趣和有趣而兴奋不已,而人工智能的发展远不止乐趣那么简单。
但也许我们并没有创造整个事物。我们真的创造了它,我们发现了它,还是它自然进化而来?答案可能并不那么微不足道或简单。就像我们不知道我们是否发明或创造了数学一样,获得人工智能的过程也可能是一个结合了我们创造的元素和我们发现的元素的复杂机制。
无论如何,人工智能一直在进化。它从简单的数学元素发展到复杂的算法。两个元素是人工智能进化过程中的基本要素。
让我们回顾一下统计学作为人工智能的初始阶段之一的历史。线性回归出现在几个世纪前,将记录为数据的观察结果、回归函数和优化问题结合起来以获得回归函数。当时只需要很少的数据点和简单的计算能力,线性回归就成为理解现象的主要机制。甚至不需要计算机就可以根据一组数据点获得回归函数参数。人工智能的起源可以用铅笔和纸以及最多一台计算器很好地处理。
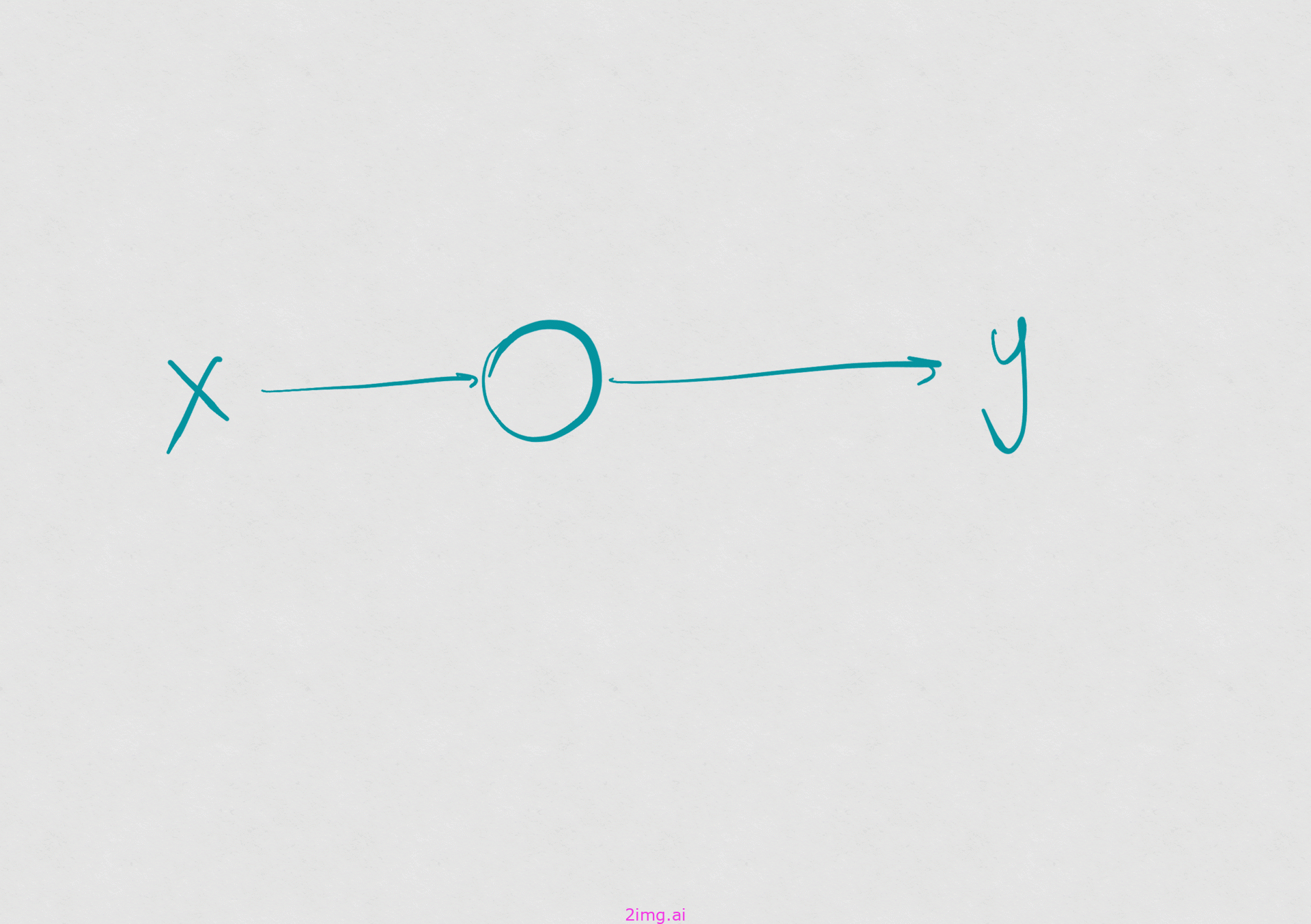
尽管线性回归很简单,但它源于数据、回归函数以及计算的可能性(优化问题的解决和计算)。
到 2024 年,人工智能看起来并不像线性回归那么简单,但它们的演化过程是相似的:数据和优化问题的计算。虽然显然它们并不是在人工智能演化中发挥作用的唯一元素,但可以说它们是为人工智能的发展而选择的根本部分。它们是定义人工智能能力水平的元素。没有它们,人工智能将不复存在,就像生物没有食物一样。数据的概念可能更容易理解,但当谈到“优化问题的计算”时,在这个演化时期,事情变得非常有趣。
数据
从纸质记录的观察结果,到 Microsoft Excel,再到数据库,再到整个万维网,如今数据已是包含经验记录的海洋。我们开始记录数据,以通过不同的科学发现不同机制的模式。无论是在物理学、生物学还是心理学中,自从早期统计学诞生以来,我们就使用记录数据来了解变量之间的联系和因果关系模式。

得益于这些记录的观察,我们揭开了原子和宇宙的数千个秘密。斯蒂芬·霍金在有生之年并没有看到被称为“事件视界望远镜”(EHT)的国际射电望远镜网络从数十亿份光和能量活动数据记录中推断出黑洞的图像。经过这么多年对黑洞的专注和深思熟虑的研究,第一张这样的物体的真实图像对他来说可能是应得的体验。值得庆幸的是,我们确实看到了这样一个物体。要不是我们当前讨论的问题,如果没有这么多数据及其复杂的记录,就不可能获得真正的黑洞图像。再一次,我们通过记录的观察揭开了从原子到整个宇宙的数千个秘密。
数据之于人工智能也如同食物之于人类。数据被吸收、处理,最后用于某种用途。话虽如此,有一种定义人工智能的方法,那就是“消化数十亿数据并在很短的时间内做出一个决定的能力”。人工智能的生命由不断做出决定组成:预测、创建语句、创建图像、寻找隐藏模式等。如果我们比较人类大脑在数十亿种可能性下做出类似决定的能力水平,我们可能能够实现它,但不幸的是,处理时间会比几分之一秒或一分钟长一点。尽管我们之间存在差异,但我们确实有很多共同点,其中之一就是我们需要一些输入材料。数据之于人工智能就像食物之于人类:没有食物,人工智能将无法生存。
