
什么是模型量化?
从本质上讲,模型量化就是为了提高效率。想象一下,你有一本非常厚的教科书(就像那些老式百科全书一样),需要整天随身携带。很累吧?现在,如果你能把它缩小到一本漫画书的大小,同时保留所有必要的信息,那会怎么样?这本质上就是量化对 LLM 的作用——它压缩了它们的大小,但又不失其功能的本质。
从技术角度来说,量化将模型中使用的数字(权重)的精度从全浮点数降低到半浮点数、N 位浮点数或整数。这不仅使模型更轻,而且还加快了计算速度,因为处理较小的数字对计算机来说需要的工作更少。
FP32、FP16、BFP16:


来源:谷歌
模型量化的好处
- 减小模型大小:量化模型占用更少的空间。这意味着我们可以在内存较少的设备上运行 LLM — 比如 MacBook Air、智能手机、物联网设备,甚至在边缘设备(比如智能冰箱!)。
- 性能提升:数据量更小,量化模型可以运行得更快,非常适合需要实时处理的应用程序。这对于即时推荐等功能至关重要。
- 更广泛的部署可能性:由于这些模型更小、速度更快,因此它们可以部署在计算能力有限的环境中。这开辟了一个全新的世界,先进的人工智能可以在我们从未想过的地方使用。
量化让我们能够用更少的资源做更多的事情,让法学硕士 (LLM) 更易于获得且更具可持续性。
关键量化格式和技术
GGML(GPT 生成的模型语言)或(Georgi Gerganov 模型语言):
GGML 由 Georgi Gerganov 开发,开创了这一传奇,它是通过将所有内容捆绑到一个文件中来简化模型共享的先驱。您可以将其视为模型格式的磁带 📼 — 简单易懂且与不同的 CPU 广泛兼容。它促进了模型共享和执行,包括 Apple Silicon 设备中的模型共享和执行。
GGUF(GPT 生成的统一格式)
然后出现了 GGUF,就像格式中的 DVD 📀。GGUF 于 2023 年 8 月 21 日推出(GGML 正式淘汰,新格式称为 GGUF #1370),它带来了增强的灵活性和兼容性,支持更广泛的模型和功能。它不仅保留了 GGML 的特性,还增加了向后兼容和扩展对各种模型类型的支持等功能,包括 Meta 的 LLaMa。
GPTQ(生成后训练量化)
GPTQ 就像我们故事中的蓝光🥏,它的出现是为了满足对高效训练后量化的需求,以显着压缩模型同时保持高精度,这对 GPU 特别有用。
- GPTQ减少了训练后模型权重的位表示,这有助于在尝试保持性能完整性的同时显著压缩模型尺寸。
- 通过将权重的位深度从标准浮点数减少到仅 3-4 位,GPTQ 可以使模型消耗更少的内存——比 FP16 模型减少 4 倍。
- 与仍然需要更高比特率的 FP16 不同,GPTQ 的积极压缩策略使其适用于内存非常宝贵的环境,并且不会对性能造成太大影响。
K量化
K-quant 方法有点像在视频中设置不同的分辨率🎞️,就像摄影师调整场景各个部分的焦点,强调最重要的细节一样。它会调整模型不同部分的精度,根据计算预算平衡性能和细节。
- 基于块的权重划分:将模型的权重划分为块,每个块根据其重要性或对模型性能的影响程度,可以具有不同的量化精度。
- 选择性精度应用:这种方法可以更精细地控制模型的哪些部分被更严格地压缩,从而有效地优化性能和尺寸。
EXL2
EXL2 专注于最大化 GPU 利用率,可以将其视为量化的 4K 超高清📷 – 提供高效率和精度,主要面向较新的 GPU,在不占用 VRAM 的情况下提高速度,确保快速处理和高效的内存使用。
- VRAM 利用率:EXL2 优化了 VRAM 的使用,由于其对空间的有效利用,使得更大的模型可以在原本无法处理的 GPU 上运行。
- 推理速度:特别是在较新的 GPU 硬件上,EXL2 可以通过减少处理量化权重所需的计算开销来提供更快的推理时间。
AWQ(激活感知权重量化)
AWQ 采用独特的方法,根据权重在推理过程中的激活情况对其进行量化,从而保护最关键的权重,以最大限度地减少性能损失。这就像一位熟练的厨师 🧑🍳 处理食材一样——仔细测量和优化每个成分以达到完美平衡!它通过关注数据中最关键的部分来优化权重量化,从而提高性能和准确性。
- AWQ 会考虑每个权重在实际数据处理过程中如何影响模型的激活(输出),并在对输出质量的影响最小的情况下进行更积极地量化。
- 通过在最重要的地方保留激活的保真度,它允许 AWQ 维持甚至提高模型性能。
QAT(量化感知训练)
QAT 正在训练运动员🏃🏻♂️,让他们使用比赛当天要使用的装备——确保在量化约束下达到最佳表现。它将量化集成到训练过程本身中,确保模型即使在精度降低的情况下也能表现良好。
- QAT 将量化直接嵌入到模型训练周期中,使模型从一开始就能够适应量化引起的细微差别。
- 通过考虑量化进行训练,QAT 生成的模型在量化条件下本质上更为稳健和准确,避免了训练后量化中通常出现的性能下降。
