

在在先进人工智能时代,理解并有效利用生成式人工智能——大型语言模型(LLM)是至关重要的技能。大型语言模型彻底改变了我们与文本交互的方式,使我们能够以前所未有的复杂程度交流、分析和生成内容。请与我一起阅读本文,揭开对大型语言模型和 Transformer 架构模型的基本理解。
了解 LLM 基础知识
在深入研究大模型 (LLM) 的复杂性之前,务必要打下坚实的基础,了解基本概念。这包括了解以下内容:
什么是生成式人工智能?
生成式人工智能是传统机器学习的一个子集。生成式人工智能所依赖的机器学习模型通过在最初由人类生成的海量内容数据集中寻找统计模式来学习这些能力。
什么是大模型 (LLM)?
LLM 代表大型语言模型,是深度学习模型领域的一个分支。LLM 是在海量文本和代码数据集上训练的神经网络模型,其特点是规模庞大,通常拥有数百亿个参数。大型语言模型经过数周和数月的训练,使用大量计算能力对数万亿个单词进行了训练。我们将其称为基础模型 (FM)。
LLM 能力是什么?
LLM 以其出色的性能而闻名,在各种自然语言任务中表现出色。LLM 拥有一系列非凡的能力,并且每天都在增长。它们旨在理解和生成类似人类的语言,并且具有广泛的应用范围,包括:
ParagogerAI训练营 2img.ai
- 自然语言理解 (NLU): LLM 可以理解和解释自然语言的细微差别,使他们能够理解文本数据中的上下文、情感和语义。
- 文本生成: LLM 能够生成连贯且上下文相关的文本,这使其对于内容创建、文章写作和创意写作等任务很有价值。
- 翻译:大模型擅长语言翻译任务,能够在不同语言之间提供准确且上下文感知的翻译。
- 摘要:这些模型可以将大量文本提炼为简洁而有意义的摘要,有助于信息提取和文档摘要。
- 问答:大模型可以利用他们对上下文和知识的理解来回答自然语言提出的问题。
- 情感分析: LLM 可以分析文本数据中表达的情感,确定语气是积极的、消极的还是中性的。
- 命名实体识别 (NER):识别和分类文本中的实体(例如人名、组织、地点等)是 LLM 的另一个优势。
- 对话式人工智能: LLM 可用于对话代理、聊天机器人和虚拟助手,通过理解和生成自然语言响应提供类似人类的交互。
- 代码生成:一些 LLM 能够熟练地根据自然语言描述生成代码片段,从而促进编程任务的完成。
- 多模态能力:在某些情况下,LLM 表现出理解和生成跨多种模态内容的能力,包括文本、图像和潜在的音频。例如:Google Gemini多模态模型
什么是提示词工程?
提示工程是为 LLM 制定有效提示以提高其预期性能的过程。它涉及精确和战略性的技术,以微调提供给 ML 模型的输入,以引出更准确和相关的响应。在上下文窗口内提供示例称为上下文学习。
有效的提示工程需要了解模型的功能和局限性,从而允许用户优化交互并充分利用大型语言模型的潜力,用于从内容创建到自然语言处理任务中的问题解决等各种应用。
探索 LLM 架构
有几种不同的 LLM 架构,每种都有自己的优点和缺点。一些最受欢迎的 LLM 架构包括:
- GPT-3 和 BERT 等Transformer模型因其处理长文本序列的能力和在各种 NLP 任务中的出色表现而闻名。
- 循环神经网络 (RNN)模型(例如 LSTM 和 GRU)非常适合需要顺序处理的任务,例如语言生成和机器翻译。
- 卷积神经网络 (CNN)模型(例如计算机视觉中使用的模型)可以通过将文本视为字符或单词序列来适应 NLP 任务。
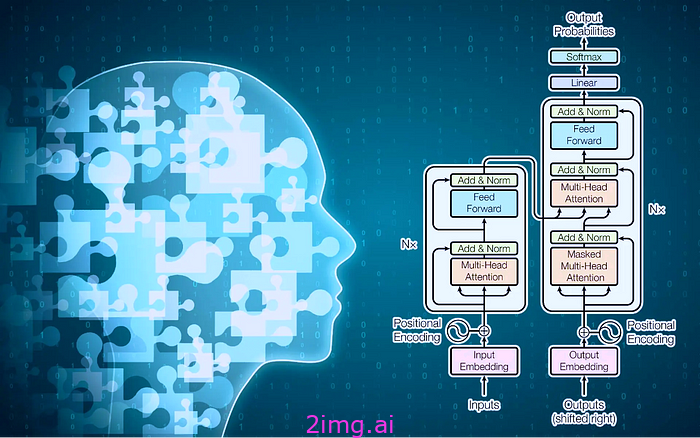
Transformer 模型架构
Transformer 架构彻底改变了自然语言处理 (NLP) 任务。它最初由 Google 研究人员在 2017 年的论文“ Attention is All You Need ”中提出。
与传统的序列到序列模型 (RNN) 不同,Transformer 依赖于自注意力机制,从而实现对输入序列的自然语言并行处理。Transformer 架构的强大之处在于能够学习句子中所有单词的相关性和上下文,并生成连贯且与上下文相关的响应。
Transformer 用于以下任务:
- 总结文本
- 将文本从一种语言翻译成另一种语言
- 根据查询从文本语料库中检索相关信息
- 对图像进行分类。
查看这篇研究论文:你所需要的就是注意力
你所需要的只是注意力:Transformer 架构详解
传统模型使用循环神经网络(RNN)或卷积神经网络(CNN)来处理序列。Transformer 摒弃了这些,完全依赖注意力机制,从而创建了一个更简单、更强大的架构。
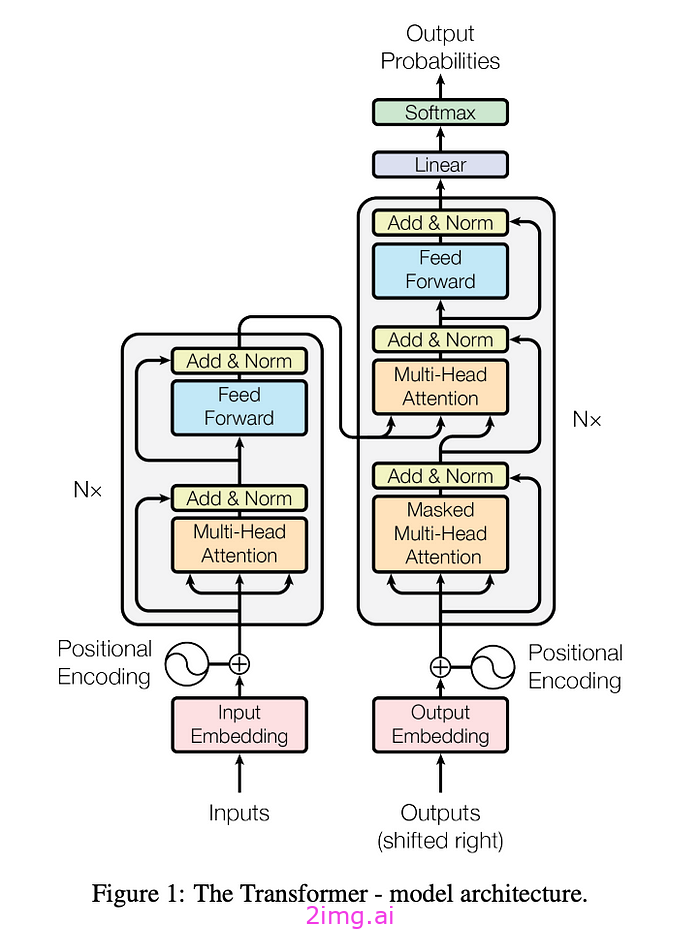
图片来源于https://arxiv.org/abs/1706.03762
注意力机制:
想象一下你正在阅读一个句子。你不会对每个单词都给予同等的关注;你会根据上下文选择性地关注相关单词。注意力机制的工作原理类似。它涉及三个部分:
- 查询:表示当前正在处理的元素(例如,您关注的单词)。
- 键值对:表示输入序列中的每个元素(例如,句子中的其他单词)。
- 注意力得分:通过将查询与每个键进行比较来计算。分数越高,表示当前元素与相应键之间的相关性越强。根据这些分数,注意力机制会选择性地关注输入序列的相关部分,并结合它们的值来创建更具信息量的表示。
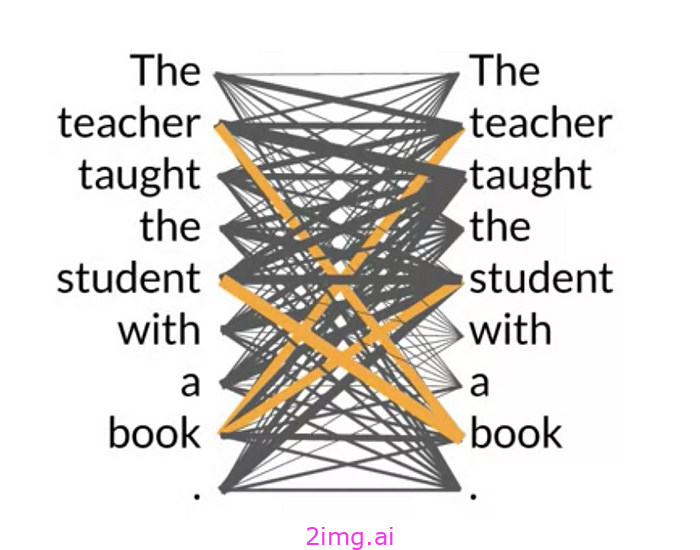
图片来源:DeepLearning.AI ParagogerAI训练营 2img.ai
正如我们在上面架构图中所看到的,Transformer 使用多个编码器层和解码器层堆叠在一起。
编码器层:
Transformer 的编码器组件由多个具有一致结构的层组成。这些层包括以下组件:
- 多头自注意力
- 前馈神经网络
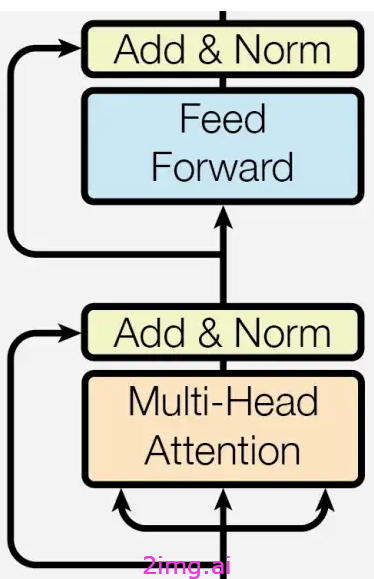
每个模块后面都有层规范化和残差连接。通过将输入序列传递到这些层,可以转换每个 token 的表示。
- 每一层都使用自我注意力,这意味着模型关注输入序列的不同部分来理解单词之间的关系。
