


在本文中,我们将研究如何针对疾病症状训练一个小型医疗保健语言模型。为此,我们将从HuggingFace获取数据集(用于训练我们的模型):https://huggingface.co/datasets/QuyenAnhDE/Diseases_Symptoms
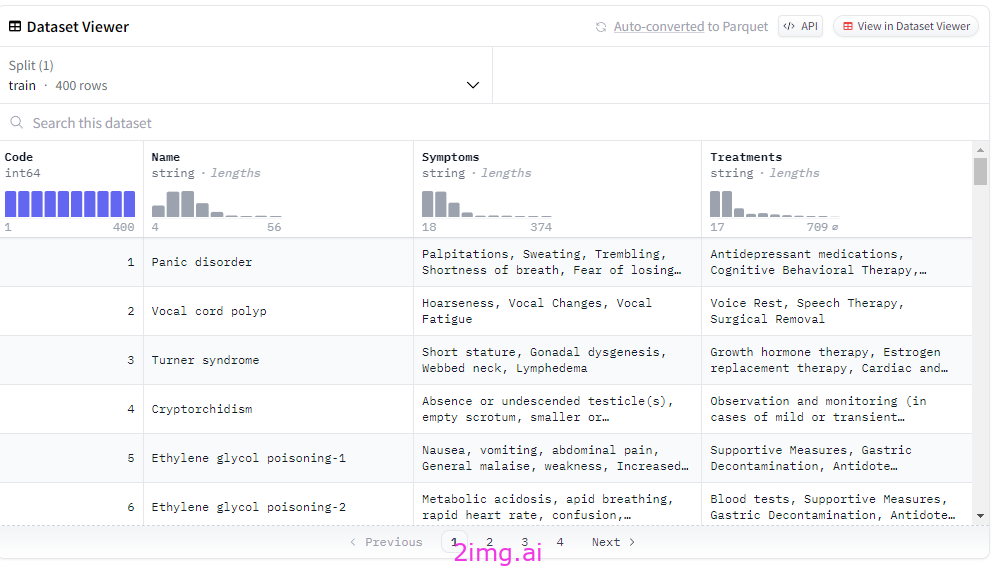
QuyenAnhDE/Diseases_Symptoms 数据集来自 Hugging Face。图片来源:Walid Soula
对于模型,我们将使用 GPT2:https://huggingface.co/distilbert/distilgpt2
DistilGPT2 是一个英语模型,在 1.24 亿个参数版本的 GPT-2 的监督下进行了预训练。DistilGPT2 拥有 8200 万个参数,是使用知识蒸馏开发的,旨在成为 GPT-2 的更快、更轻量级版本。
DistilGPT2 使用 OpenWebTextCorpus 进行训练,OpenWebTextCorpus 是 OpenAI 的 WebText 数据集的开源复制品,用于训练 GPT-2。
在开始之前,我们先来了解一下什么是小型语言模型?
小型语言模型是大型语言模型的缩小版,通常设计为具有更少的参数和更小的内存占用,同时仍保留生成连贯文本的能力。
这些较小的模型通常用于计算资源有限(尤其是在边缘设备)或实时性能至关重要的应用中。
我认为小语言模型 (SLM) 将在医疗保健领域发挥重要作用,指导患者,获得专家或特定医疗机构的问答,同时增强医疗保健边缘设备的功能,如血糖仪、张力计等,特别是在智能手表上可访问的移动应用程序的开发,也促进治疗监测和最佳患者护理!
