
介绍
向量数据库已成为存储和索引非结构化和结构化数据表示的首选。这些表示称为向量嵌入,由嵌入模型生成。向量存储在利用深度学习模型(尤其是大型语言模型)的应用程序开发中起着至关重要的作用。
什么是矢量数据库?
在现实世界中,并非所有数据都能整齐地排列在行和列中。在处理图像、视频和自然语言等复杂的非结构化数据时尤其如此。这就是矢量数据库的作用所在。
矢量数据库是一种将数据存储为高维矢量的数据库,高维矢量本质上是代表对象特征或特性的数字列表。每个矢量对应一个唯一实体,例如一段文本、一张图片或一段视频。
但为什么要使用向量呢?神奇之处在于它们能够捕捉语义和相似性。通过将数据表示为向量,我们可以用数学方法比较它们,并确定它们的相似性或不相似性。这使我们能够执行复杂的查询,例如“找到与此相似的图像”或“检索与此文本在语义上相关的文档”。
为什么矢量数据库如此受欢迎?
近年来,矢量数据库越来越受欢迎,尤其是在机器学习 (ML) 和人工智能 (AI) 领域。AI 和 ML 模型的复杂性要求有有效的方法来存储、搜索和检索它们处理的大量非结构化数据。
矢量数据的复杂性和大小通常对于为结构化数据构建的传统数据库来说太大。相反,矢量数据库是专门为此设计的。它们提供专门的搜索和索引算法,即使在包含数十亿条条目的数据库中,也可以快速找到可比较的矢量。
矢量数据库的不同用例
通过寻找可比向量的能力,AI 和 ML 的应用得到了极大的扩展。典型的用例包括以下内容:
- RAG 系统:向量数据库可以与大型语言模型 (LLM) 结合在一起,构建基于知识的语言 AI 应用程序。
- 推荐系统:高度个性化的推荐引擎可以由向量数据库提供支持,该数据库将用户偏好和项目属性表示为向量。
- 矢量数据库通过搜索视觉相关的图像或视频彻底改变了基于内容的检索。
- 自然语言处理:向量数据库通过将文本转换为向量来提供语义搜索、主题建模和文档分组。
- 欺诈检测:为了协助识别金融交易中的趋势和异常,可以使用矢量数据库。
矢量数据库的比较
目前有许多矢量数据库,例如 Qdrant、Pinecone、Milvus、Chroma、Weaviate 等。每个数据库都有自己的优势、权衡和理想用例。在这里,我们将深入全面比较流行的矢量数据库,包括 Pinecone、Milvus、Chroma、Weaviate、Faiss、Elasticsearch 和 Qdrant。
部署选项
在这方面,Pinecone 是个例外。由于 Pinecone 出于性能和可扩展性原因而提供完全托管服务,因此您无法在本地运行实例。Milvus、Chroma、Weaviate、Faiss、Elasticsearch 和 Qdrant 都可以在本地运行;大多数都提供了 Docker 镜像。


可扩展性
Qdrant 提供静态分片;如果您的数据超出了服务器的容量,您将需要向集群添加更多机器并重新分片所有数据。这可能是一个耗时且复杂的过程。此外,不平衡的分片可能会造成瓶颈并降低系统效率。
Pinecone 通过 Serveless Tier 支持计算和存储分离。对于基于 POD 的集群,Pinecone 采用静态分片,这要求用户在扩展集群时手动重新分片数据。
Weaviate 提供静态分片。没有任何分布式数据替换,Chroma 无法扩展到单个节点之外

性能基准测试
- 卡德兰特无论我们选择的精度阈值和指标如何,在几乎所有场景中都能实现最高的 RPS 和最低的延迟。它还在其中一个数据集上显示了 4 倍的 RPS 增益。
- Elasticsearch 在许多用例中已经变得相当快,但在索引时间方面却非常慢。存储 10M+ 96 维向量时,速度可能会慢 10 倍!(32 分钟 vs 5.5 小时)
- Milvus 在索引时间方面是最快的,并且保持了良好的精度。但是,当您拥有更高维度的嵌入或更多向量时,它在 RPS 或延迟方面不如其他产品。
- Redis 能够实现良好的 RPS,但精度较低。它还通过单线程实现了低延迟;然而,随着并行请求的增多,其延迟会迅速上升。速度提升的部分原因在于其自定义协议。
- Weaviate 的改进最少。由于其他引擎的相对改进,它在 RPS 和延迟方面已成为最慢的引擎之一。

数据管理

向量相似性搜索
矢量数据库如此有用的原因之一是它们可以告诉我们事物之间的关系以及它们之间的相似性或不相似性。有多种距离度量允许矢量数据库执行此操作,并且不同的矢量数据库将实现不同的距离度量。

集成和 API
虽然 REST API 更常见,但 GRPC API 更注重延迟关键场景或需要快速移动大量数据时的性能和吞吐量。根据您的要求和网络,GRPC 可能比 REST 快几倍。

社区和生态系统
开源意味着我们可以浏览核心数据库的源代码,并且向量数据库具有灵活的许可模型。

价钱

元数据过滤
元数据是一个极其强大的概念,它与核心矢量数据库功能相得益彰;它是模糊的人类语言与结构化数据之间的纽带。这是架构的基础,人类用户询问产品时,AI 购物助手会立即回复他们所描述的商品。

