介绍
矢量数据库是一项技术,已成为不断变化的数据管理领域的重大变革者。凭借其无与伦比的速度和效率,这些尖端数据库正在彻底改变数据检索的规范。我们将在这次深入研究中探索矢量数据库的细微差别,理解其基本概念,并提供代码示例来展示其革命性的能力。
传统关系型数据库难以满足大数据时代对高性能数据检索日益增长的期望。向量数据库利用向量(在多维空间中表达数据的数学实体)的功能来解决这些问题。结果是什么?无与伦比的闪电般快速的数据检索速度。

了解矢量数据库
在动态的数据管理世界中,出现了一项突破性的技术,它重新定义了我们处理和检索信息的方式——矢量数据库。本综合指南旨在解开围绕矢量数据库的复杂性,提供对其架构、主要功能和实际应用的详细理解。
什么是矢量数据库?
在不断发展的数据管理领域,传统数据库系统经常面临对更快、更高效的数据检索日益增长的需求的挑战。矢量数据库是一种革命性的方法,它利用数学矢量来改变我们存储、索引和查询数据的方式。这项全面的探索旨在揭开矢量数据库概念的神秘面纱,并阐明其在数据管理领域的意义。
了解基础知识
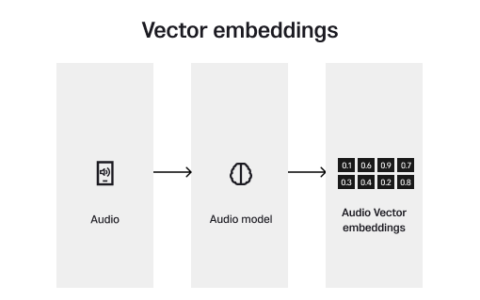
什么是向量?
表示多维空间中点的有序整数集合在数学中称为向量。这些向量表示数据库上下文中数据的质量或属性。与标准数据库相比,向量数据库使用向量以比具有行和列的表更动态和适应性更强的方式表示数据点。
矢量数据库定义
向量数据库是一种数据库管理系统,它使用向量数学的思想来存储、索引和查询数据。向量数据库根据多维空间中向量的接近度来组织和检索数据,而不是使用 B 树等传统索引结构。由于采用了这种新颖的方法,向量数据库可以更快、更有效地检索数据,这使得它们特别适用于需要响应实时响应请求的应用程序。
矢量数据库的关键组件
1. 向量作为数据实体
在矢量数据库中,使用矢量作为数据实体重塑了我们表示数据和与数据交互的方式。让我们通过探索代码示例来深入探讨这种范式转变的实际方面,这些示例强调了矢量作为矢量数据库中的动态数据实体的重要性。
示例 1:将数值数据表示为向量
考虑这样一种情况,我们想要在矢量数据库中表示数值数据点。每个数据点有三个特征:温度、湿度和压力。我们可以使用 3D 矢量来表示每个数据点。
# 将数值数据表示为向量的示例
numeric_data_point_1 = [25.5, 60.2, 101.3] # 温度、湿度、压力
numeric_data_point_2 = [22.0, 55.8, 100.5]
# 这些向量可以存储在向量数据库中
vector_db.insert_vector( "data_point_1" , numeric_data_point_1)
vector_db.insert_vector( "data_point_2" , numeric_data_point_2)
# 根据相似性查询
query_vector = [23.5, 58.0, 100.8]
result = vector_db.query_by_vector(query_vector)
print( "相似的数据点:" , result)
在这个例子中,每个数值数据点都由一个向量表示,并且向量数据库允许基于向量的相似性进行有效查询。
示例 2:将文本数据表示为向量
现在,让我们探索如何使用向量来表示文本数据。我们将使用一种简单的文本向量化技术,例如 TF-IDF(词频-逆文档频率)。
from sklearn.feature_extraction.text import TfidfVectorizer
# 将文本数据表示为向量的示例
text_data = [ "向量数据库提供高效的数据检索。" ,
"数据库中向量的使用具有革命性。" ,
"传统数据库使用表格结构来组织数据。" ]
# 将文本数据向量化
vectorizer = TfidfVectorizer()
text_vectors = vectorizer.fit_transform(text_data).toarray()
# 将文本向量存储在向量数据库中
for i, vector in enumerate(text_vectors):
vector_db.insert_vector(f "text_entry_{i+1}" , vector)
# 根据相似性进行查询
query_text = "向量数据库彻底改变了数据存储方式。"
query_vector = vectorizer.transform([query_text]).toarray()[0]
result = vector_db.query_by_vector(query_vector)
print( "类似的文本条目:" , result)
这里,文本数据使用 TF-IDF 表示为向量,并且向量数据库允许基于这些文本向量的相似性进行查询。
示例 3:将图像数据表示为矢量
对于图像等多媒体数据,向量可以表示像素值。让我们考虑一个简化的示例,其中通过展平其像素值将每幅图像表示为 1D 向量。