开始吧
依赖项和库
第一步包括安装运行 SML 微调所需的依赖项
!pip install torch torchtext transformers sentencepiece pandas tqdm datasets
from datasets import load_dataset, DatasetDict, Dataset
import pandas as pd
import ast
import datasets
from tqdm import tqdm
import time
首先,我从datasets模块引入了load_dataset、DatasetDict和Dataset等函数和类,以便加载和使用数据集。此外,我还加入了pandas,这对于数据操作来说是必不可少的。
最后,ast模块帮助解析 Python 代码。为了跟踪冗长操作的进度,我导入了tqdm和time模块来处理与时间相关的操作。
导入数据集
我们通过复制 hugging face 中的名字来加载数据
#加载数据集
df = load_dataset( "QuyenAnhDE/Diseases_Symptoms" )
加载数据集。

数据集。
您可以看到,数据集已加载,包含 400 行(非常小,即使质量很高,特别是如果我们拆分数据进行训练和测试)和 4 列(代码、名称、症状和治疗方法)。
注意:如果数据质量好,应该有 2000 行
将数据集转换为 Dataframe
我将通过从原始数据集的“训练”列中选择特定列(“名称”、“症状”、“治疗”)来创建一个 DataFrame“df”。
df = [{'Name': item['Name'], 'Symptoms': item['Symptoms']} for item in df['train']]
df = pd.DataFrame(df)
df
 df 数据框。图片来源:Walid Soula
df 数据框。图片来源:Walid Soula
注意:有一个小的数据预处理步骤,以确保 Symptoms 中的每个症状都用逗号分隔。该功能:
- 它用逗号分隔文本,因此它将每个症状分开。例如,“发烧、咳嗽、头痛”变成列表 [“发烧”、“咳嗽”、“头痛”]。
- 然后,它用逗号和空格将这些分开的症状重新连接在一起。因此,[“发烧”,“咳嗽”,“头痛”] 变成“发烧,咳嗽,头痛”。
df['Symptoms'] = df['Symptoms'].apply(lambda x: ', '.join(x.split(', ')))
加载标记器
我们将在这里使用 Transformers 库从 Hugging Face 模型中心加载预训练的标记器。
我们还将导入 PyTorch 的核心功能,包括张量、神经网络模块和用于训练目的的优化算法。
from transformers import GPT2Tokenizer, GPT2LMHeadModel
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import Dataset, DataLoader, random_split
设备配置
如果你有 GPU,它会优先使用 GPU,而不是 CPU;如果你有 Apple Silicon,则将其设置为 mps
# If you have an NVIDIA GPU attached, use 'cuda'
if torch.cuda.is_available():
device = torch.device('cuda')
else:
# If Apple Silicon, set to 'mps' - otherwise 'cpu' (not advised)
try:
device = torch.device('mps')
except Exception:
device = torch.device('cpu')
最后加载模型和标记器
# The tokenizer turns texts to numbers (and vice-versa)
tokenizer = GPT2Tokenizer.from_pretrained('distilgpt2')
# The transformer
model = GPT2LMHeadModel.from_pretrained('distilgpt2').to(device)
注意:我将把 BATCH_SIZE 设置为 8 以供进一步使用(批量大小决定了训练或推理期间每次迭代处理的数据样本数量。)
BATCH_SIZE = 8
数据集准备
这个类将使我们能够轻松地处理我们的数据。
- 代码的第一部分准备要处理的数据集。它从 DataFrame 中提取列标签和数据,存储用于文本转换的标记器,并计算要处理的最大文本长度。
- 第二部分通过计算数据集包含的数据样本数量来返回数据集的长度。
- 第三部分从数据集中检索输入(x)和输出(y)序列,将它们组合成单个文本,使用标记器对文本进行标记,并返回标记化的表示形式。
- 最后,最后一个函数计算数据集中文本数据的最大长度。它在 DataFrame 的指定列中找到最长的序列,将其四舍五入到最接近的 2 的幂,并返回结果。
注意:使用 2 的幂作为最大序列长度可以优化神经网络计算并简化内存分配,从而提高训练和推理的效率。
class LanguageDataset(Dataset):
def __init__(self, df, tokenizer):
self.labels = df.columns
self.data = df.to_dict(orient='records')
self.tokenizer = tokenizer
x = self.fittest_max_length(df)
self.max_length = x
def __len__(self):
return len(self.data)
def __getitem__(self, idx):
x = self.data[idx][self.labels[0]]
y = self.data[idx][self.labels[1]]
text = f"{x} | {y}"
tokens = self.tokenizer.encode_plus(text, return_tensors='pt', max_length=128, padding='max_length', truncation=True)
return tokens
def fittest_max_length(self, df):
max_length = max(len(max(df[self.labels[0]], key=len)), len(max(df[self.labels[1]], key=len)))
x = 2
while x < max_length: x = x * 2
return x
data_sample = LanguageDataset(df, tokenizer)
训练和验证
与经典机器学习模型一样,我们将首先定义训练(80%的数据)和验证数据
train_size = int(0.8 * len(data_sample))
valid_size = len(data_sample)-train_size
train_data,valid_data = random_split(data_sample,[train_size,valid_size])
数据加载器设置
数据加载器用于帮助我们根据我已经提供的批次大小(乘以 8)将数据输入模型
train_loader = DataLoader(train_data,batch_size=BATCH_SIZE,shuffle= True)
