
通常,LLM 会接受大量数据的训练,这让他们有广泛的理解,但可能会导致特定知识领域的空白。有时,他们甚至可能会产生偏离目标或有偏见的信息——这是从广阔的、未经过滤的网络中学习的副产品。为了解决这个问题,我们引入了矢量数据库的概念。这些数据库以一种称为“矢量嵌入”的独特格式存储数据,这使 LLM 能够更准确地掌握和利用信息。
本指南介绍如何使用矢量数据库构建 LLM 并改进 LLM 对此流程的使用。我们将研究如何将这两者结合起来,使 LLM 更加准确和实用,尤其是针对特定主题。
接下来,我们将简要概述矢量数据库,解释矢量嵌入的概念及其在增强 AI 和机器学习应用中的作用。我们将向您展示这些数据库与传统数据库的不同之处,以及它们为何更适合 AI 驱动的任务,尤其是在处理文本、图像和复杂模式等非结构化数据时。
此外,我们将探索这项技术在构建封闭式问答机器人方面的实际应用。这款机器人由 Falcon-7B 和 ChromaDB 提供支持,展示了 LLM 与正确的工具和技术结合时的有效性。
在本指南结束时,您将更清楚地了解如何利用 LLM 和矢量数据库的强大功能来创建不仅具有创新性而且具有情境感知能力和可靠性的应用程序。无论您是 AI 爱好者还是经验丰富的开发人员,本指南都经过量身定制,可帮助您轻松自信地驾驭这个令人兴奋的领域。


矢量数据库简介
在深入了解向量数据库之前,了解向量嵌入的概念至关重要。向量嵌入在机器学习中至关重要,用于将原始数据转换为 AI 系统可以理解的数字格式。这涉及将文本或图像等数据转换为高维空间中的一系列数字(称为向量)。高维数据是指具有许多属性或特征的数据,每个属性或特征代表不同的维度。这些维度有助于捕捉数据的细微特征。
创建向量嵌入的过程从输入数据开始,输入数据可以是任何内容,从句子中的单词到图像中的像素。大型语言模型和其他 AI 算法会分析这些数据并识别其关键特征。例如,在文本数据中,这可能涉及理解单词的含义及其在句子中的上下文。然后,嵌入模型将这些特征转换为数字形式,为每段数据创建一个向量。向量中的每个数字代表数据的特定特征,这些数字一起以机器可以处理的格式封装了原始输入的本质。
这些向量是高维的,因为它们包含许多数字,每个数字对应于数据的不同特征。这种高维性使向量能够捕获复杂、详细的信息,使其成为 AI 模型的强大工具。模型使用这些嵌入来识别数据中的模式、关系和底层结构。
矢量数据库经过精心设计,可提供针对矢量嵌入的独特性质而量身定制的优化存储和查询功能。它们擅长通过比较和识别数据点之间的相似性来提供高效的搜索功能、高性能、可扩展性和数据检索。
这些复杂高维信息的数字表示形式使矢量数据库有别于主要以文本和数字等格式存储数据的传统系统。它们的主要优势在于管理和查询图像、视频和文本等数据类型,当这些数据被转换为矢量格式以用于机器学习和人工智能应用时,它们尤其有用。
在下图中,我们展示了将文本转换为词向量的过程。此步骤是自然语言处理的基础,使我们能够量化和分析语言关系。例如,“小狗”的向量表示在向量空间中的位置与“狗”的位置比与“房子”的位置更近,这反映了它们的语义接近性。这种方法也适用于类比关系。“男人”和“女人”之间的向量距离和方向可以类比“国王”和“女王”之间的向量距离和方向。这说明了词向量不仅可以表示单词,还可以在多维向量空间中对它们的语义关系进行有意义的比较。
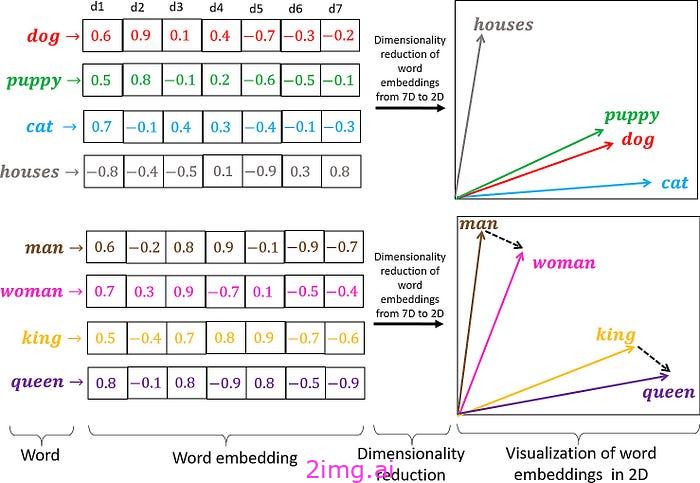
LLM 兴起之前的矢量数据库
矢量数据库旨在处理矢量嵌入,有几个关键用例,特别是在机器学习和人工智能领域:
相似性搜索:这是矢量数据库擅长的核心功能。它们可以在高维空间中快速找到与给定查询相似的数据点。这对于图像或音频检索等应用程序至关重要,因为您希望在其中找到与特定输入相似的项目。以下是一些行业用例示例:
- 电子商务:通过允许客户搜索视觉上与参考图像相似的产品来增强产品发现。
- 音乐流媒体服务:查找并推荐具有与用户最喜欢的曲目相似的音频特征的歌曲。
- 医疗成像:通过检索显示类似病理的医学图像(如 X 射线或 MRI)来协助放射科医生进行比较分析。