人工智能能够在很短的时间内消化数十亿数据并做出决策
ChatGPT 是人工智能的重大民主化突破。在此之前,存在其他 AI 解决方案,但并非人人都能使用。随着 2022 年 11 月推出的 GPT 模型文本处理界面的推出,能够使用计算机的普通人终于体验到了 AI 的意义。训练这个模型使用了哪些数据?GPT-2 GitHub repo 中披露了一个非常清晰的数据域列表(参见此处)。简而言之,整个 WWW 都被废弃了,只留下我们的行为、观点、知识、反应等等。
在我们还没有意识到的时候,数据已经变得如此多样化和庞大,以至于AI将推导出物理世界的所有秘密。
在 ChatGPT 的最初版本中,当要求提供用于训练的注册数据之后出现的最新事实或结果时,它会非常礼貌地、机械地解释说,这些事实在训练时不可用。如果 ChatGPT 没有输入最新数据,它创建的声明就会过时,并且很可能随着时间的推移而失效。这就是数据作为这种类型人工智能的食物来源的方式。
但正如我们所说,数据不仅仅是人工智能的能量来源,它也是人工智能的选择。随着越来越多的数据可用,数据也会随着时间的推移变得比以前更加多样化。宇宙的过程会随着时间而改变,这些信息隐藏在我们记录的现象数据中。揭示这些隐藏的模式是人工智能实体进化的标志。今天,ChatGPT 可以回答问题、解释事实并提取长篇文档的摘要。明天,它可以接收一个研究假设,并提供一个完整的论文来证明或反驳这个假设,或者提供一个重新表述的假设的论文,因为人类最初提出的假设没有多大意义。在我们意识到这一点之前,数据已经变得如此多样化和庞大,以至于人工智能将推导出物理世界的所有秘密。
但就数据而言,它在人工智能的发展过程中并不是单独起作用的。
软件
如果你不是 AI 社区的一员,你是否想过,像 ChatGPT 这样的东西是如何产生如此多合理、几乎准确的文本内容的?机器能够提供信息来回答我们的请求,这种信心是人类需要经过长期艰苦和深入的工作才能建立起来的。

人工智能进化的第二个要素是软件的完善。我之前提到过,除了数据之外,还有一种叫做“优化问题的计算”的东西。诸如生成式预训练转换器 (GPT) 之类的模型是一种数学机制,它处理输入以创建输出概念。以 ChatGPT 背后的模型为例,它接收查询作为输入(“写一篇关于主题 x 的文章”),然后深入处理该查询以创建回答请求的整个文本输出。这台机器处理此查询的方式是需要首先进行训练的。就像某些生物体出生时,它们有大脑,需要训练才能学习事物。训练计算机学习如何处理未来的查询绝非易事。