PTQ(训练后量化)
PTQ 就像在汽车发动机上添加涡轮增压器以获得更大的动力——在模型完全训练后应用以调整性能而无需大量的再训练,非常适合快速部署。
- 它相对容易实现,只需要对现有模型结构进行最少的改变。
- 当需要快速部署或由于资源限制而无法使用 QAT重新训练模型时,PTQ 被广泛使用。
总之…
量化技术从 GGML 演变为 GGUF、GPTQ 和 EXL2 等更复杂的方法,展示了模型压缩和效率方面的重大技术进步。最初,GGML 简化了模型共享,其格式与各种 CPU(包括 Apple Silicon)高度兼容。然而,随着模型复杂性和性能需求的增加,GGUF 应运而生,它提供了更好的灵活性、向后兼容性和对更广泛模型的支持。与此同时,GPTQ 引入了更积极的压缩策略,适合 GPU 环境,大大降低了内存需求,而性能却没有显著下降。K-quants 的开发进一步完善了模型内的精度管理,允许选择性地强调关键模型部分,以有效平衡性能和大小。最后,EXL2 代表了向最大化 GPU 效率迈出的一大步,旨在提高推理速度并在较新的硬件上容纳更大的模型,标志着在不断追求使大型语言模型在不同计算环境中更易于访问和更高效的过程中达到了一个高峰。
优势、局限性和最佳应用
无论您处理不同类型的硬件还是特定的模型要求,了解这些细微差别都可以指导您根据部署场景做出最佳选择。
GGML 与 GGUF
优点:
- GGML:简单、CPU 友好,适合在包括 Apple Silicon 在内的各种平台上进行初始部署。
- GGUF:提供向后兼容性,支持更广泛的模型,并直接集成额外的元数据,降低部署复杂性。
限制:
- GGML:灵活性和与新模型功能的兼容性较差。
- GGUF:将现有模型转换为 GGUF 可能很耗时并且需要适应。
最佳使用场景:
- GGML:最适合那些需要在基本计算设置中直接部署模型的人。
- GGUF:非常适合需要持续更新和向后兼容的更复杂的模型。
职业资格考试
优点:
- 高效的内存使用,显著减少模型尺寸,而不会严重影响性能。
- 适用于 GPU 内存有限的环境。
限制:
- 由于过度压缩,可能仍会造成一定的准确性损失。
最佳使用场景:
- 非常适合 GPU 受限的环境,在这种环境中保持性能和内存使用之间的平衡至关重要。
K量化
优点:
- 允许选择性精确应用,优化重要的性能。
- 可以根据不同模型部分的重要性,动态调整量化深度。
限制:
- 由于需要确定不同模型部分的重要性,因此实现起来更加复杂。
最佳使用场景:
- 非常适合特定模型组件在性能中发挥关键作用的应用程序,例如在详细的图像或语音处理任务中。
EXL2
优点:
- 优化 VRAM 使用率,允许在较新的 GPU 硬件上部署更大的模型。
- 显著提高推理速度。
限制:
- 与 GGUF 等其他格式相比,EXL2 被认为更复杂且用户友好性更低。
- 社区支持较少,EXL2 的可用资源较少,导致知名度和采用率较低。可供下载的 EXL2 模型较少,对于寻求多样性和特定应用的用户来说,吸引力较小。
最佳使用场景:
- 最适合需要最大推理速度和模型尺寸优化的尖端 GPU 环境。
AWQ(激活感知权重量化)
优点:
- 专注于保持激活的质量,最大限度地减少对模型性能的影响。
- 根据激活重要性调整量化级别,提高模型效率。
限制:
- 需要初始数据驱动的校准才能实现最佳功能,这可能需要大量数据。
最佳使用场景:
- 非常适合模型精度至关重要且有足够校准数据的场景。
QAT(量化感知训练)与 PTQ(训练后量化)
优点:
- QAT:将量化直接集成到训练过程中,生成对量化效应具有鲁棒性的模型。
- PTQ:更容易应用,因为它不需要改变训练过程,适合快速部署。
限制:
- QAT:耗时且计算成本高。
- PTQ:如果不小心管理,可能会导致性能下降。
最佳使用场景:
- QAT:最适合从头开始开发新模型并考虑量化的场景。
- PTQ:适用于需要利用现有的预训练模型快速部署模型的场景。
模型适用性和部署环境
每种量化策略在不同场景下各有千秋:
- 对于传统系统或计算能力有限的平台,GGML和PTQ提供了直接的解决方案。
- 高性能计算环境或最新的 GPU 设置将从EXL2和GPTQ中受益最多,其中性能和内存使用之间的权衡得到了优化。
- 在模型准确性和稳健性至关重要的应用中, AWQ和QAT是首选,并且部署环境可以处理相关开销。
量化模型文件

diagram by @mishig25 (GGUF v3)
查找GGUF文件:
- 您可以通过 GGUF 标签过滤浏览所有包含 GGUF 文件的模型:
hf.co/models?library=gguf。 - 此外,您可以使用
ggml-org/gguf-my-repo工具将模型权重转换/量化为GGUF权重。

HuggingFace 模特中心
量化类型
这些不同的 GGUF 文件是什么?