推荐系统:向量数据库通过处理用户和项目嵌入来支持推荐系统。它们可以将用户与与他们的兴趣或过去互动最相似的项目(如产品、电影或文章)进行匹配。以下是一些行业用例:
- 流媒体平台:根据观众的观看历史推荐电影和电视节目,提供个性化观看体验。
- 在线零售商:根据购物者的浏览和购买历史向他们推荐产品,增强交叉销售和追加销售的机会。
- 新闻聚合器:通过将文章与读者过去的参与模式和偏好进行匹配来提供个性化的新闻提要。
基于内容的检索:在此,矢量数据库用于根据内容的实际内容而不是传统元数据来搜索内容。这对于文本和图像等非结构化数据尤其重要,因为需要分析内容本身才能进行检索。以下是一些行业用例:
- 数字资产管理:通过基于视觉或音频内容特征搜索和检索图像或视频,使公司能够管理庞大的数字媒体库。
- 法律与合规:搜索大量文档以查找与法律案件或合规查询相关的特定信息或文档。
- 学术研究:帮助研究人员找到与其工作内容相似的学术文章和研究论文,即使没有提到特定的关键词。
关于基于内容的检索的最后一点越来越重要,并促进了一种新颖的应用:
通过上下文理解增强 LLM:通过存储和处理文本嵌入,向量数据库使 LLM 能够执行更细致入微且上下文感知的信息检索。它们有助于理解大量文本的语义内容,这对于回答复杂查询、维护对话上下文或生成相关内容等任务至关重要。此应用程序正迅速成为向量数据库的一个突出用例,展示了它们增强 LLM 等高级 AI 系统功能的能力。
矢量数据库与传统数据库
传统 SQL 数据库擅长结构化数据管理,依靠精确匹配和定义明确的条件逻辑而蓬勃发展。它们保持数据完整性,适合需要精确、结构化数据处理的应用程序。然而,它们僵化的架构设计使它们不太能适应非结构化数据的语义和上下文细微差别,而这在 LLM 和生成式 AI 等 AI 应用程序中至关重要。
另一方面,与传统 SQL 系统相比,NoSQL 数据库提供了更大的灵活性。它们可以处理半结构化和非结构化数据,例如 JSON 文档,这使得它们在某种程度上更适合 AI 和机器学习用例。尽管如此,即使是 NoSQL 数据库在处理 LLM 和生成式 AI 所必需的复杂高维矢量数据的某些方面也存在不足,这通常涉及解释上下文、模式和语义内容,而不仅仅是简单的数据检索。
矢量数据库填补了这一空白。它们专为以 AI 为中心的场景量身定制,将数据处理为矢量,从而能够有效地管理非结构化数据的复杂性。在使用 LLM 时,矢量数据库支持相似性搜索和上下文理解等操作,提供超越传统 SQL 和灵活的 NoSQL 数据库的功能。它们在处理近似值和模式识别方面的熟练程度使它们特别适合 AI 应用程序,因为在这些应用程序中,细致入微的数据解释比检索精确的数据匹配更重要。
提高矢量数据库性能
对于依赖快速、准确检索高维数据的应用程序来说,优化矢量数据库的性能非常重要。这涉及提高查询速度、确保高精度以及保持可扩展性,以有效处理不断增长的数据量和用户请求。这种优化的一个重要部分围绕索引策略展开,索引策略是用于更有效地组织和搜索矢量数据的技术。下面,我们将详细介绍这些索引策略以及它们如何有助于提高矢量数据库的性能。
索引策略
向量数据库中的索引策略旨在帮助快速准确地检索与查询向量相似的向量。这些策略可以极大地影响搜索操作的速度和准确性。
- 量化:量化涉及将向量映射到向量空间中的一组有限参考点,从而有效地压缩向量数据。此策略通过将搜索限制在参考点的子集而不是整个数据集来降低存储要求并加快搜索过程。量化有多种形式,包括标量量化和矢量量化,每种量化都在搜索速度和准确性之间进行权衡。
对于管理大规模数据集的应用来说,量化尤其有效,因为存储和内存效率至关重要。量化在查询速度和准确度之间可以取得平衡的环境中表现出色,非常适合对速度敏感且可以容忍一定程度的精度损失的应用。但是,由于数据压缩和搜索精度之间存在固有的权衡,因此不太推荐用于要求最高准确度和最小信息损失的用例(例如精确的科学研究)。