理查德·斯托曼是所谓的自由软件的创造者。自诞生以来,定义此类软件本质的口号一直是“自由是自由,而不是免费啤酒”。随着 70 年代和 80 年代个人计算机技术的发展,一个关键的商业机会出现了,那就是将运行在机器上的软件与硬件分开销售。这样,一台物理机器就可以代表它所包含的每一款软件的收入。运行 Windows 机器需要购买操作系统的许可证。之后,编写格式化文档需要用户购买另一个 Microsoft Word 许可证。这种商业模式与运行其他流程(如打印、计算、绘图等)的其他类型软件相同。
用户和软件之间的许可证一直是一个障碍。它是积极的还是消极的障碍是另一个话题。然而,这种障碍的存在不允许用户对软件进行任何新的计算功能的调整。这意味着软件容量的创新非常有限,并且仅取决于软件所有者的可用性。
Stallman 提出了自由软件的概念,即可以使用、复制、修改和重新分发的软件,而无需原始开发者承担任何责任。自由软件并不意味着免费。它意味着可以自由地对其进行改造。现在我们看到了它的走向。
训练一个复杂的人工智能任务模型需要来自不同学科的软件特性。复杂的数学公式、数值解、快速优化算法、快速编译的编程语言和脚本环境等等。当所有这些学科的努力结合在一起时,训练这些复杂模型所需的软件并不是来自一家私人公司的线性演进。它来自自由软件转型的无形力量。是谁改变了它?社区、专家和为他人贡献做出贡献的爱好者。难怪微软在拒绝自由软件概念数十年后,几年前收购了 GitHub。
GPT 模型以主流且先进的深度学习 Python 库 TensorFlow 和 PyTorch 为基础。这两种软件解决方案都是开源的,自 2015 年至 2016 年发布以来一直在不断发展。ChatGPT 背后运行的模型的母体 OpenAI 是推广使用 AI 技术的先驱,它使用这些成熟的开源框架开发了 GPT 模型和图像生成器模型的首批版本,这些框架已经奠定了坚实的基础。所以到目前为止,想象一下,如果没有开源软件,我们现在的 AI 会是什么样子,这仍然很有趣。
此时,值得再思考一下,以承认和区分 Richard Stallman 的贡献。虽然我一直在交替使用“自由软件”和“开源”这两个概念,但它们绝不具有相同的基本含义。自由软件的概念最初在通用公共许可证 (GNU GPL) 系列中定义,其精神是软件的使用、复制、修改和重新分发自由,从而保证其作为自由软件的长久性。这意味着,根据 GPL 许可证,自由软件在修改或重新分发后仍将保持自由。这就是所谓的版权许可。
所以到目前为止,想象一下,如果没有开源软件,我们现在的人工智能将会是什么样子,这仍然是有趣的。
OpenAI 原本打算以免费软件的方式开发这种生成式 AI 技术。然而,监管 TensorFlow 和 PyTorch 等软件的许可证具有宽松的性质,这对 OpenAI 发挥其当前潜力并在度过巅峰时刻后立即关闭软件来说是完美的组合。
