
了解混合专家 (MoE)
混合专家 (MoE) 是一种机器学习技术,它将多个“专家”神经网络模型组合成一个更大的模型。MoE 的目标是通过组合专业专家(每个专家专注于不同的子领域)来提高 AI 系统的准确性和能力。


MoE 模型的一些关键特征:
- 由多个专家神经网络组成,专注于更大问题空间的专门子域
- 包括门控网络,用于确定针对每个输入使用哪个专家
- 专家可以根据自己的专业调整不同的神经网络架构
- 训练同时涉及专家和门控网络
- 可以比单一模型更好地对复杂多样的数据集进行建模
例如,专注于计算机视觉任务的 MoE 模型可以有专门识别不同类型物体(如人、建筑物、汽车等)的专家。门控网络将确定针对输入图像的每个区域使用哪个专家。
MoE 提供的一些好处:
- 通过结合专家来提高准确性
- 可扩展性,因为可以为新任务/数据添加专家
- 由于每个专家都专注于一个子领域,因此具有可解释性
- 模型优化,因为专家可以有不同的架构
MoE 在提升 AI 系统的大型神经网络建模能力方面表现出了巨大的潜力。然而,如何有效地训练和部署 MoE 模型(尤其是在非常大规模的情况下)仍然存在挑战。
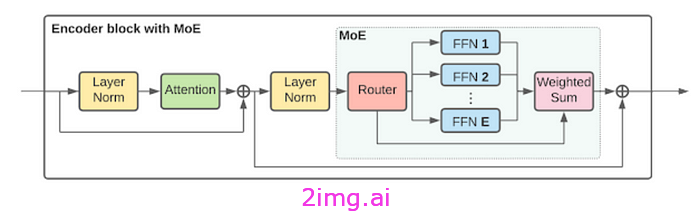
混合专家 (MoE) 架构
混合专家模型由几个协同工作的关键组件组成:
专家神经网络
专家是专注于解决特定类型的问题或处理某些输入模式的个体专业模型。通常,神经网络用于利用表征学习。每个专家只能看到一部分数据。
例如,在文本分类中,一位专家可能专注于检测垃圾邮件,而另一位专家则专注于识别积极情绪。
他们通常同时接受发送给他们的样本的训练。现代 MoE 可能包含数百或数千名专家。
门控网络
门控网络负责根据可学习的注意力得分将每个输入查询动态路由到相关专家网络。它查看输入特征和全局上下文,并输出要激活的专家的软概率分布。
由于每个样本只需要执行稀疏的专家子集,因此将专家混合模型确立为条件计算模型。门控网络决定激活整体模型的哪些部分。
路由器
路由器接收门控分布和查询输入,并选择一个或多个专家网络进行相应处理。常见的选择方法包括 top-k、噪声 top-k 和更复杂的分层混合,以减少计算负载。
在某些版本中,路由器会查询多个专家并根据标准化分数组合他们的输出。
需要进步
虽然 MoE 已显示出显着的准确性和能力提升,但要真正释放下一代 AI 所需的极端规模的模型能力,还需要取得一些重要的进步:
更高效的推理
由于每个示例的门控成本,使用非常大的 MoE 模型运行推理(进行预测)可能具有挑战性且成本高昂。随着模型规模的增加,如果不进行优化,门控计算会变得非常缓慢且成本高昂。
训练稳定性和收敛性
随着专家数量的增加,MoE 模型的训练过程趋于不稳定,难以收敛到最优解。我们需要在训练方法上取得新进展,以利用数千甚至数百万专家。
专用硬件
为了提供速度、规模和成本效益,训练和运行大型 MoE 模型推理所需的计算硬件可能需要专门化。
模型并行性
为了达到全脑水平智能所需的大规模,将 MoE 训练和推理分散到多个设备(如多 GPU 或云基础设施)上的极端模型并行性将至关重要。
我相信基于 MoE 的模型有潜力解锁变革性的下一代人工智能——将模型从狭义或专业智能推进到通用人工智能 (AGI)。但仍需取得一些重要进展,以改进大规模推理、训练效率并利用专用硬件。
大规模 MoE 推理
在极大规模下运行基于 MoE 的模型推理面临着几个独特的优化挑战:
每个示例的门控成本
每个推理查询都需要先通过门控网络来确定路由到相关专家。对于巨型模型,这种每个示例的门控成本可能会变得非常缓慢且昂贵。
高内存带宽使用率
门控计算需要同时集中访问所有专家的信息以确定路由,从而导致非常频繁的随机内存访问模式。这限制了没有内存优化的推理吞吐量。
更有效的大规模 MoE 推理的一些进步包括:
门控共享
门控网络计算在输入示例批次之间共享。通过批处理,每个示例的成本被摊销,从而使门控函数更加高效。
专家级并行
专家本身被分布在多个加速器上进行并行计算,从而增加了总推理吞吐量。
分级门控
多级分级门控网络用于拥有专门的本地路由器,这些路由器将信息全局传输给相关专家。这在保持效率的同时提高了准确性。
模型压缩
蒸馏和修剪等模型压缩技术的变体被应用于门控网络和专家,以优化内存使用和访问模式。
专用硬件
Google TPU-v4 Pod 等定制硬件具有针对 MoE 等模型量身定制的内置软件和内存优化,可将推理速度提高 10 倍以上。
