


GPT-4、LlaMA、Falcon、Claude、Cohere、PaLM 等大型语言模型 (LLM) 已展示出强大的自然语言生成、推理、摘要、翻译等功能。然而,要有效利用这些模型来构建自定义应用程序,需要克服非同小可的机器学习工程挑战。
LLMOps 旨在提供一个精简的平台,使开发团队能够有效地将不同的 LLM 集成到产品和工作流程中。
在这篇博客中,我将介绍实现企业级 LLMOps 平台的最佳实践和组件,包括使用开源和商业 LLM 的模型部署、协作、监控、治理和工具。
构建 LLM 驱动的应用程序的挑战
首先,让我们来看看 LLMOps 平台旨在解决的一些关键挑战:
- 模型评估——严格对不同 LLM 的准确性、速度、成本和能力进行基准测试
- 基础设施复杂性——在高并发性下提供并扩展生产中的 LLM
- 监控和调试——模型行为和预测的可观察性
- 集成开销——将 LLM 与周围的逻辑和数据管道进行接口
- 协作——使团队能够共同构建模型
- 合规性——遵守数据隐私、地理和人工智能伦理方面的法规
- 访问控制——管理模型授权并保护 IP
- 供应商锁定——避免过度依赖单个供应商
LLMOps 平台封装了这种复杂性,使开发人员能够专注于他们的自定义应用程序逻辑。
接下来,让我们探索一下高级架构。
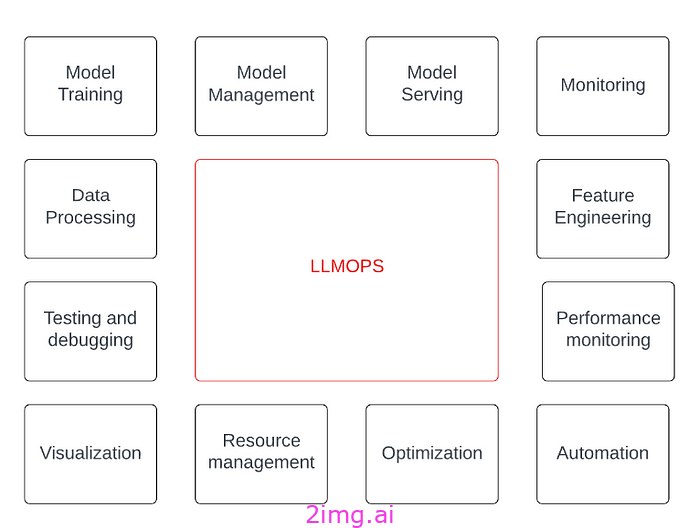
LLMOps 平台架构
LLMOps 平台架构由以下核心组件组成:
实验沙箱
笔记本环境用于在专有数据集上安全评估 GPT-4、LlaMA、Falcon、Claude、Cohere、PaLM 等 LLM。
模型注册
具有功能、性能和集成详细信息的 LLM 目录。
模型服务
可扩展的无服务器或容器化的 LLM 部署以用于生产。
工作流编排
将 LLM 链接在一起形成连贯的工作流程和管道。
监控和可观察性
跟踪关键模型性能指标、漂移、错误和警报。
访问控制和治理
基于角色的访问、模型审计和监督护栏。
开发人员体验
SDK、文档、仪表板和工具可简化直接模型集成。
让我们通过实施细节和开源工具进一步探索每个领域。
实验沙箱
数据科学家和开发人员需要沙盒环境来安全地探索不同的 LLM。
这允许在不受操作限制的情况下对模型、超参数、提示和数据提取的组合进行迭代。
例如,利用以下工具:
- Google Colab——基于云的笔记本环境
- 权重和偏差——实验跟踪和模型管理
- LangChain——简洁的 Python LLM 集成
- HuggingFace Hub——访问数千个开源模型
所需的关键能力包括:
- 轻松获得开源和商业大语言模型学位
- 实验的自动版本控制
- 跟踪超参数、指标和工件
- 与生产系统隔离——对完整性至关重要
沙箱允许自由创新,同时无缝捕获完整的上下文以实现成功的方法。
模型注册
模型注册表是经过审查并获准用于申请的大语言模型的记录系统。它跟踪:
- 模型元数据——类型、描述、功能
- 性能基准——速度、准确性、成本
- 模型输出示例
- 训练数据和方法摘要
- 限制和约束——数据类型、大小限制、配额
- 集成细节——语言、SDK、端点
例如,模型注册表项:
name: GPT-4 Curie
type: Generative, few-shot learning
description: High-performing multipurpose LLM for natural language
benchmark:
accuracy: 90%
latency: 200ms
cost: $0.002/1k tokens
capabilities:
- Natural language generation
- Classification
- Sentiment analysis
- Summarization
- Grammar correction
constraints:
- Max sequence length: 2,000 tokens
- No audio, image inputs
- Rate limited to 10k tokens daily
integrator_guide: https://wiki.com/gpt4
sdk:
- Python
- Node.js
- Java
endpoint:
- https://openai.com/api/curie
这种统一的视图可以帮助团队在遵守约束的同时有效地评估和选择最适合他们需求的模型。
模型服务
LLMOps 需要优化、可扩展的基础设施,以低延迟、完整性和成本效益的方式为生产中的模型提供服务。
模型服务的一些好的选择包括:
无服务器
AWS Lambda 和 Azure Functions 等工具提供自动扩展、事件驱动的模型托管:
import openai
def handler(event, context):
prompt = event["prompt"]
response = openai.Completion.create(prompt=prompt)
return response
容器
Docker 容器允许打包模型和依赖项:
dockerfile
FROM python
RUN pip install openai
COPY model.py .