valid_loader = DataLoader(valid_data,batch_size=BATCH_SIZE)
训练参数
- “num_epochs”:指定模型在训练期间遍历整个数据集的次数(10)。
- “batch_size”:确定训练期间每次迭代处理的数据样本数量(8)。
- “model_name”:我们的模型“distilgpt2”
- “gpu”:表示我们是否要使用 GPU 进行训练。值 0 通常表示使用 GPU。
- “criterion”:定义用于衡量训练期间预测值和实际值之间差异的损失函数。我使用了 Cross Entropy Loss,它适用于多类分类问题。
- “优化器”:这是用于在训练期间更新模型参数的优化算法。我使用了 Adam 优化器,学习率为 5e-4(你可以选择任意值)。
- “tokenizer.pad_token”:将标记器的填充标记设置为序列结束标记(EOS)。
num_epochs = 10
batch_size = BATCH_SIZE
model_name = 'distilgpt2'
gpu = 0
criterion = nn.CrossEntropyLoss(ignore_index = tokenizer.pad_token_id)
optimizer = optim.Adam(model.parameters(), lr=5e-4)
tokenizer.pad_token = tokenizer.eos_token
我们还将创建一个 Dataframe 来存储模型性能,并在每次迭代后更新
results = pd.DataFrame(columns=[
'epoch', 'transformer',
'batch_size', 'gpu',
'training_loss', 'validation_loss',
'epoch_duration_sec'
])
训练
在这部分代码中,我们有训练循环,其中模型被训练了指定的周期数(num_epochs,在我们的例子中是 10)。在每个周期中,循环都会遍历训练数据,计算损失,并使用反向传播更新模型的参数。
# The training loop
for epoch in range(num_epochs):
start_time = time.time() # Start the timer for the epoch
model.train()
epoch_training_loss = 0
train_iterator = tqdm(train_loader, desc=f"Training Epoch {epoch+1}/{num_epochs} Batch Size: {batch_size}, Transformer: {model_name}")
for batch in train_iterator:
optimizer.zero_grad()
inputs = batch['input_ids'].squeeze(1).to(device)
targets = inputs.clone()
outputs = model(input_ids=inputs, labels=targets)
loss = outputs.loss
loss.backward()
optimizer.step()
train_iterator.set_postfix({'Training Loss': loss.item()})
epoch_training_loss += loss.item()
avg_epoch_training_loss = epoch_training_loss / len(train_iterator)
# Validation
model.eval()
epoch_validation_loss = 0
total_loss = 0
valid_iterator = tqdm(valid_loader, desc=f"Validation Epoch {epoch+1}/{num_epochs}")
with torch.no_grad():
for batch in valid_iterator:
inputs = batch['input_ids'].squeeze(1).to(device)
targets = inputs.clone()
outputs = model(input_ids=inputs, labels=targets)
loss = outputs.loss
total_loss += loss
valid_iterator.set_postfix({'Validation Loss': loss.item()})
epoch_validation_loss += loss.item()
avg_epoch_validation_loss = epoch_validation_loss / len(valid_loader)
end_time = time.time()
epoch_duration_sec = end_time - start_time
new_row = {'transformer': model_name,
'batch_size': batch_size,
'gpu': gpu,
'epoch': epoch+1,
'training_loss': avg_epoch_training_loss,
'validation_loss': avg_epoch_validation_loss,
'epoch_duration_sec': epoch_duration_sec}
results.loc[len(results)] = new_row
print(f"Epoch: {epoch+1}, Validation Loss: {total_loss/len(valid_loader)}")
测试并保存模型
现在我们已经训练了模型,是时候测试它了!我输入了“恐慌症”,并将其标记化以生成输出,同时考虑了一些超参数。这些超参数包括温度等较流行的参数和 top_k 和 top_p 等不太流行的参数。
input_str = "Panic disorder"
input_ids = tokenizer.encode(input_str, return_tensors='pt').to(device)
output = model.generate(
input_ids,
max_length=20,
num_return_sequences=1,
do_sample=True,
top_k=8,
top_p=0.95,
temperature=0.5,
repetition_penalty=1.2
)
decoded_output = tokenizer.decode(output[0], skip_special_tokens=True)
print(decoded_output)
#Output : Panic disorder | Palpitations, Sweating, Trembling (fever or headache),

科学模因。图片来源:https://knowyourmeme.com/memes/finally-synthetic-watermelon/photos
文章到此结束,我们探索了针对医疗保健的小型语言模型的训练,特别关注疾病症状。利用 Hugging Face 的数据集,我们使用 DistilGPT2 模型(GPT-2 的轻量级版本)来完成我们的任务!请继续关注更多见解和实用技巧,以增强您的医疗保健建模之旅!建模愉快!

RA/SD 衍生者AI训练营。发布者:稻草人,转载请注明出处:https://www.shxcj.com/archives/3831