import numpy as np
from PIL import Image
# 将图像数据表示为矢量的示例
def image_to_vector ( image_path ):
img = Image. open (image_path)
img_array = np.array(img)
flattened_vector = img_array.flatten()
return flattened_vector
# 图像向量
image_vector_1 = image_to_vector( "image1.jpg" )
image_vector_2 = image_to_vector( "image2.jpg" )
# 将图像向量存储在向量数据库中
vector_db.insert_vector( "image_entry_1" , image_vector_1)
vector_db.insert_vector( "image_entry_2" , image_vector_2)
# 根据相似度查询
query_image_vector = image_to_vector( "query_image.jpg" )
result = vector_db.query_by_vector(query_image_vector)
print ( "相似图像:" , result)
在这个例子中,每个图像都由一个扁平的像素值向量表示,并且向量数据库允许基于这些图像向量的相似性进行有效查询。
这些代码示例说明了向量作为向量数据库中数据实体的多功能性。无论是表示数字、文本还是多媒体数据,向量都提供了一种统一而有效的方式来捕捉不同数据集的本质。通过利用向量的强大功能,向量数据库重新定义了数据表示和检索的格局,为现代数据管理挑战提供了灵活而动态的解决方案。
2. 向量索引
向量索引是向量数据库的一个重要方面,它使向量数据库有别于传统数据库。在本指南中,我们将探讨向量索引的概念,并深入研究代码示例,以说明它如何提高向量数据库中数据检索的效率。
理解向量索引
在向量数据库中,索引过程涉及基于向量本身创建索引。传统数据库通常使用 B 树之类的结构进行索引,但向量数据库利用向量固有的几何特性来创建高效的索引。这使数据库能够在查询期间快速定位和检索类似的向量。
代码示例
让我们使用假设的矢量数据库库通过实际代码示例探索矢量索引。
class VectorDatabase :
def __init__ ( self ):
self.vectors = {}
self.index = {}
def insert_vector ( self, key, vector ):
"""
在数据库中插入一个向量,并更新索引。
"""
self.vectors[key] = vector
self.update_index(key, vector)
def update_index ( self, key, vector ):
"""
使用新向量更新索引。
"""
for dim, value in enumerate (vector):
if dim not in self.index:
self.index[dim] = {}
if value not in self.index[dim]:
self.index[dim][value] = set ()
self.index[dim][value].add(key)
def query_by_vector ( self, query_vector ):
"""
根据向量查询数据库,并返回相似的向量。
"""
similar_keys = set ()
for dim, value in enumerate (query_vector):
if dim in self.index and value in self.index[dim]:
similar_keys.update(self.index[dim][value])
return [self.vectors[key] for key in similar_keys]
# 使用示例
vector_db = VectorDatabase()
# 将向量插入向量数据库
vector_db.insert_vector( "entry_1" , [ 2.5 , 1.8 , 3.2 , 4.7 ])
vector_db.insert_vector( "entry_2" , [ 3.0 , 1.5 , 3.2 , 4.5 ])
vector_db.insert_vector( "entry_3" , [ 2.2 , 1.7 , 3.0 , 4.6 ])
# 基于向量查询
query_vector = [ 2.4 , 1.9 , 3.1 , 4.8 ]
result = vector_db.query_by_vector(query_vector)
print ( "查询结果:", 结果)