- 分层可导航小世界 (HNSW)图:HNSW 是一种索引策略,它构建了一个分层图,其中每一层代表数据集的不同粒度。搜索从顶层开始,该层包含较少、较远的点,然后向下移动到更详细的层。这种方法允许快速遍历数据集,通过快速缩小相似向量的候选集,显著缩短了搜索时间。
HNSW 图在查询速度和准确性之间实现了极好的平衡,非常适合需要即时响应时间的实时搜索应用程序和推荐系统。它们在处理中大型数据集时表现良好,可提供可扩展的搜索功能。但是,它们的内存消耗可能会成为极大数据集的限制,因此它们不太适合内存资源受限或数据集大小明显超出实际内存容量的情况。
- 倒排索引 (IVF):IVF 方法使用 k-means 等算法将向量空间划分为预定义数量的簇。每个向量被分配到最近的簇,并且在搜索期间,仅考虑最相关簇中的向量。此方法缩小了搜索范围,提高了查询速度。将 IVF 与其他技术(例如量化(产生 IVFADC — 具有非对称距离计算的倒排索引))相结合,可以通过降低距离计算的计算成本来进一步提高性能。
建议使用倒排文件索引 (IVF) 方法处理可扩展搜索环境中的高维数据,通过对类似项目进行聚类来有效缩小搜索空间。这种方法对于相对静态的数据集尤其有益,因为偶尔重新聚类的开销是可控的。但是,由于潜在的过度分割,IVF 可能不是低维数据的最佳选择,或者对于要求尽可能低延迟的应用程序来说,因为聚类过程和跨多个集群搜索的需求可能会增加查询时间。
优化的其他考虑因素
- 降维:在应用索引策略之前,降低向量的维数可能会有所帮助。PCA 或自动编码器等技术有助于保留数据的基本特征,同时降低其复杂性,从而提高索引效率和搜索操作速度。
- 并行处理:许多索引策略都可以在多核 CPU 或 GPU 上并行执行。这种并行处理能力允许同时处理多个查询,从而显著提高吞吐量并缩短大型应用程序的响应时间。
- 动态索引:对于频繁更新数据的数据库,动态索引策略至关重要,因为动态索引策略允许高效地插入和删除向量,而无需对索引进行大规模重组。这可确保数据库保持响应速度和最新状态,同时将性能随时间下降的程度降至最低。
通过这些索引策略和考虑来提高矢量数据库的性能需要深入了解底层数据和应用程序的特定要求。通过仔细选择和调整这些策略,开发人员可以显著提高其基于矢量的应用程序的响应能力和可扩展性,确保它们满足实际用例的需求。
使用矢量数据库丰富大語言模型 (LLM) 内容
大型语言模型 (LLM),例如 Facebook 的LLama2或 TIIUAE 的Falcon,凭借其类似人类的文本生成能力,具有显著先进的 AI 能力。然而,由于它们在广泛的通用数据集上进行训练,因此在处理专业上下文方面面临挑战。
解决上下文限制主要有两种方式:
- 有针对性的训练:这涉及在专注于特定领域的数据集上重新训练或微调 LLM。虽然这种方法可以显著提高模型在特定主题或行业中的专业知识,但对于许多组织或个人来说,这往往是不可行的。原因包括与训练所需的计算资源相关的高成本以及有效重新训练此类复杂模型所需的专业知识:有效地重新训练 LLM 需要深入了解机器学习、自然语言处理以及相关模型的特定架构。
- 通过向量数据库整合上下文:或者,可以使用来自向量数据库的数据,直接将上下文添加到 LLM 的提示中,从而增强 LLM 的能力。在此设置中,向量数据库将专门的信息存储为向量嵌入,LLM 可以检索并使用它们来增强其响应。这种方法允许纳入相关的专业知识,而无需进行大量的再培训。对于缺乏有针对性培训资源的组织或个人来说,这种方法特别有用,因为它利用了现有的模型功能,同时提供了有针对性的上下文见解。
第二个选项是 RAG我们将在下一节中更详细地探讨它。
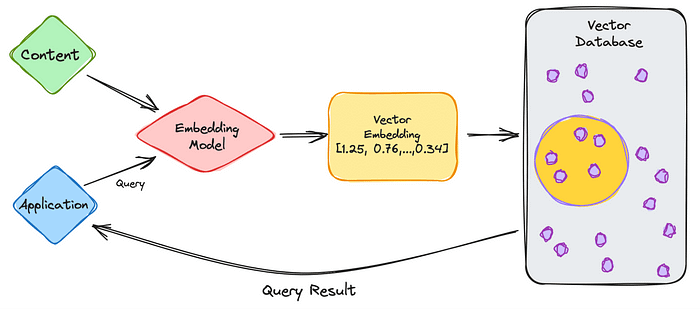
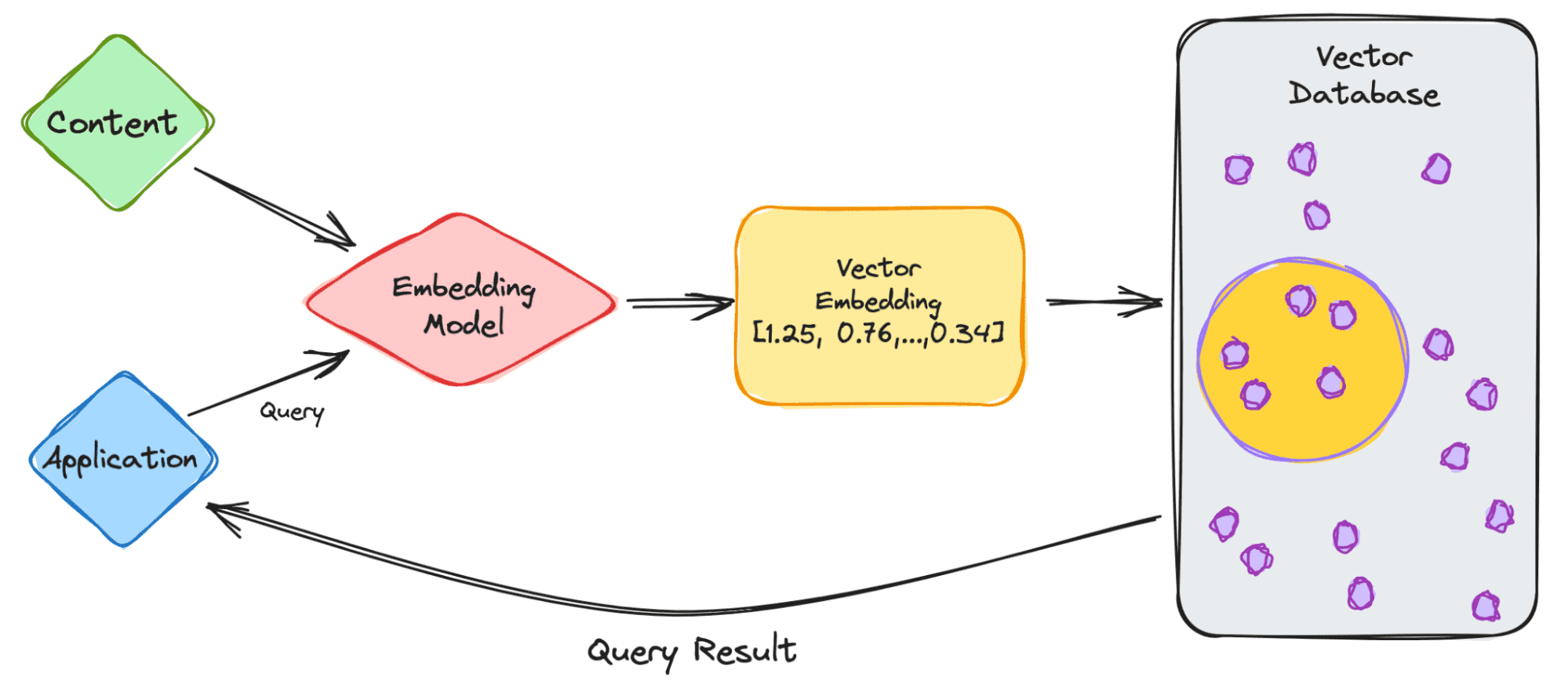{kind=link}
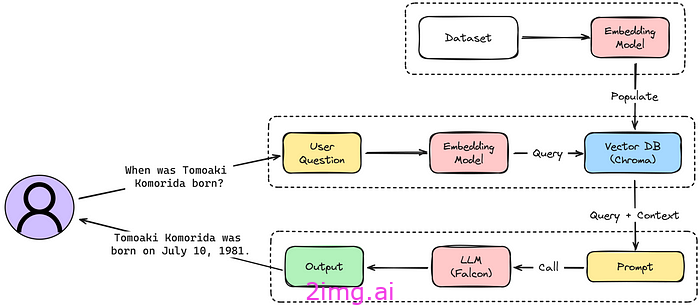
使用 Falcon-7B 和 ChromaDB 构建封闭式 QA 机器人
在本节中,我们概述了如何使用向量数据库构建 LLM 的过程。该模型是一个封闭式问答机器人。该机器人旨在使用一组集成的技术组件有效地解决与科学相关的查询:
- databricks-dolly-15k HuggingFace 数据集:是 Databricks 员工生成的指令跟踪记录的开源数据集。它旨在训练大型语言模型 (LLM)、合成数据生成和数据增强。该数据集包括头脑风暴、分类、封闭式问答、生成、信息提取、开放式问答和总结等类别的各种提示和响应。
- Chroma 作为向量存储(知识库):我们使用 Chroma 作为我们的主要向量存储,作为我们机器人的知识库。
- 用于语义搜索的句子变换器:具体来说,我们使用句子变换器的“multi-qa-MiniLM-L6-cos-v1”模型,该模型针对语义搜索应用进行了优化。该模型负责生成存储在 Chroma 中的嵌入。
- Falcon 7B 指令模型:作为我们的开源生成模型,Falcon 7B 是一个仅解码器模型,具有 70 亿个参数。它由 TII 开发,在庞大的 1,500B 标记数据集 RefinedWeb 上进行训练,并辅以精选语料库。值得注意的是,其更大的对应模型 Falcon 40B 在 Hugging Face 的 Open LLM 排行榜上名列前茅。
设置环境
为了实现本文讨论的代码,需要进行以下安装:
!pip install -qU \
transformers==4.30.2 \
torch==2.0.1+cu118 \
einops==0.6.1 \
accelerate==0.20.3 \
datasets==2.14.5 \
chromadb \
sentence-transformers==2.2.2
该代码最初在 Qwak 的工作区上的gpu.a10.2xl 实例上运行。值得注意的是,运行 Falcon-7B-Instruct 模型所需的具体代码可能会因所使用的硬件配置而异。
构建“知识库”
首先,我们获取 Databricks-Dolly 数据集,重点关注 closed_qa 类别。这些条目通常以对精确信息的需求为特征,由于其特殊性,对一般训练的大型语言模型 (LLM) 构成了挑战。
from datasets import load_dataset
# Load only the training split of the dataset
train_dataset = load_dataset("databricks/databricks-dolly-15k", split='train')
# Filter the dataset to only include entries with the 'closed_qa' category
closed_qa_dataset = train_dataset.filter(lambda example: example['category'] == 'closed_qa')
print(closed_qa_dataset[0])
典型的数据集条目如下所示:
{
"instruction": "When was Tomoaki Komorida born?",
"context": "Komorida was born in Kumamoto Prefecture on July 10, 1981. After graduating from high school, he joined the J1 League club Avispa Fukuoka in 2000. His career involved various positions and clubs, from a midfielder at Avispa Fukuoka to a defensive midfielder and center back at clubs such as Oita Trinita, Montedio Yamagata, Vissel Kobe, and Rosso Kumamoto. He also played for Persela Lamongan in Indonesia before returning to Japan and joining Giravanz Kitakyushu, retiring in 2012.",
