
Transformer 于 2017 年问世。已经有很多文章解释了它的工作原理,但我经常发现它们要么过于深入数学,要么过于浅显。
我花在谷歌搜索(或 chatGPT)上的时间和阅读的时间一样多,这不是理解一个主题的最佳方法。这让我写了这篇文章,我试图解释 Transformer 最具革命性的方面,同时保持简洁明了,任何人都可以阅读。
本文假设您对机器学习原理有一般性的了解。


Transformer 背后的理念引领我们进入生成式人工智能时代
Transformers 代表了序列传导模型的一种新架构。序列模型是一种将输入序列转换为输出序列的模型。该输入序列可以是各种数据类型,例如字符、单词、标记、字节、数字、音素(语音识别),也可以是多模态¹。
在 Transformer 出现之前,序列模型主要基于循环神经网络 (RNN)、长短期记忆 (LSTM)、门控循环单元 (GRU) 和卷积神经网络 (CNN)。它们通常包含某种形式的注意力机制,用于解释序列中各个位置的项目所提供的上下文。
先前模型的缺点
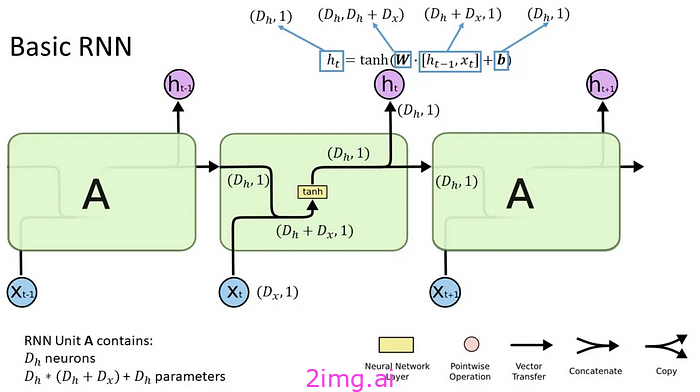
- RNN :该模型按顺序处理数据,因此从上一次计算中学习到的任何内容都会在下一次计算中得到考虑²。然而,其顺序性会导致一些问题:该模型难以解释较长序列的长期依赖性(称为消失或爆炸梯度),并且阻止输入序列的并行处理,因为您无法同时对输入的不同块进行训练(批处理),因为您会丢失先前块的上下文。这使得训练的计算成本更高。
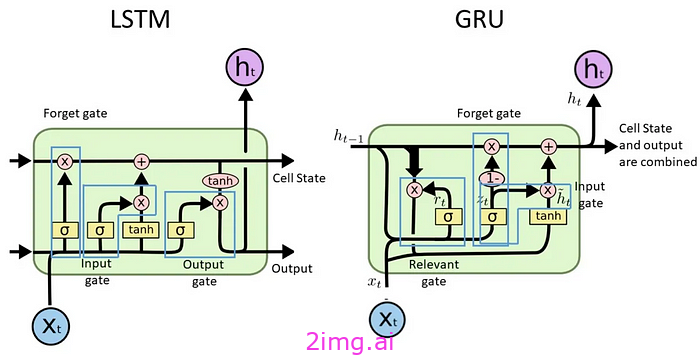
- LSTM 和 GRU:利用门控机制来保留长期依赖关系³。该模型具有一个单元状态,其中包含来自整个序列的相关信息。单元状态通过诸如遗忘门、输入门、输出门(LSTM)和更新门、重置门(GRU)之类的门进行更改。这些门决定在每个连续迭代中应保留多少来自先前状态的信息,应添加多少来自新更新的信息,然后应整体保留新单元状态的哪一部分。虽然这改善了消失梯度问题,但模型仍然按顺序工作,因此由于并行化有限,训练速度很慢,尤其是当序列变长时。
- CNN:以更并行的方式处理数据,但从技术上讲仍按顺序运行。它们在捕获局部模式方面很有效,但由于卷积的工作方式,它们难以处理长期依赖关系。捕获两个输入位置之间关系的操作数量会随着位置之间的距离而增加。
因此,我们引入了Transformer,它完全依赖于注意力机制,并消除了循环和卷积。注意力机制是模型在生成输出的每个步骤中关注输入序列的不同部分所使用的机制。Transformer 是第一个使用注意力机制而不进行顺序处理的模型,它允许并行化,从而加快训练速度,而不会丢失长期依赖关系。它还会在输入位置之间执行恒定数量的操作,无论它们相距多远。