在此示例中,该类VectorDatabase包括插入向量、更新索引和基于向量查询数据库的方法。索引针对向量的每个维度进行维护,从而可以高效地检索相似的向量。
向量索引的好处
- 高效检索:向量索引使得数据库能够快速识别和检索多维空间中相似或接近的向量。
- 可扩展性:随着数据库的增长,索引机制仍然保持高效,确保检索速度不会随着数据量的增加而降低。
- 灵活性:向量索引可以灵活地处理不同类型的数据,因为向量可以表示各种属性和特征。
向量索引是使向量数据库在数据检索效率方面表现优异的关键组件。通过利用向量的几何属性并根据其值维护索引,向量数据库为现代数据管理挑战提供了动态且可扩展的解决方案。在数据库系统中整合向量索引可以显著提高速度和性能,尤其是在需要实时数据检索和分析的应用程序中。
3. 用于查询的向量操作
向量运算在实现向量数据库中的复杂查询和高效数据检索方面起着至关重要的作用。在本指南中,我们将探讨关键的向量运算并提供代码示例来说明它们在查询向量数据库中的应用。
理解向量运算
向量运算涉及对向量进行数学运算,以计算距离、相似度和其他指标。这些运算是查询向量数据库的基础,因为它们允许识别多维空间中与给定查询向量接近或相似的向量。
代码示例
让我们深入研究在假设的矢量数据库库环境中演示矢量操作的代码示例。
from scipy.spatial import distance
class VectorDatabase :
def __init__ ( self ):
self.vectors = {}
def insert_vector ( self, key, vector ):
"""
在数据库中插入一个向量。
"""
self.vectors[key] = vector
def query_by_vector_cosine_similarity ( self, query_vector ):
"""
根据余弦相似度查询数据库,返回相似的向量。
"""
similar_vectors = []
for key, vector in self.vectors.items():
similarity = 1 - distance.cosine(query_vector, vector)
# 根据应用需要调整阈值
if similarity > 0.9 :
similarity_vectors.append((key, vector, similarity))
return similar_vectors
# 使用示例
vector_db = VectorDatabase()
# 在向量数据库中插入向量
vector_db.insert_vector( "entry_1" , [ 2.5 , 1.8 , 3.2 , 4.7 ])
vector_db.insert_vector( "entry_2" , [ 3.0 , 1.5 , 3.2 , 4.5 ])
vector_db.insert_vector( "entry_3" , [ 2.2 , 1.7 , 3.0 , 4.6 ])
# 根据余弦相似度查询
query_vector = [ 2.4 , 1.9 , 3.1 , 4.8 ]
result = vector_db.query_by_vector_cosine_similarity(query_vector)
print ( "根据余弦相似度查询结果:" , result)
在此示例中,该类VectorDatabase包含一个基于余弦相似度查询数据库的方法query_by_vector_cosine_similarity。调整阈值以确定哪些向量被认为与查询向量相似。
关键向量操作
1.余弦相似度
余弦相似度测量两个向量之间角度的余弦。值越接近 1,表示相似度越高。scipy.spatial.distance.cosine示例中的函数用于计算余弦相似度。
2.欧几里得距离
欧几里得距离度量空间中两点之间的直线距离。它是使用两个向量对应元素之间的平方差之和的平方根来计算的。
3.曼哈顿距离
曼哈顿距离,又称L1距离或城市街区距离,是两个向量对应元素的绝对差之和。
4. 闵可夫斯基距离
明可夫斯基距离是欧几里得距离和曼哈顿距离的泛化。它允许调整幂参数,2 的幂产生欧几里得距离,1 的幂产生曼哈顿距离。
向量运算为查询向量数据库提供了数学基础。通过应用余弦相似度、欧几里得距离等运算,向量数据库可以有效地识别和检索多维空间中的相似向量。具体操作的选择取决于数据的性质和应用程序的要求。将这些向量运算集成到向量数据库系统中,使其能够精确、快速地处理各种数据分析和检索任务。
4.向量存储机制
向量数据库中的存储机制对于保证多维数据的高效组织和检索起着至关重要的作用。在本文中,我们将探讨向量存储机制背后的原理,并提供代码示例来说明其在假设的向量数据库中的实现。
理解向量存储机制
向量存储机制涉及以允许快速和可扩展检索的方式存储向量的策略。高效的存储至关重要,尤其是在向量数据库中,其中数据点以多维空间中的向量表示。选择正确的存储机制可确保在查询期间快速访问向量,从而有助于提高向量数据库的整体性能。
代码示例