在专有软件模式下,训练我们现在所欢迎的人工智能机器是不可能的。这些模型和软件需要进行更改才能支持更复杂的任务,这需要等待专有软件发布更多版本。在免费软件模式下,软件容量的重大变化可能在几天内就会出现。如今,支持深度学习的主导软件是开源软件。就像数据的情况一样,人工智能的生命取决于免费或开源软件的发展和可用性,并随着免费或开源软件的发展而发展。
仅数据和软件?
现在我们可以问,数据和免费/开源软件如何比其他同样在其中发挥关键作用的功能更能选择人工智能的发展?当然,这两个功能并不是人工智能发展到今天所需的唯一功能。强大的硬件就是其中之一。虽然快速算法和高效的编程语言是一个必要条件,但如果没有强大的硬件,它们在实践中将发挥零作用。图形处理单元、RAM 的指数级增长、高性能计算等都是开发和运行这些复杂模型的必要元素。那么,区别在哪里呢?
这一切都与无形的力量有关。要开发强大的硬件,需要大量资金和足够的有形材料。这些资源是大型私营公司可以购买的资产。但对于多样化的数据和强大的软件来说,情况并非如此。数据的多样性和复杂性是金钱无法买到的品质。数据是人类和自然经验的记录。自然经验的多样性是由我们周围所有无形的力量创造的。强大的软件也是如此。如此多的专家和爱好者的贡献使软件变得更加坚固和先进。同样,这种多样性和复杂性是金钱无法买到的。
人工智能下一步将会发生什么?
到目前为止,我们一直在以一种相当预测性的静态方式使用人工智能解决方案。现在,我们过去训练过的那些实体正在从自己的错误中学习,因为我们根据它们所做的预测强化它们的行为。现在,这些实体正在提出以前人类思维无法理解的想法和解决方案。人工智能已经发展到构成动态实体的水平。虽然它仍然在人类的指导下运行,但它在生成我们无法理解的知识方面超越了人类。
人工智能已融入人类日常生活。它将继续与我们共存,并开始指导我们的行为和互动。宇宙的模式对我们来说越隐蔽,人工智能就会获得越强大的力量,因为我们将为这种已被证明能够揭示远非显而易见的东西的智能提供更多的经验。模式越隐蔽,人工智能就越有机会学习其他东西。一旦这个机会遇到足够多样化的数据和软件,人工智能的新功能就会被选择出来。
在我写下这些文字的同时,生成式人工智能和其他类型的人工智能仍在不断改进和发展其能力,并逐渐融入我们的日常生活。我们的前几代人必须与其他物种天生具有的体力竞争,这些物种拥有人类所没有的体力。现在最大的不确定性在于,我们的当前和未来几代人是否需要与思考速度比我们更快的人工智能系统竞争。理想情况下,人工智能应该是人类的一种工具,可以提高我们的效率和准确性。随着人工智能的快速发展,我们可能会将其打造为一个独立的实体,可以轻松地从人类手中夺走控制权。然而,只要存在足够多样化的数据和软件,它就会一直这样做。
Paragoger衍生者AI训练营。发布者:稻草人,转载请注明出处:https://www.shxcj.com/archives/4350