了解 Transformer 模型架构
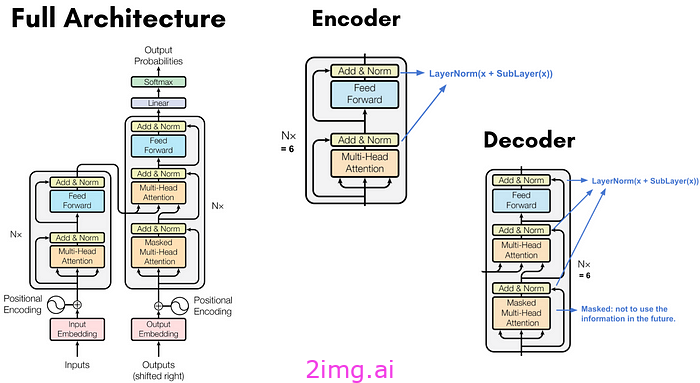
Transformer 架构
Transformer 的重要特征包括:标记化、嵌入层、注意力机制、编码器和解码器。
Token
输入的单词序列被转换成 3-4 个字符长的标记
嵌入
输入和输出序列被映射到一系列连续表示z,它表示输入和输出嵌入。每个标记将由一个嵌入来表示,以捕获某种含义,这有助于计算它与其他标记的关系;这个嵌入将表示为一个向量。为了创建这些嵌入,我们使用训练数据集的词汇表,其中包含用于训练模型的每个唯一输出标记。然后,我们确定一个合适的嵌入维度,它对应于每个标记的向量表示的大小;更高的嵌入维度将更好地捕捉更复杂/多样/错综复杂的含义和关系。对于词汇表大小 V 和嵌入维度 D,嵌入矩阵的维度因此变为 V x D,使其成为一个高维向量。
在初始化时,这些嵌入可以随机初始化,并在训练过程中学习更准确的嵌入。然后在训练期间更新嵌入矩阵。
由于转换器没有内置的标记顺序意识,因此这些嵌入中添加了位置编码。
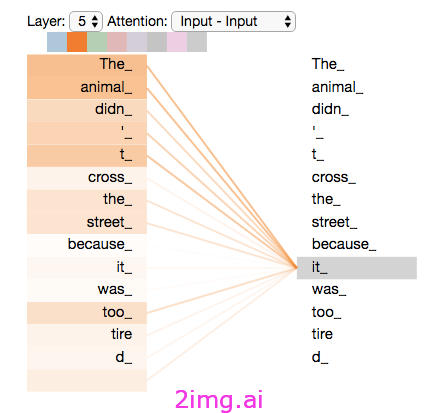
注意力机制
自注意力机制是指序列中的每个标记都会计算序列中其他每个标记的注意力得分,以了解所有标记之间的关系,而不管彼此之间的距离。在本文中,我将避免过多的数学知识,但您可以在此处阅读有关计算注意力得分的不同矩阵的信息,从而捕捉每个标记与其他每个标记之间的关系。
这些注意力分数会为每个标记产生一组新的表示⁴,然后用于下一层处理。在训练期间,权重矩阵通过反向传播进行更新,因此模型可以更好地解释标记之间的关系。
多头注意力机制只是自注意力机制的一种延伸。计算不同的注意力分数,将结果连接起来并进行转换,最终得到的表征增强了模型捕捉token 之间各种复杂关系的能力。
编码器
具有位置编码的输入嵌入(从输入序列构建)被输入到编码器中。输入嵌入有 6 层,每层包含 2 个子层:多头注意力和前馈网络。还有一个残差连接,导致每层的输出为 LayerNorm(x+Sublayer(x)),如图所示。编码器的输出是一系列向量,这些向量是考虑注意力得分后输入的上下文化表示。然后将它们输入到解码器。
解码器
具有位置编码的输出嵌入(从目标输出序列生成)被输入到解码器中。解码器也包含 6 层,与编码器有两点不同。