- 还有一个学习型的多层神经网络,可以对每个单独的标记执行非线性变换。
当输入序列经过多个连续的相同结构层处理后,得到的输出序列将具有相似的长度,并包含每个 token 的上下文感知表示。这是通过规范化、残差连接和转换过程中涉及的各个模块的综合作用实现的。
ParagogerAI训练营 2img.ai
解码器层:
解码器由多个相同的层组成。每层包括以下组件:
- 掩蔽多头注意力机制
- 多头注意力机制
- 前馈神经网络
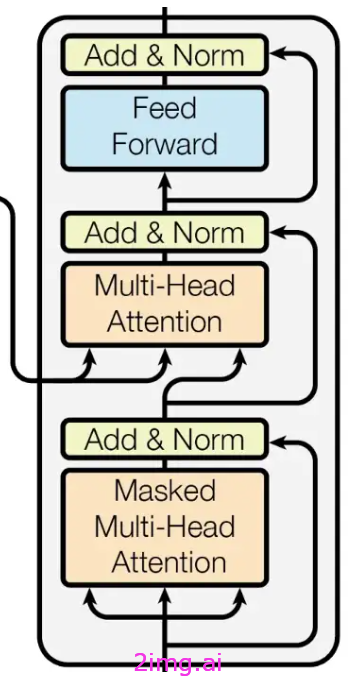
蒙版多头自注意力机制可确保模型不会在输入序列中“向前看”,从而帮助执行序列到序列任务(如语言翻译)。这意味着解码器中的每个标记仅根据输入序列中位于其之前的标记进行调整。
多头自注意力并行执行多个独立的自注意力计算,每个计算都有自己的参数。这可以改善输入的表示,并有助于捕获序列中标记之间的多种不同关系。
前馈神经网络(FFN)对多头自注意力组件的输出应用线性变换,然后应用激活函数。在可用的各种激活函数中,整流线性单元(ReLU)和高斯误差线性单元(GELU)是两种流行的选择。
FFN 进一步转换表示并通过层规范化传递最终结果。
最后,将残差连接添加到层归一化组件的输出中。此连接有助于解决训练期间的梯度消失问题,该问题会对训练结果产生重大的负面影响。残差连接有助于保留原始信息并有助于防止过度拟合。
这些模块的组合构成了解码器层。解码器的最终输出是序列中每个标记的上下文感知表示。
Gif 来源于 Google AI BlogPage ParagogerAI训练营 2img.ai
常见的 Transformer 架构
以下是一些最常见的 LLM 架构的简要概述:
- GPT(生成式预训练变压器):GPT 由 OpenAI 开发,是一种基于变压器的 LLM,以生成连贯且逼真的文本的能力而闻名。
- BERT(来自 Transformers 的双向编码器表示):BERT 由 Google AI 开发,是一种基于 Transformer 的 LLM,对于需要理解句子中单词上下文的任务特别有效。
- XLNet(用于语言理解的广义自回归预训练):XLNet 由 Google AI 开发,是一种基于变压器的 LLM,结合了自回归和自动编码模型的优势。
- RoBERTa(稳健优化 BERT 方法):由 Facebook AI Research(FAIR)开发的 RoBERTa 是 BERT 的一种变体,它在更大的数据集上进行训练,并具有更多的训练步骤。
Transformer 架构模型优势:
- 并行化: Attention 允许并行处理,使得 Transformer 的训练速度比基于 RNN 的模型更快。
- 长距离依赖关系:得益于自我注意力,模型可以有效地捕捉单词之间的长距离关系。
- 最佳成果: Transformer 在机器翻译、摘要和问答等各种 NLP 任务中取得了显著的进步。
Paragoger衍生者AI训练营。发布者:稻草人,转载请注明出处:https://www.shxcj.com/archives/4162