让我们深入研究代码示例,以演示假设的矢量数据库中的矢量存储机制。
class VectorDatabase :
def __init__ ( self ):
self.vectors = {}
def insert_vector ( self, key, vector ):
"""
将向量插入数据库。
"""
self.vectors[key] = vector
def withdraw_vector ( self, key ):
"""
根据键从数据库中检索向量。
"""
return self.vectors.get(key, None )
# 示例用法
vector_db = VectorDatabase()
# 将向量插入向量数据库
vector_db.insert_vector( "entry_1" , [ 2.5 , 1.8 , 3.2 , 4.7 ])
vector_db.insert_vector( "entry_2" , [ 3.0 , 1.5 , 3.2 , 4.5 ])
vector_db.insert_vector( "entry_3" , [ 2.2 , 1.7 , 3.0 , 4.6 ])
# 根据键检索向量
vector_key_to_retrieve = "entry_2"
retrieved_vector = vector_db.retrieve_vector(vector_key_to_retrieve)
print ( f"Vector for key {vector_key_to_retrieve} : {retrieved_vector} " )
在这个例子中,该类VectorDatabase包括将向量插入数据库和根据其键检索向量的方法。
向量存储机制的关键方面
1.基于密钥的存储
向量以唯一的密钥标识符存储在数据库中。这种基于密钥的存储方式允许根据密钥高效地检索特定向量。
2.高效的数据结构
选择高效的数据结构来存储向量对于快速访问至关重要。在示例中,使用了一个简单的字典,但可以使用更复杂的数据结构(如哈希表或空间数据结构(例如 kd 树))来优化性能。
3.序列化
为了持久存储或数据传输,向量可能需要序列化为合适的格式。常见的序列化格式包括 JSON、Pickle 或二进制序列化。序列化可确保向量能够可靠地存储、检索和传输。
4. 压缩(可选)
在存储效率至关重要的场景下,可以采用压缩技术来减少向量所需的存储空间。然而,这可能会在压缩和解压缩过程中带来处理开销方面的权衡。
高效的向量存储是向量数据库的基石,影响数据检索的速度和可扩展性。通过采用基于键的存储、利用高效的数据结构以及在适用的情况下考虑序列化和压缩,向量数据库可以优化多维数据的处理。实施强大的向量存储机制可确保向量数据库能够有效地管理和检索向量,使其非常适合要求实时响应和可扩展性的应用程序。
5.矢量数据库API
精心设计的矢量数据库 API 可简化矢量数据库与各种应用程序的集成。在本指南中,我们将探讨矢量数据库 API 的基本组件,并提供代码示例来说明其在假设场景中的用法。
设计矢量数据库 API
向量数据库 API 通常包括插入向量、基于向量查询数据库以及执行其他向量相关操作的方法。API 充当应用程序与底层向量数据库之间的接口,提供与多维数据无缝交互的方式。
代码示例
让我们深入研究代码示例来演示矢量数据库 API 的关键组件。
class VectorDatabase :
def __init__ ( self ):
self.vectors = {}
def insert_vector ( self, key, vector ):
"""
在数据库中插入一个向量。
"""
self.vectors[key] = vector
def withdraw_vector ( self, key ):
"""
根据键从数据库中检索一个向量。
"""
return self.vectors.get(key, None )
def query_by_vector ( self, query_vector, Threshold= 0.9 ):
"""
根据向量相似度查询数据库,并返回相似的向量。
"""
similar_vectors = []
for key, vector in self.vectors.items():
similarity = self.calculate_similarity(query_vector, vector)
if similarity > Threshold:
similarity_vectors.append((key, vector, similarity))
return similar_vectors
def calculate_similarity ( self, vector1, vector2 ):
"""
计算两个向量之间的相似度(余弦相似度在这个例子中)。
“”
#这可以用其他相似性度量替换
返回 1.0 - distance.cosine(vector1, vector2)