"response": "Tomoaki Komorida was born on July 10, 1981.",
"category": "closed_qa"
}
接下来,我们专注于为每组指令及其各自的上下文生成词嵌入,并将它们集成到我们的向量数据库 ChromaDB 中。
Chroma DB是一种开源向量存储系统,擅长管理向量嵌入。它专为语义搜索引擎等应用程序量身定制,在自然语言处理和机器学习领域至关重要。Chroma DB 的效率(尤其是作为内存数据库)有助于快速访问和操作数据,这是高速数据处理的关键。其 Python 友好设置增强了它对我们项目的吸引力,简化了与我们工作流程的集成。有关详细文档:Chroma DB 文档。
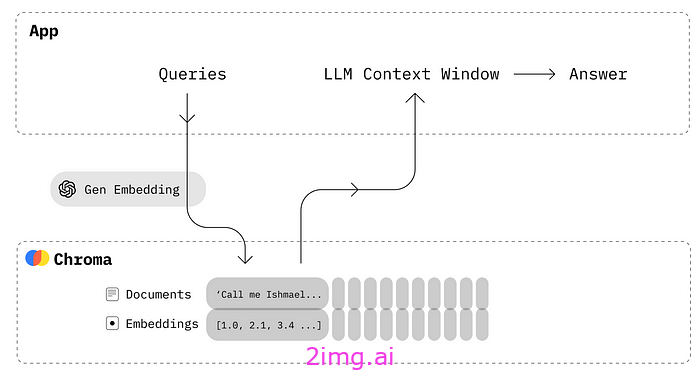
为了生成答案的嵌入,我们使用 multi-qa-MiniLM-L6-cos-v1,它已针对语义搜索用例进行了专门训练。给定一个问题/搜索查询,该模型能够找到相关的文本段落,这正是我们的目标。
在下面的示例中,我们说明了嵌入如何存储在 Chroma 的内存集合中。
import chromadb
from sentence_transformers import SentenceTransformer
class VectorStore:
def __init__(self, collection_name):
# Initialize the embedding model
self.embedding_model = SentenceTransformer('sentence-transformers/multi-qa-MiniLM-L6-cos-v1')
self.chroma_client = chromadb.Client()
self.collection = self.chroma_client.create_collection(name=collection_name)
# Method to populate the vector store with embeddings from a dataset
def populate_vectors(self, dataset):
for i, item in enumerate(dataset):
combined_text = f"{item['instruction']}. {item['context']}"
embeddings = self.embedding_model.encode(combined_text).tolist()
self.collection.add(embeddings=[embeddings], documents=[item['context']], ids=[f"id_{i}"])
# Method to search the ChromaDB collection for relevant context based on a query
def search_context(self, query, n_results=1):
query_embeddings = self.embedding_model.encode(query).tolist()
return self.collection.query(query_embeddings=query_embeddings, n_results=n_results)
# Example usage
if __name__ == "__main__":
# Initialize the handler with collection name
vector_store = VectorStore("knowledge-base")