随着模型规模从现在起增加 100 倍甚至 1000 倍,围绕分层门控、自动专家架构搜索和硬件-软件协同设计等领域的新优化可能会出现,以保持可处理的推理。
MoE 推理引擎的效率对于实现全脑规模智能至关重要,它可以无缝处理跨文本、图像、语音、代码、控制策略和任何数据模式的多领域推理。
教育部培训的进步
尽管 MoE 有望通过整合众多专家来提高模型能力,但模型训练过程带来了一些挑战,尤其是在极端规模下。最近的一些进展使大规模 MoE 训练更加稳定和可实现:
一对一专家数据映射
训练数据的独特子集可以明确映射到相关专家,从而使他们在语义上进行专门化。这提高了整体收敛性。
异步模型复制
专家集异步复制以创建维护训练进度的备份。删除表现不佳的专家不会丢失关键训练信号。
可学习的门控逻辑
使门控逻辑本身的某些部分可微分且可调,有助于在专家不断进行专业化迭代时动态路由数据。允许自我调整以实现稳定性。
专家架构搜索
根据实时训练收敛情况自动搜索专家神经架构构建块。通过学习路由可以完全避免不良架构。
基于噪声的专家正则化
在训练期间向专家可用性中随机注入像 Dropout 这样的噪声使得路由对缺失专家具有鲁棒性,避免在特定的专家子集上过度拟合。
这些创新共同提高了训练稳定性。这使得 MoE 模型拥有数千名专家,而之前的研究只有数百名专家。
然而,关于如何用数百万甚至数十亿专家训练模型的最佳技术,仍有许多悬而未决的问题。必须出现围绕渐进分层训练、循环、终身专家重放和冲突处理的新方法,以防止天文规模的有害专家干扰。
下一代人工智能用例
高效大规模推理、稳定分布式训练和专业硬件优化等领域的进步将有助于在未来几年内实现具有数千亿到数万亿个参数的 MoE 模型。如此巨大的扩展能带来什么?
多任务、多模式人工智能助手
人类可以在视觉、语言、声音和其他感官模式之间无缝切换。同样,拥有 1000 倍以上专家的全脑 MoE 模型可以同时处理文本、图像、语音、视频和感官流。这使得多任务 AI 助手能够共享全模式表示和专业知识。
超个性化推荐
细粒度的专家专业化允许不同的专家对电影、旅游目的地、播客、书籍等不同领域的用户兴趣进行建模。通过为每个用户动态组合专业专家,他们可以根据狭窄的领域提供个性化推荐。
科学与技术发现
领域专家组可以吸收全部科学论文、患者健康数据、基因数据集或任何技术资料,从而识别新的联系。这加速了假设的产生和实验,促进了科学和工程领域的进步。
稳健的控制政策
大量专家可以专注于处理跨环境、任务、干扰和执行器动态的机器人控制的极端情况。通过混合和匹配专业专家来处理新场景,MoE 系统可以一起学习稳健的策略。
所涵盖的专业知识的广度、学习新领域的速度以及通过发明动态组合专业技能的方法而实现的任务灵活性是扩大的 MoE 模型的独特优势,是任何其他技术都无法比拟的。
挑战与未来方向
虽然最近的进展表明,基于 MoE 的模型有潜力扩展到数万亿个参数,从而实现多任务、多模式 AI,但仍存在许多悬而未决的挑战:
信息隔离
确保有用的专业化而不受有害干扰需要专家之间保持信息隔离。过早的冲突会导致混乱的表述。自上而下的信号必须集中专业知识,自下而上的混乱检测需要通过门控调整来解决。
发明缺失的专家
数十亿专家无法手动列举所有有用的技能。必须发明自动化流程,通过重组基本技能来为稀有任务产生专家。终身自我监督的长尾需求聚类至关重要。
新兴系统性
简单的记忆无法捕捉底层结构。门控和专家聚类数据之间的交互必须产生系统解开的概念表征。应该会出现类似语法的组合概括。
高效的信用分配
随着数十亿专家独立进步,确定系统进步的因果贡献对于有针对性的放大来说变得极为复杂。无关信号会稀释需要稀疏性的有用方向。
安全探索
对新可能性的无限想象需要在实现之前判断其是否符合伦理道德。驱动全能专家的好奇心必须以同情心为首要因素。
未来的方向包括围绕一致性、最佳传输、共识动态和信息瓶颈开发数学框架,这些框架专门针对 MoE 系统独有的动态和规模而设计。

结论
推进混合专家技术以实现解决多领域挑战的下一代人工智能需要重新思考学习、泛化、因果关系和安全的基本原则,同时在特定规模的训练、推理和硬件架构上进行创新。未来十年的 MoE 有望成为人工智能革命的激动人心的前沿!
Paragoger衍生者AI训练营。发布者:稻草人,转载请注明出处:https://www.shxcj.com/archives/3798