在此示例中,该类VectorDatabase包括插入向量、检索向量、根据向量相似度查询数据库以及计算两个向量之间的相似度的方法。
示例用法
# 向量数据库 API 的示例使用
# 创建向量数据库实例
vector_db = VectorDatabase()
# 将向量插入数据库
vector_db.insert_vector( "entry_1" , [2.5, 1.8, 3.2, 4.7])
vector_db.insert_vector( "entry_2" , [3.0, 1.5, 3.2, 4.5])
vector_db.insert_vector( "entry_3" , [2.2, 1.7, 3.0, 4.6])
# 根据向量查询数据库
query_vector = [2.4, 1.9, 3.1, 4.8]
result = vector_db.query_by_vector(query_vector)
print( "根据向量相似度查询结果:" , result)
此示例演示了向量数据库 API 如何允许用户通过插入向量、检索向量以及基于向量相似性查询数据库来与数据库交互。
矢量数据库 API 的关键组件
1. 插入方法(insert_vector)
将向量插入数据库的方法。它通常需要一个密钥标识符和要插入的向量。
2. 检索方法(retrieve_vector)
根据关键标识符从数据库中检索向量的方法。
3.查询方式(query_by_vector)
基于查询向量查询数据库的方法。它返回相似的向量以及相似度度量。
4.向量相似度计算方法(calculate_similarity)
计算两个向量之间相似度的实用方法。具体相似度指标可能因应用需求而异。
定义良好的向量数据库 API 简化了向量数据库与应用程序的集成,使开发人员能够无缝地与多维数据交互。通过提供向量插入、检索和查询的方法,API 抽象了向量数据库操作的复杂性,使开发人员更容易在各种应用场景中利用多维数据的强大功能。
6. 可扩展性机制
可扩展性是矢量数据库的一个重要方面,尤其是在大数据时代。在本指南中,我们将探讨可扩展性机制并提供代码示例来说明有效处理不断增长的多维数据的策略。
分布式计算
分布式计算是实现可扩展性的常用方法,允许 Vector Databases 将工作负载分布在多个节点或服务器上。以下是使用 Python 多处理模块的基本示例:
导入多处理
类 DistributedVectorDatabase:
def __init__(self,num_nodes):
self.nodes = [{} for _ in range(num_nodes)]
def hash_key_to_node(self,key):
# 基于哈希的键到节点的简单映射
return hash(key)%len(self.nodes)
def insert_vector(self,key,vector):
node_index = self.hash_key_to_node(key)
self.nodes [node_index] [key] = vector
def withdraw_vector(self,key):
node_index = self.hash_key_to_node(key)
return self.nodes [node_index] 。获取(key,None)
# 示例用法distributed_db = DistributedVectorDatabase
(num_nodes = 4)
# 将向量插入分布式数据库distributed_db.insert_vector
(“entry_1 ”,[ 2.5,1.8,3.2,4.7 ]) distribution_db.insert_vector( "entry_2" , [ 3.0 , 1.5 , 3.2 , 4.5 ]) distribution_db.insert_vector( "entry_3" , [ 2.2 , 1.7 , 3.0 , 4.6 ]) # 根据键检索向量vector_key_to_retrieve = "entry_2" removed_vector = distribution_db.retrieve_vector(vector_key_to_retrieve) print ( f"Vector for key {vector_key_to_retrieve} : {retrieved_vector} " )
在此示例中,向量使用基于哈希的简单机制分布在各个节点上。该hash_key_to_node方法根据向量的密钥确定应将向量存储在哪个节点上。
并行处理
并行处理是另一种可扩展机制,可用于增强矢量运算的性能。下面是一个使用 Python 多处理模块的简单示例:
导入多处理
类 ParallelVectorDatabase:
def __init__(self):
self.vectors = {}
def insert_vector(self,key,vector):
