
深度学习模型的量化是一种内存优化技术,通过牺牲一定准确性来减少内存空间。
在大型语言模型时代,量化是训练、微调和推理阶段必不可少的技术。例如,qlora 通过精心设计 4 位量化实现了显着的内存减少,将微调 650 亿参数模型的平均内存需求从超过 780GB 的 GPU 内存减少到不到 48GB,而与使用 16 位精度的完全微调基线相比,运行时或预测性能没有降低。
因此理解量化的原理对于深入研究大型语言模型至关重要,这也是本系列文章的主要目的。
本文主要对量化技术的一些基本概念进行介绍和辨析。
什么是量化
在数学和数字信号处理中,量化是指将输入值从一个大集合(通常是连续的集合)映射到一个较小的集合(通常具有有限个元素)的过程,类似于算法领域中的离散化技术。
深度学习中模型量化的主要任务是将神经网络中的高精度浮点数转换为低精度数。
模型量化的本质是函数映射。
通过用更少的位表示浮点数据,模型量化可以减小模型的大小,从而减少推理过程中的内存消耗。它还可以提高能够执行更快低精度计算的处理器的推理速度。
例如,图 1 表示将 32 位精度浮点向量 [0.34, 3.75, 5.64, 1.12, 2.7, -0.9, -4.7, 0.68, 1.43] 量化为 int8 定点数。使用函数映射,一个可能的量化结果是:[64, 134, 217, 76, 119, 21, 3, 81, 99]:
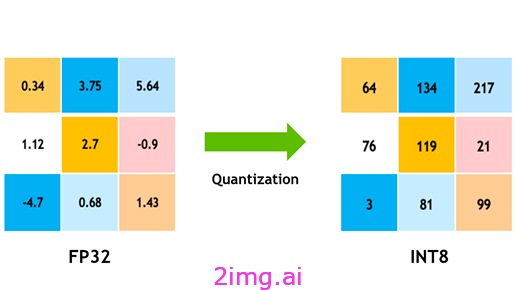

浮点数和定点数
定点数
定点数的小数点位置在计算机存储中是预先确定的,固定的。小数的整数部分和小数部分分别转换成二进制表示。
例如十进制数 25.125
- 整数部分:十进制数25转为二进制表示为:11001
- 小数部分:十进制数0.125二进制表示为:.001
- 因此,十进制数25.125以二进制表示为11001.001。
在8位计算机中,前5位表示十进制数的整数部分,后3位表示小数部分。小数点假定在第五位之后。
用11001001来表示十进制数25.125,看似完美,也容易理解,但问题是,在8位计算机中,整数部分最多只能表示31(十进制),小数部分最多只能表示0.875,数据表示范围太小了。
当然,在 16 位计算机中,增加整数部分的位数可以表示更大的数,增加小数部分的位数可以提高小数的精度。但这种方式对计算机来说成本很高,所以大多数计算机不选择对小数使用定点表示,而是采用浮点表示。
浮点数字
浮点数是具有不固定小数点的数字,能够表示各种数据,包括整数和小数。
继续前面的例子,我们可以使用 IEEE-754 浮点转换器将 25.125 转换为 32 位浮点数:
0 10000011 10010010000000000000000,如图2所示:

我们先来看一下IEEE-754浮点标准,如图3所示:
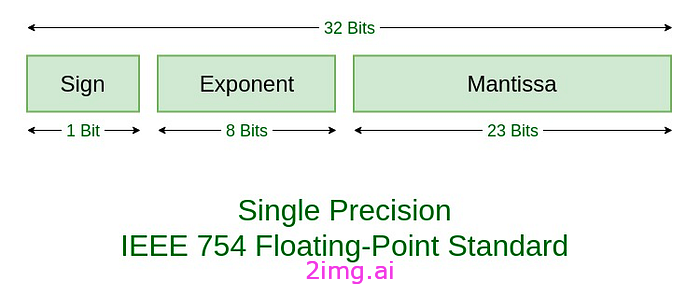
具体来说,IEEE 754 有3个基本组成部分:
- 尾数符号:顾名思义,就是0代表正数,1代表负数。
- 偏置指数:指数字段需要表示正指数和负指数。将偏置添加到实际指数中以获得存储的指数。
- 规范化尾数:尾数是科学计数法或浮点数的一部分,由其有效数字组成。这里我们只有 2 位数字,即 O 和 1。因此规范化尾数是小数点左边只有一个 1 的尾数。
现在的问题是如何将 25.125 转换为 0 10000011 10010010000000000000000 ?从定点数部分,我们知道:
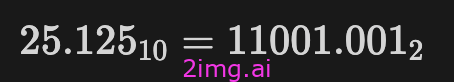
和

因此,我们可以在 1001001 后面附加 0 来获得标准化尾数 10010010000000000000000。
将指数 4 添加到偏差 127 可得出
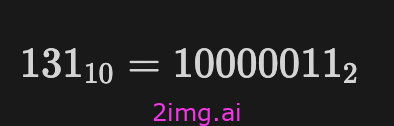
因此偏差指数部分是 10000011。
添加 0 的符号,完整的表示形式为 0 10000011 100100100000000000000000。
定点数与浮点数的比较
- 在计算机上用同样的位数表示数据时,浮点数能表示的数据范围比定点数大得多。
- 在计算机上用相同位数表示数据时,浮点数的相对精度高于定点数。
- 浮点数在计算时需要计算指数和尾数,且结果需要进行归一化处理,因此浮点运算比定点运算步骤更多,计算速度较慢。
- 目前,大多数计算机都使用浮点数来表示小数。
模型量化的对象
主要包括以下几个方面:
- 权重:量化权重是最常见和最流行的方法,它可以减少模型大小、内存使用量和空间占用。
- 激活:在实践中,激活通常占据内存使用的大部分。因此,量化激活不仅可以大大减少内存使用,而且与权重量化相结合,可以充分利用整数计算来实现性能提升。
- KV 缓存:量化 KV 缓存对于提高长序列生成的吞吐量至关重要。
- 梯度:相比于上面,梯度稍微不那么常见,因为它主要用于训练。在训练深度学习模型时,梯度通常是浮点数。它们主要用来减少分布式计算中的通信开销,也可以减少反向传播过程中的成本。
结论
本文主要讲解了模型量化、定点数和浮点数的概念,以及模型量化的对象。
本系列后续文章主要介绍常见的量化方法、模型量化的阶段、模型量化的粒度以及大型语言模型量化的最新技术。
RA/SD 衍生者AI训练营。发布者:稻草人,转载请注明出处:https://www.shxcj.com/archives/4218