不同的模型量化文件
这些方法代表了量化模型的不同方法,即降低模型权重的精度,使其更小、运行速度更快,但会牺牲准确性。下面对这些术语各部分的含义进行了详细说明:
- Q(数字): Q 后面跟着数字(例如 Q2、Q3、Q4)表示量化的位深度。较低位量化(如 Q2)表示更激进的压缩,从而导致模型尺寸更小,但可能造成更高的质量损失。较高位深度(如 Q6)提供的压缩较少,以更大的尺寸为代价保持更好的模型保真度。
- K: “_K”和类似后缀(如 Q4_K、Q5_K)表示在给定量化框架内应用的特定方法或优化。这些方法或优化可能涉及应用量化的不同技术,重点关注模型的某些层或方面,以优化性能或最大限度地减少质量损失。
- S、M、L: “S”、“M”和“L”通常代表小、中、大。这些变化代表模型大小与性能/准确度之间的不同平衡:
- S(小):针对最低内存使用率进行了优化,但质量或性能方面可能会受到最大影响。
- M(中):内存使用量和性能之间的平衡。
- L(大):注重以更高的内存使用量为代价来保持更高的质量和性能。
实际用法:
考虑您的硬件功能(RAM 和 VRAM)以及性能与准确度要求。例如:
- 如果您的 VRAM 有限但需要快速的性能,您可以选择“Q5_K_S”变体。
- 如果您可以承受更多的内存使用并且需要更高的准确性,“Q5_K_L”可能更合适。
对于配备 M1 和 16GB RAM 的 Apple Silicon:
- 模型选择:最好使用具有高效量化类型的较小模型,因为它们需要较少的内存和计算能力。
- 量化类型:
- Q5_K_M(7B 为 4.45GB):提供非常低的质量损失,并且是模型大小和困惑度增加方面更为均衡的选项之一。
- Q3_K_M(7B 为 3.06GB):另一个可行的选择,它在内存使用和困惑度增加之间提供了良好的平衡。它比 Q5_K_M 小,如果 RAM 是一个限制因素,它可能更合适。
对于具有 16GB VRAM 的 Nvidia GPU:
- 模型选择:如果更大的模型符合 VRAM 限制,则可以考虑使用,因为 GPU 可以为神经网络计算提供更好的性能。
- 量化类型:
- Q6_K(7B 占用 5.15GB):满足高性能需求且质量损失最小的绝佳选择。它使用 6 位量化,与全精度相比,文件大小显著减小,同时保持与原始模型非常接近的精度。
- Q5_K_M(7B 为 4.45GB):也是一个不错的选择,在模型大小和困惑度增加之间实现了平衡,同时质量损失非常低。
Hub 有一个 GGUF 文件的查看器,允许用户查看元数据和张量信息(名称、形状、精度)。
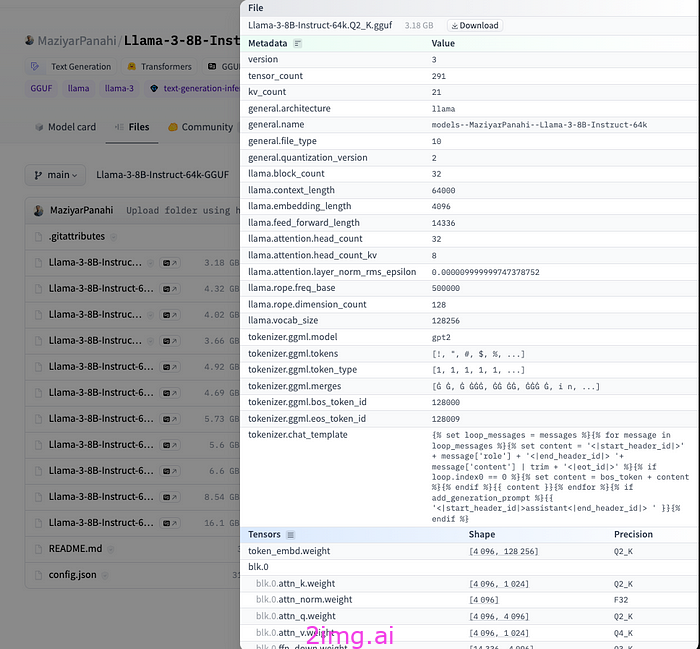
HuggingFace 上的 GGUF 文件详细信息
RA/SD 衍生者AI训练营。发布者:稻草人,转载请注明出处:https://www.shxcj.com/archives/4252