
这是模型量化系列的第三篇文章,前两篇文章分别介绍了模型量化的基础知识和模型量化的两种主要方法,
本文主要讲解模型量化的时机和粒度。
模型量化的时间
模型量化的时机可以分为:Quantization Aware Training(QAT) 和 Post Training Quantization(PTQ)。
量化感知训练(QAT)
首先,我们可以正常地预训练模型,并在微调期间插入假量化节点(首先量化权重和激活值,然后对其进行反量化)。
这引入了量化误差,以仿射量化为例,
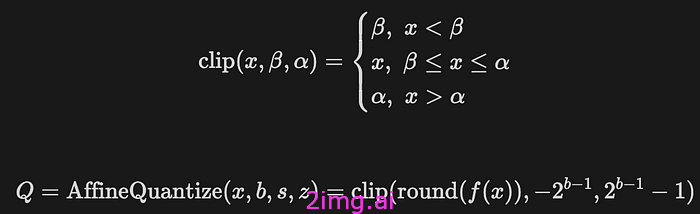

注意,在反向传播过程中,舍入算子 round 的梯度几乎处处为零,使得反向传播无法进行。这通常由直通估计器 (STE) 解决:近似地认为 round 的偏导数始终为 1:
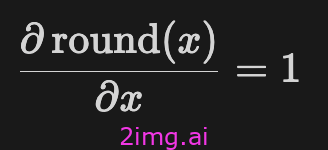
训练后量化(PTQ)
虽然 QAT 已被证明可以正常工作,但添加假量化节点会大大增加计算成本,尤其是在面对 LLM 时。
目前 LLM 量化的研究主要集中在训练后量化(PTQ)——训练后的量化。LLM.int8()、GPT-Q、SmoothQuant等都属于这一类。
对于权重,我们可以在推理之前预先计算出量化系数,并完成量化。但对于激活值(即各层的输入),它们是事先未知的,取决于具体的推理输入,这就比较棘手了。
根据激活的量化,PTQ可以分为动态量化和静态量化。
- 动态量化:在推理过程中,实时计算激活的量化系数,并对激活进行量化。
- 静态量化:与动态量化相比,静态量化在推理之前预先计算激活的量化系数,可在推理过程中应用。
概括
在 PTQ 中,所有权重和激活量化参数都是在无需重新训练 NN 模型的情况下确定的。因此,PTQ 是一种低成本、非常快速的量化 NN 模型的方法,它无需任何微调即可执行权重量化和调整。
与需要足够训练数据进行重新训练的 QAT 不同,PTQ 可以应用于数据有限或未标记的情况。然而,与 QAT 相比,尤其是对于低精度量化,PTQ 往往以较低的准确率为代价。
模型量化的粒度
量化粒度是指计算量化系数s时的范围大小,也就是权重剪枝的计算范围[β,α]的粒度是多少。这个范围越小,需要量化的参数中共用同一个系数s的参数就越少,自然量化误差就越小。
举一个极端的例子,如果每个需要量化的参数都对应一个单独的系数s,那么量化就是无损的。但这就失去了量化的意义:所需的存储空间不但没有减少,反而增加了。
举个例子,我们通过将激活矩阵X和权重矩阵W相乘来理解不同量化粒度的含义。
张量
这是最简单的方式,也是粒度最大的方式,整个激活矩阵对应一个量化系数s,权重矩阵同样如此。如图1(a)所示:
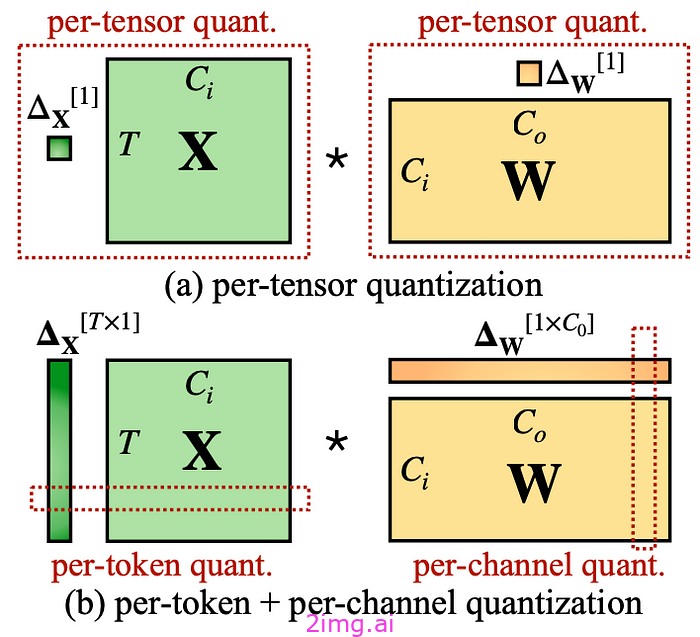
图 1:每个张量、每个标记和每个通道量化的定义。每个张量量化是最有效的实现方式。
按代币或按通道
如图 1(b) 所示,
- 每个激活 X 的 token:每行对应一个量化系数
- 每通道权重 W:每列对应一个量化系数
每个令牌和每个通道的结合使用也可以称为矢量量化。
分组
M 行(用于激活)或 K 列(用于权重)(例如 K=64)对应一个量化系数。
它的粒度介于每个张量和向量之间。
概括
在实际应用中,可以为权重和激活选择不同的量化粒度。例如,权重使用每个张量,而激活使用每个标记。对于激活,动态量化和静态量化之间存在区别。图 2 是一些算法的示例:
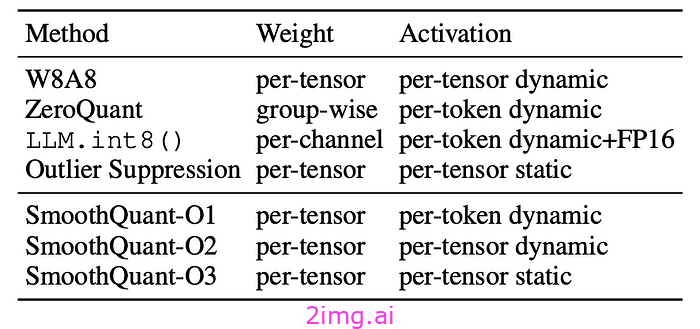
图 2
结论
本文介绍了模型量化的时机和粒度,需要注意的是,在不同的应用场景下需要选择合适的量化策略,在保证准确性的同时加速推理。
模型量化在卷积神经网络中已经比较成熟,在NLP领域也还处于新兴阶段,未来应该会有更多相关的工作。
Paragoger衍生者AI训练营。发布者:稻草人,转载请注明出处:https://www.shxcj.com/archives/4239