self.vectors [key] = vector
def parallel_query(self,query_vector):
#将向量拆分为块以进行并行处理
chunks = [ list(chunk.values())for chunk in multiprocessing.Array('d',self.vectors.values(),lock = False)]
with multiprocessing.Pool()as pool:
results = pool。map (self.calculate_similarity_parallel, chunks)
# 合并并行处理的结果
combined_results = [item for sublist in results for item in sublist]
return combined_results
@staticmethod
def calculate_similarity_parallel ( vectors_chunk ):
# 模拟并行化操作(例如相似度计算)
return [(vector, vector) for vector in vectors_chunk]
# 使用示例
parallel_db = ParallelVectorDatabase()
# 将向量插入并行数据库
parallel_db.insert_vector( "entry_1" , [ 2.5 , 1.8 , 3.2 , 4.7 ])
parallel_db.insert_vector( "entry_2" , [ 3.0 , 1.5 , 3.2 , 4.5 ])
parallel_db.insert_vector( "entry_3" , [ 2.2 , 1.7 , 3.0 , 4.6 ])
# 基于向量并行查询数据库
query_vector_parallel = [ 2.4 , 1.9 , 3.1 , 4.8 ]
result_parallel = parallel_db.parallel_query(query_vector_parallel)
print ( "基于并行处理的查询结果:" , result_parallel)
在此示例中,该类ParallelVectorDatabase使用并行处理来分块执行矢量运算,从而在矢量运算可以并行化的场景中提供潜在的加速。
分片
分片是一种将数据集划分为更小、更易于管理的单元(称为分片)的技术。每个分片都可以独立存储和处理,从而提高可扩展性。下面是一个基本示例:
class ShardedVectorDatabase :
def __init__ ( self, num_shards ):
self.shards = [{} for _ in range (num_shards)]
def shard_key_to_index ( self, key ):
# 基于哈希的键到分片的简单映射
return hash (key) % len (self.shards)
def insert_vector ( self, key, vector ):
shard_index = self.shard_key_to_index(key)
self.shards[shard_index][key] = vector
def withdraw_vector ( self, key ):
shard_index = self.shard_key_to_index(key)
return self.shards[shard_index].get(key, None )
# 示例用法
sharded_db = ShardedVectorDatabase(num_shards= 8 )
# 将向量插入分片数据库
sharded_db.insert_vector( "entry_1" , [ 2.5 , 1.8 , 3.2 , 4.7 ])
sharded_db.insert_vector( "entry_2" , [ 3.0 , 1.5 , 3.2 , 4.5 ])
sharded_db.insert_vector( "entry_3" , [ 2.2 , 1.7 , 3.0 , 4.6 ])
# 根据键检索向量
vector_key_to_retrieve = "entry_2"
removed_vector = sharded_db.retrieve_vector(vector_key_to_retrieve)
print ( f"Vector for key {vector_key_to_retrieve} : {retrieved_vector} " )
在此示例中,向量使用基于哈希的机制分布在各个分片中。该shard_key_to_index方法根据向量的键确定应将其存储在哪个分片上。