首先,输出嵌入经过掩码 多头注意力机制,这意味着在计算注意力分数时,序列中后续位置的嵌入会被忽略。这是因为当我们生成当前标记(在位置 i)时,我们应该忽略 i 之后位置的所有输出标记。此外,输出嵌入向右偏移一个位置,因此位置 i 处的预测标记仅依赖于小于它的位置的输出。
例如,假设输入为“ je suis étudiant à l’école ”,目标输出为“ i am a student in school ”。在预测student的标记时,编码器采用“ je suis etudiant ”的嵌入,而解码器隐藏“a”之后的标记,以便student的预测仅考虑句子中的前几个标记,即“I am a ”。这会训练模型按顺序预测标记。当然,“ in school ”这些标记为模型的预测提供了额外的上下文,但我们正在训练模型从输入标记“ etudiant ”和后续输入标记“ à l’école ”中捕获此上下文。
解码器如何获得这种上下文?这给我们带来了第二个区别:解码器中的第二个多头注意力层在将输入传递到前馈网络之前接收输入的上下文化表示,以确保输出表示能够捕获输入标记和先前输出的完整上下文。这为我们提供了与每个目标标记相对应的向量序列,它们是上下文化的 目标表示。
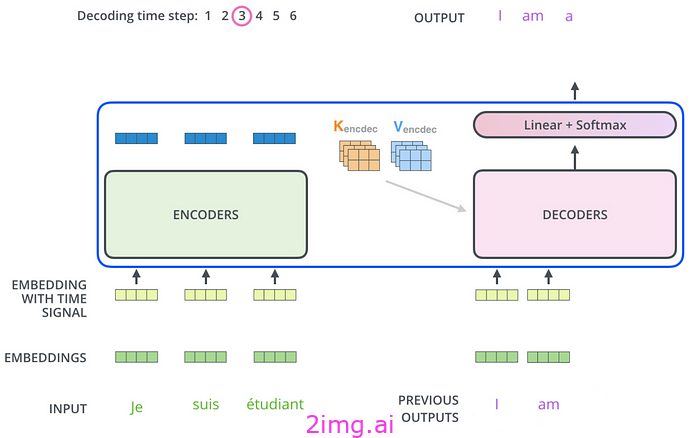
使用线性层和 Softmax 层进行预测
现在,我们要使用这些语境化的目标表示来确定下一个标记是什么。使用来自解码器的语境化的目标表示,线性层将向量序列投影到更大的logits 向量中,该向量的长度与我们模型的词汇表相同,假设长度为 L。线性层包含一个权重矩阵,当与解码器输出相乘并添加一个偏差向量时,将产生大小为 1 x L 的 logits 向量。每个单元格都是一个唯一标记的分数,然后 softmax 层对这个向量进行规范化,使整个向量之和为 1;每个单元格现在代表每个标记的概率。选择概率最高的标记,瞧!我们就得到了预测的标记。
训练模型
接下来,我们将预测的 token 概率与实际的 token 概率进行比较(除了目标 token 的概率为 1.0 之外,每个 token 的 logits 向量均为 0)。我们为每个 token 预测计算适当的损失函数,并在整个目标序列上平均该损失。然后,我们将该损失反向传播到模型的所有参数上以计算适当的梯度,并使用适当的优化算法来更新模型参数。因此,对于经典的 Transformer 架构,这会导致更新
- 嵌入矩阵
- 用于计算注意力分数的不同矩阵
- 与前馈神经网络相关的矩阵
- 用于制作 logits 向量的线性矩阵
2-4 中的矩阵是权重矩阵,并且每个输出都有相关的额外偏差项,这些偏差项也会在训练期间更新。