CMD ["python", "model.py"]
Kubernetes
Kubernetes 等编排器可以管理和扩展容器:
apiVersion: apps/v1
kind: Deployment
metadata:
name: gpt4
spec:
replicas: 3
selector:
matchLabels:
app: ai
template:
metadata:
labels:
app: ai
spec:
containers:
- name: gpt4
image: gpt4:v1
NVIDIA Triton、Seldon Core 和 Algorithmia 等工具简化了部署。
优化的服务确保模型在生产中具有最佳的性能、规模和可用性。
工作流编排
复杂的工作流可以将多个 LLM 链接在一起:
例如:
- 总结 + 翻译
- 匿名化数据 → 清理 → 分析
- 转录演讲 → 翻译 → 总结会议
主要要求包括:
- 跨模型传递输入和状态
- 处理错误和部分失败
- 监控工作流程步骤
- 重试失败的模型调用
- 负载平衡和池化模型
- 工作流版本控制和重用
Metaflow、Prefect、Apache Airflow 和 Argo Workflows 等工具有助于大规模协调 LLM 工作流程。
监控和可观察性
仔细监控可以发现模型性能问题和偏差,以防止下游影响。
指标如下:
- 预测准确率
- 精确度和召回率
- 延迟分布
- 错误率
- 每次预测的成本
- 输入/输出尺寸分布
需要使用以下工具进行集中聚合:
- 普罗米修斯
- Datadog/Dynatrace
- 松紧带
- Grafana 仪表板
警报有助于快速检测关键指标的异常。
访问控制和治理
对于敏感数据,强大的访问控制和审计至关重要。所需功能:
- 基于角色的模型和特征访问
- 限制使用的配额
- 模型审计日志
- 用于监控的数据屏蔽
- 发布模型的审批工作流程
- 管道质量门
- 模型谱系追踪
Seldon Core、Verta、MLFlow 和 Amundsen 等工具提供模型和元数据治理。
治理在开放实验与生产完整性之间取得平衡。
开发人员体验
对于直接模型集成,数据科学家和开发人员需要出色的工具,包括:
- 特定语言的 SDK — Python、Java、JS
- 交互式 API — Jupyter、Streamlit
- 低代码集成——CLI、无代码工具
- 自动化文档 — SDK 参考
- 客户端缓存——避免重复查询
- 可解释性库——LIME、SHAP
- 反馈循环——Jira、Slack
这使得模型的使用和协作变得无摩擦。
现在让我们看一个示例工作流程。
示例工作流程
以下是使用该平台构建和部署自定义 LLM 应用程序的端到端工作流程示例:
Bijit 是一名数据科学家,他希望构建一个用于帮助文章的智能搜索助手。他遵循以下工作流程:
- 在实验沙箱中,Bijit 尝试将 GPT-4 用于自然语言查询理解,与 Anthropic 的 Claude 用于文章排名功能。
- 他使用权重和偏差来记录混合方法的准确性、成本和延迟等关键指标以跟踪实验。
- 一旦对结果有信心,他就会打包模型端点并记录集成情况。
- Bijit 在模型注册表中添加了一个条目,详细说明了其模型的功能、约束和性能基准。
- LLMOps 团队与 Bijit 合作,通过优化 TensorFlow Serving 容器并将其部署到专为规模、安全性和可靠性而设计的 Kubernetes 上,将其模型投入生产。
- 应用程序开发人员利用新推出的智能搜索 SDK 和文档将 Bijit 的模型集成到他们的帮助门户中。
- 在生产过程中,会监控模型的查询延迟、准确率下降和偏离原始基准的情况。警报会将任何异常情况通知 Bijit 和团队。
这种简化的工作流程允许快速实验和顺畅的协作来构建自定义的 LLM 支持的应用程序。
主要建议
以下是实施企业 LLMOps 平台时的一些建议:
- 提供沙盒环境以开放探索模型
- 管理模型注册表以指导适当的使用
- 为大语言模型 (LLM) 量身定制专业服务基础设施
- 支持将多个模型编排到工作流中
- 仪器模型行为深度监测
- 预先建立治理和访问控制