# Assuming closed_qa_dataset is defined and available
vector_store.populate_vectors(closed_qa_dataset)
对于每个数据集条目,我们生成并存储组合的“指令”和“上下文”字段的嵌入,其中上下文充当我们的 LLM 提示中检索的文档。
接下来,我们将利用 Falcon-7b-instruct LLM 在没有额外上下文的情况下生成对封闭信息查询的响应,展示我们丰富的知识库的功效。
生成基本答案
对于我们的生成文本任务,我们将利用来自 Hugging Face 的 falcon-7b-instruct 模型的功能。该模型是阿布扎比技术创新学院开发的创新 Falcon 系列的一部分。
Falcon-7B-Instruct 的突出之处在于其在先进功能和可管理大小之间的有效平衡。它专为复杂的文本理解和生成任务而设计,性能可与更大的闭源模型相媲美,但软件包更精简。这使其成为我们项目的理想选择,因为我们需要深度语言理解,而又不需要更大模型的开销。
如果您计划在本地计算机或远程服务器上运行 Falcon-7B-Instruct 模型,请务必牢记硬件要求。正如HuggingFace 的文档中所述,该模型至少需要 16GB RAM。但是,为了获得最佳性能和更快的响应时间,强烈建议使用 GPU。
import transformers
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
class Falcon7BInstructModel:
def __init__(self):
# Model name
model_name = "tiiuae/falcon-7b-instruct"
self.pipeline, self.tokenizer = self.initialize_model(model_name)
def initialize_model(self, model_name):
# Tokenizer initialization
tokenizer = AutoTokenizer.from_pretrained(model_name)
# Pipeline setup for text generation
pipeline = transformers.pipeline(
"text-generation",
model=model_name,
tokenizer=tokenizer,
torch_dtype=torch.bfloat16,
trust_remote_code=True,
device_map="auto",
)
return pipeline, tokenizer
def generate_answer(self, question, context=None):
# Preparing the input prompt
prompt = question if context is None else f"{context}\n\n{question}"
# Generating responses
sequences = self.pipeline(
prompt,
max_length=500,
do_sample=True,
top_k=10,
num_return_sequences=1,
eos_token_id=self.tokenizer.eos_token_id,
)
# Extracting and returning the generated text
return sequences['generated_text']
基于 Hugging Face 文档构建的代码示例非常清晰且易于理解。
为了更好地理解,让我们剖析一下它的主要组成部分:
- 标记器是 Falcon-7B-Instruct 等自然语言处理 (NLP) 模型中的关键组件。其主要作用是将输入文本转换为模型可以理解的格式。本质上,它将文本分解为称为标记的较小单元。这些标记可以是单词、子单词,甚至是字符,具体取决于标记器的设计。在 Falcon-7B-Instruct 模型的上下文中,AutoTokenizer.from_pretrained(model) 调用正在加载专门设计用于此模型的标记器,确保文本的标记方式与模型的训练方式一致。
- transformers 库中的管道是一个高级实用程序,它抽象了处理数据和从模型中获取预测所涉及的大部分复杂性。它在内部处理多个步骤,例如对输入文本进行标记、将标记输入模型,然后将模型的输出处理成人类可读的形式。在此脚本中,管道设置为“文本生成”,这意味着它经过优化以接收提示(如用户问题)并根据该提示生成文本的延续。
使用示例:
# Initialize the Falcon model class
falcon_model = Falcon7BInstructModel()
user_question = "When was Tomoaki Komorida born?"
# Generate an answer to the user question using the LLM
answer = falcon_model.generate_answer(user_question)
print(f"Result: {answer}")
您可能已经猜到了,这是针对给定用户问题的模型输出:
{ answer: “I don't have information about Tomoaki Komorida's birthdate.” }
在没有补充背景的情况下使用 Falcon-7B-Instruct 会产生负面反应,因为它没有接受过这些“鲜为人知”信息的训练。这说明,在为非一般性问题生成更有针对性和更有用的答案时,需要丰富的背景。
生成情境感知答案
现在,让我们通过从向量存储中检索相关上下文来提升生成模型的能力。
有趣的是,我们使用相同的 VectorStore 类来生成嵌入和从用户问题中获取上下文:
# Assuming vector_store and falcon_model have already been initialized
# Fetch context from VectorStore, assuming it's been populated
context_response = vector_store.search_context(user_question)
# Extract the context text from the response
# The context is assumed to be in the first element of the 'context' key
context = "".join(context_response['context'][0])
# Generate an answer using the Falcon model, incorporating the fetched context
enriched_answer = falcon_model.generate_answer(user_question, context=context)
print(f"Result: {enriched_answer}")
当然,我们大語言模型给出的丰富上下文的答案是准确而迅速的:
Tomoaki Komorida was born on July 10, 1981.
總結
在我们的详细探索中,我们向您展示了如何制作一个由自定义数据集丰富而成的大型语言模型 (LLM) 应用程序。显然,管理这样的模型、试验不同的数据集、设置必要的基础设施以及实现实用的解决方案绝非易事。然而,这正是 Qwak 的闪光点,它简化了这个复杂的过程。使用 Qwak,您不仅可以管理模型;还可以有效地简化从概念到部署的整个过程,使情境感知的 LLM 能够在短短几个小时内在您的环境中运行。
RA/SD 衍生者AI训练营。发布者:稻草人,转载请注明出处:https://www.shxcj.com/archives/4097