注意:线性矩阵和嵌入矩阵通常是彼此的转置。这就是《Attention is All You Need》论文的情况;该技术称为“权重绑定”。因此,需要训练的参数数量减少了。
这代表一个训练周期。训练包含多个周期,周期数取决于数据集的大小、模型的大小以及模型的任务。
回顾《Transformer》的精彩之处
正如我们前面提到的,RNN、CNN、LSTM 等的问题包括缺乏并行处理、顺序架构以及对长期依赖关系的捕获不足。上述 Transformer 架构解决了这些问题……
- 注意力机制允许并行处理 整个序列,而不是按顺序处理。借助自注意力机制,输入序列中的每个标记都会关注输入序列中的每个其他标记(该小批量的标记,下文将解释)。这会同时捕获所有关系,而不是按顺序捕获。
- 每个时期内对输入进行小批量处理可以实现并行处理、加快训练速度,并提高模型的可扩展性。在大量示例文本中,小批量表示这些示例的较小集合。数据集中的示例在放入小批量之前会进行混洗,并在每个时期开始时重新混洗。每个小批量都会同时传入模型。
- 通过使用位置编码和批处理,可以考虑序列中标记的顺序。无论标记之间的距离有多远,它们之间的距离也会被平等考虑,而小批量处理进一步确保了这一点。
正如论文所示,结果非常棒。
欢迎来到变形金刚的世界。
GPT 架构简介
Transformer 架构由研究员 Ashish Vaswani 于 2017 年在 Google Brain 工作时引入。生成式预训练 Transformer (GPT) 由 OpenAI 于 2018 年引入。主要区别在于 GPT 的架构中不包含编码器堆栈。当直接将一个序列转换为另一个序列时,编码器-解码器组合非常有用。GPT 的设计重点是生成能力,它取消了解码器,同时保持其余组件的相似性。
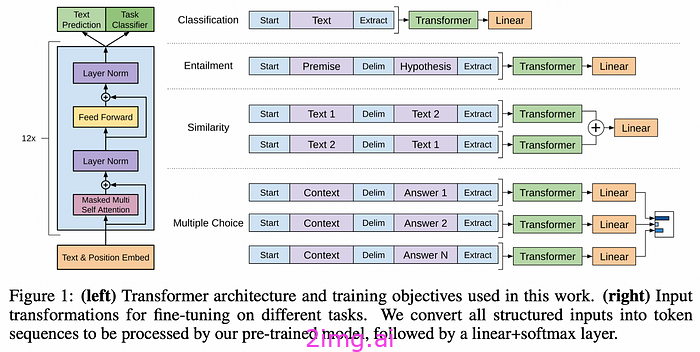
GPT 模型是在大量文本语料库上进行预训练的,无需监督,可以学习所有单词和标记之间的关系⁵。经过针对各种用例(例如通用聊天机器人)的微调后,它们已被证明在生成任务中非常有效。
例子
当你问它一个问题时,预测的步骤与常规转换器大致相同。如果你问它“GPT 如何预测响应”,这些单词会被标记化,生成嵌入,计算注意力分数,计算下一个单词的概率,并选择一个标记作为下一个预测标记。例如,模型可能会逐步生成响应,从“GPT 预测响应……”开始,并根据概率继续,直到形成完整、连贯的响应。(猜猜怎么着,最后一句话来自 chatGPT)。
Paragoger衍生者AI训练营。发布者:稻草人,转载请注明出处:https://www.shxcj.com/archives/3894