- 大力投资开发人员体验——SDK、文档、工具
- 将平台功能与应用程序路线图保持一致
- 敏捷规划——新模型、框架和技术将不断涌现
LLMOps 平台的最新趋势和未来
LLMOps 是一门新兴学科,其格局正在快速演变。让我们探索最新趋势和即将出现的变化,以帮助指导您的平台战略。
大语言模型 (LLM) 的 AutoML
自动化机器学习(AutoML)可以通过自动化死记硬背调整、超参数搜索、提示工程和结果分析来帮助优化和找到最适合任务的大型语言模型。
AutoML 可以高效地对一组 LLM 进行基准测试,以了解其准确性、速度、能力匹配度和成本。Darwin、TransmogrifAI 和 Google Cloud AutoML 等工具可实现无需干预的 LLM 优化。
与手动评估相比,这些技术可以持续领先于新的性能更佳的模型。AutoML 简化了利用 LLM 组合的过程。
精简模型部署
大多数主流 LLM 在推理方面对计算要求很高,需要大量硬件加速。精简部署侧重于通过以下方式优化边缘设备和移动设备的模型:
- 知识蒸馏——将知识从大模型转移到小模型
- 量化——转换为较低精度,如 INT8
- 修剪——删除冗余权重
- 高效架构——以移动为中心的模型设计
这允许在客户端上解锁实时 LLM 应用程序。TensorFlow Lite、ONNX Runtime 和 Intel OpenVINO 等工具包简化了精简版部署。
MLOps 融合
LLMOps 工作流与 MLOps 堆栈更加紧密地交织在一起,以实现更广泛的模型管理,涵盖传统 ML 模型、大型语言模型和语音/视觉模型。
统一的 MLOps 平台简化了工具,提高了团队之间的重用性,并为熟悉 MLOps 模式的平台工程师提供了技能经济性。LLM 可以视为从更广泛的 MLOps 工作流中调用的模块,专注于数据集管理、模型再训练、A/B 测试和集成粘合等挑战。
低代码/无代码集成
公民开发平台正在将 LLM 访问权限扩展到技术角色之外。集成模板、声明式配置和可视化工作流构建器为业务用户提供了直观的界面来利用 LLM。
PaLM、Anthropic、Cohere 和 Hive 等供应商允许使用 LLM 以最少的编码来定制应用程序。这些供应商在保持监督的同时,实现了福利的民主化。
负责任的 AI 护栏
随着 LLM 在影响最终用户和决策的应用中变得越来越普遍,对偏见、毒性和可解释性等指标的保护变得至关重要。平台正在扩展以评估整个模型生命周期中的道德 AI 问题,并提供生产模型行为及其对人的影响的透明度。
地缘政治变量
围绕国内模型开发、数据本地化和技术自力更生的更大经济、政治和国家安全考虑可能会影响供应商的选择和能力。随着 LLM 对竞争力越来越重要,地缘政治可能会影响平台的方向。适应能力将是关键。
最佳实践的演进
LLMOps 最佳实践仍在不断变化和完善中。随着经验的积累,我们预计架构、工具、工作流和开发方法将快速发展。保持敏捷、前瞻性和持续整合学习成果将有助于优化您的堆栈。与信誉良好的供应商合作将为您提供应对不确定性的指导。
前方的路
LLMOps 旨在将 LLM 从孤立的实验转变为嵌入到工作流程中并提供环境协助的完整组件。
策划最佳模型组合、智能地自动执行死记硬背的任务、实现访问民主化以及保持监督将是未来的重点关注领域。今天构建面向未来且适应性强的平台,可以无缝驾驭该领域即将到来的创新浪潮。
结论
我探索了实施端到端 LLMOps 平台的最佳实践,其中包括:
- 实验沙箱
- 模型注册和治理
- 大规模服务基础设施
- 工作流编排
- 监控和可观察性
- 开发人员体验,包括 SDK 和工具
这为开发人员提供了一个简化的环境,以构建由 GPT-4、LlaMA、Falcon、Claude、Cohere、PaLM 等 LLM 提供支持的自定义应用程序。
强大的 LLMOps 允许组织通过消除开销、实现协作、维护完整性以及弥合从实验到生产部署的差距来挖掘 LLM 的巨大机遇。
通过编码和扩展专门的工作流程,LLMOps 旨在将大型语言模型从孤立的演示转变为支撑智能应用程序和服务的核心组件。

Paragoger衍生者AI训练营。发布者:稻草人,转载请注明出处:https://www.shxcj.com/archives/3785