矢量数据库功能
- Qdrant: Qdrant 使用三种类型的索引来支持其数据库。这三种索引分别是 Payload 索引(类似于传统面向文档的数据库中的索引)、字符串 Payload 的全文索引和向量索引。他们的混合搜索方法是向量搜索与属性过滤的结合。
- Pinecone: RBAC 对于大型组织来说还不够。存储优化 (S1) 存在一些性能挑战,只能获得 10-50 QPS。命名空间的数量是有限的,用户在使用元数据过滤作为绕过此限制的方法时应小心谨慎,因为这会对性能产生很大影响。此外,这种方法不提供数据隔离。
- Weaviate: Weaviate 使用两种类型的索引来支持其数据库。倒排索引将数据对象属性映射到其在数据库中的位置,向量索引支持高性能查询。此外,其混合搜索方法使用密集向量来理解查询的上下文,并将其与稀疏向量相结合以进行关键字匹配。
- Chroma:Chroma 使用 HNSW 算法支持 kNN 搜索。
- Milvus: Milvus 支持多个内存索引和表级分区,从而满足实时信息检索系统所需的高性能。RBAC 支持是企业级应用程序的必要条件。关于分区,通过将搜索限制在数据库的一个或多个子集,分区可以提供一种比静态分片更有效的数据过滤方式,静态分片可能会引入瓶颈,并且随着数据增长超出服务器容量,需要重新分片。分区是一种很好的数据管理方式,它根据类别或时间范围将数据分组为子集。这可以帮助您轻松过滤和搜索大量数据,而不必每次都搜索整个数据库。没有一种索引类型可以适合所有用例,因为每个用例都有不同的权衡。随着更多索引类型的支持,您可以更灵活地找到准确性、性能和成本之间的平衡。
- Faiss: FAISS 是一种支持 kNN 搜索的算法
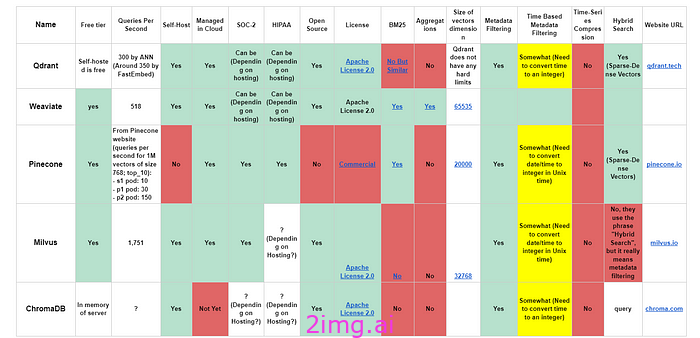
总体比较总结
为什么选择 Qdrant
Qdrant 提供一款以 Rust 构建的生产就绪服务,Rust 是一种以安全性著称的语言。Qdrant 附带一个用户友好的 API,旨在存储、搜索和管理高维点(点只不过是矢量嵌入),这些点富含元数据(称为有效载荷)。这些有效载荷成为有价值的信息,可提高搜索精度并为用户提供有洞察力的数据。如果您熟悉其他矢量数据库(如 Chroma),则有效载荷类似于元数据;它包含有关矢量的信息。
由于使用 Rust 编写,Qdrant 即使在高负载下也能成为快速可靠的向量存储。Qdrant 与其他数据库的不同之处在于它提供的客户端 API 数量。目前,Qdrant 支持 Python、TypeSciprt/JavaScript、Rust 和 Go。它使用 HSNW(分层可导航小世界图)进行向量索引,并附带许多距离指标,如余弦、点和欧几里得。它附带一个开箱即用的推荐 API。
考虑 Qdrant 时的一些关键要点包括:
- Qdrant 采用 Rust 编写,即使在高负载下也能确保速度和可靠性,是高性能矢量存储的最佳选择。
- Qdrant 的独特之处在于它支持客户端 API,可满足 Python、TypeScript/JavaScript、Rust 和 Go 开发人员的需求。
- Qdrant 利用 HSNW 算法并提供不同的距离度量,包括点、余弦和欧几里得,使开发人员能够选择符合其特定用例的度量。
- Qdrant 可通过可扩展的云服务无缝过渡到云,提供免费层级选项供您探索。其云原生架构可确保最佳性能,无论数据量如何。
Qdrant 的优势
- 高效相似搜索 — Qdrant 专为相似搜索操作而设计。它可以非常快速准确地在大量数据中查找相似的嵌入。
- 可扩展性——Qdrant 具有可扩展性,因为它可以有效地处理大量向量。
- 易于使用——Qdrant 数据库提供了用户友好的 API,可以轻松设置、插入数据和执行类似的搜索。
- 开源——Qdrant 是一个开源项目,这意味着我们可以访问源代码并可以为其开发做出贡献。
- 灵活性——Qdrant 数据库支持灵活的 Schema,这意味着我们可以定义不同类型的矢量场,还可以存储和搜索不同类型的数据,如图像、文本、音频等。
结论
Qdrant 是一款功能强大的工具,可帮助企业释放语义嵌入的强大功能并彻底改变文本搜索。它提供了一种可靠且可扩展的解决方案来管理高维数据,具有出色的查询性能和易于集成的特点。其开源数据库允许持续开发、修复错误并进行改进。
Qdrant 提供灵活的部署选项(自托管或云管理)、高性能、对矢量维度没有硬性限制、元数据过滤、混合搜索功能以及免费的自托管版本。
Paragoger衍生者AI训练营。发布者:稻草人,转载请注明出处:https://www.shxcj.com/archives/4103