可扩展性机制对于确保矢量数据库能够有效处理不断增长的多维数据量至关重要。无论是通过分布式计算、并行处理、分片还是这些策略的组合,设计良好的矢量数据库都可以为具有大型数据集的实际应用程序提供快速且可扩展的解决方案。在矢量数据库系统中选择和实施可扩展性机制时,请考虑数据的特定要求和特性。
7. 向量查询语言
矢量查询语言 (VQL) 允许用户表达复杂的查询,以从矢量数据库中检索多维数据。在本指南中,我们将定义一个简单的 VQL 并提供代码示例,以展示其在假设的矢量数据库中的用法。
定义矢量查询语言(VQL)
VQL 旨在提供简洁且富有表现力的语法来查询矢量数据库。它包括用于指定基于矢量的条件、相似性度量和其他与多维数据相关的操作的构造。
代码示例
让我们使用矢量数据库的代码示例创建 VQL 的基本实现。
class VectorQueryLanguage :
def __init__ ( self, vector_db ):
self.vector_db = vector_db
def execute_query ( self, query ):
"""
在向量数据库上执行 VQL 查询。
"""
if query.startswith( "SIMILAR TO " ):
# 解析查询并执行基于相似性的搜索
query_vector = [ float (value) for value in query[ 11 :].split( ',' )]
return self.vector_db.query_by_vector(query_vector)
else :
raise ValueError( "Invalid VQL query" )
# 使用示例
vector_db = VectorDatabase()
# 将向量插入向量数据库
vector_db.insert_vector( "entry_1" , [ 2.5 , 1.8 , 3.2 , 4.7 ])
vector_db.insert_vector( "entry_2" , [ 3.0 , 1.5 , 3.2 , 4.5 ])
vector_db.insert_vector( "entry_3" , [ 2.2 , 1.7 , 3.0 , 4.6 ])
# 创建 VectorQueryLanguage 的实例
vql = VectorQueryLanguage(vector_db)
# 执行 VQL 查询
query_result = vql.execute_query( "SIMILAR TO 2.4,1.9,3.1,4.8" )
print ( "查询结果:" , query_result)
在此示例中,该类VectorQueryLanguage包含一个解释和执行 VQL 查询的方法execute_query。实现的查询是SIMILAR TO,允许用户查找与指定查询向量相似的向量。
VQL 查询示例:
- 查找类似于
[2.4, 1.9, 3.1, 4.8]query_result = vql.execute_query("SIMILAR TO 2.4,1.9,3.1,4.8") - (潜在扩展)查找第二维大于 2.0 的向量
python # Hypothetical extension of VQL query_result = vql.execute_query("WHERE Dimension[1] > 2.0")
扩展 VQL(假设)
虽然上面的示例是一个基本实现,但 VQL 可以扩展以支持更高级的功能和条件。以下是基于特定维度进行过滤的假设扩展:
class VectorQueryLanguage :
# ... (以前的实现)
def execute_query ( self, query ):
if query.startswith( "SIMILAR TO " ):
# ... (未更改)
elif query.startswith( "WHERE " ):
# 解析 WHERE 子句并执行过滤搜索
condition = query[ 6 :]
return self.vector_db.query_by_condition(condition)
else :
raise ValueError( "Invalid VQL query" )
# 假设的扩展用法
# 示例用法
vql = VectorQueryLanguage(vector_db)
# 执行带有 WHERE 子句的 VQL 查询
query_result = vql.execute_query( "WHERE Dimension[1] > 2.0" )
print ( "带有 WHERE 子句的查询结果:" , query_result)
此假设扩展WHERE在 VQL 中引入了一个子句,用于根据特定条件过滤向量。请记住,此类扩展取决于向量数据库的特定功能和要求。
矢量查询语言 (VQL) 提供了一种表达矢量数据库中多维数据的复杂查询的方法。VQL 的简单性和表现力使其成为用户与矢量数据库交互和从矢量数据库检索数据的强大工具。在设计和实施自己的 VQL 时,请考虑矢量数据库的特定需求和特性,以确保无缝且直观的查询体验。
矢量数据库的优势
矢量数据库具有诸多优势,为处理多维数据提供了高效灵活的解决方案。在本指南中,我们将探讨一些主要优势,并提供代码示例来说明它们对实际场景的影响。
1. 高效的相似性搜索
代码示例:
# 在向量数据库中进行有效的相似性搜索
query_vector = [2.4, 1.9, 3.1, 4.8]
result = vector_db.query_by_vector(query_vector)
print( "相似向量:" , result)
在这个例子中,向量数据库可以高效地检索与指定查询向量相似的向量。底层的索引和向量操作可以实现快速而准确的相似性搜索。
2. 多种数据类型的统一表示
代码示例:
# 将多种数据类型表示为向量
text_data = [ "向量数据库提供高效的数据检索。" ,
"数据库中向量的使用具有革命性。" ,
"传统数据库使用表格结构来组织数据。" ]
# 将文本数据向量化
vectorizer = TfidfVectorizer()
text_vectors = vectorizer.fit_transform(text_data).toarray()
for i, vector in enumerate(text_vectors):
vector_db.insert_vector(f "text_entry_{i+1}" , vector)
在此示例中,文本数据使用 TF-IDF 矢量化表示为矢量。矢量数据库无缝适应各种数据类型,从而实现统一表示。
3.分布式计算的可扩展性
代码示例:
# 向量数据库中分布式计算的可扩展性
tributed_db = DistributedVectorDatabase(num_nodes=4)
# 将向量插入分布式数据库
distributed_db.insert_vector( "entry_1" , [2.5, 1.8, 3.2, 4.7])
tributed_db.insert_vector( "entry_2" , [3.0, 1.5, 3.2, 4.5])
tributed_db.insert_vector( "entry_3" , [2.2, 1.7, 3.0, 4.6])
# 根据键检索向量
vector_key_to_retrieve = "entry_2"
retried_vector = distribution_db.retrieve_vector(vector_key_to_retrieve)
print(f "Vector for key {vector_key_to_retrieve}: {retrieved_vector}" )
在此示例中,矢量数据库被设计为将矢量分布在多个节点上,从而随着数据集的增长增强可扩展性。
4. 并行处理,加快操作速度
代码示例:
# 并行处理以实现更快的向量操作
parallel_db = ParallelVectorDatabase()
# 将向量插入并行数据库
parallel_db.insert_vector( "entry_1" , [2.5, 1.8, 3.2, 4.7])
parallel_db.insert_vector( "entry_2" , [3.0, 1.5, 3.2, 4.5])
parallel_db.insert_vector( "entry_3" , [2.2, 1.7, 3.0, 4.6])
# 基于向量并行查询数据库
query_vector_parallel = [2.4, 1.9, 3.1, 4.8]
result_parallel = parallel_db.parallel_query(query_vector_parallel)
print( "基于并行处理的查询结果:" , result_parallel)
此示例演示了向量数据库中的并行处理,其中向量操作并行执行,从而可能提高速度。
5. 自适应数据表示的动态模式
代码示例:
# 向量数据库中的动态模式
dynamic_db = DynamicSchemaVectorDatabase()
# 插入具有不同维度的向量
dynamic_db.insert_vector( "entry_1" , [2.5, 1.8, 3.2])
dynamic_db.insert_vector( "entry_2" , [3.0, 1.5, 3.2, 4.5, 2.1])
在此示例中,具有动态模式的矢量数据库允许插入具有不同维度的矢量,从而提供数据表示的灵活性。
矢量数据库具有众多优势,从高效的相似性搜索和统一的数据表示到分布式计算和并行处理的可扩展性。提供的示例展示了这些优势的实际实现,证明了矢量数据库在处理复杂多维数据方面的多功能性和强大功能。在探索这些功能时,请考虑它们如何满足您的应用程序和数据管理挑战的特定要求。
Paragoger衍生者AI训练营。发布者:稻草人,转载请注明出处:https://www.shxcj.com/archives/4005