

概述
毫无疑问,目前最受关注且不断发展的最重要的主题之一是使用人工智能生成图像、视频和文本。大型语言模型 (LLM) 已展示出其在文本生成方面的卓越能力。它们在文本生成方面的许多问题已得到解决。然而,LLM 面临的一个主要挑战是它们有时会产生幻觉反应。
最近推出的新模型(如新发布的 GPT-40)尤其令人惊叹。OpenAI 无疑正在改变游戏规则。此外,谷歌强大的模型 Gemini 1.5 Pro 极大地改变了我们的看法。因此,我们可以看到模型正在改进。轮子已经发明,现在必须加以改进。
最初,LLM 是为翻译任务而开发的。现在,我们看到它们执行各种任务,趋势是朝着多模态模型发展。Transformers 强大而重要的架构使这一切成为可能。
Transformers 可以执行的另一项任务是图像生成,如 DALL-E、Midjourney 或 Ideogram 等产品中所示。这些模型接受文本提示并生成图像。最近发布的 LlaMa 3 模型在编写文本提示时生成图像,并在我们修改文本时更改图像。
但更令人惊讶的是从文本生成视频。几个月前,OpenAI 推出了一款名为Sora的产品。它令人印象深刻,令人惊叹,能够生成高质量、高度逼真的图像,甚至可以创造其他世界。当我看到它时,我首先想到的是电影《黑客帝国》。
在本文中,我们将从头开始研究从文本生成图像和视频的想法,并追溯其演变过程。我们的目标是首先了解图像生成,然后了解视频生成,并研究用于这些任务的架构。
历史
第一批电影于 19 世纪 80 年代制作,令观众惊叹不已,为今天我们所知的强大的电影业奠定了基础。在电影制作中使用人工智能 (AI) 的概念出现于 20 世纪初,随着计算机的兴起而逐渐流行。1960 年,约翰·惠特尼 (John Whitney) 创立了 Motion Graphics Incorporated,并使用他的模拟计算机制作电影片段、电视剧名和广告,开创了计算机动画的先河。IBM于1966 年授予他第一位驻场艺术家职位,以表彰他的贡献。多年来,各种关于计算机生成的电影和动画的文章相继发表,为今天我们所知的 AI 在电影制作和表演艺术中的应用铺平了道路。21 世纪和21世纪的进步,包括深度学习算法和生成对抗网络 (GAN),进一步推动了 AI 在数字内容创作和编辑中的应用。下一节将探讨使用 Transformer 架构生成图像的可行性。
跨平台对抗网络TransGANs
生成对抗网络 (GAN) 由Ian Goodfellow及其同事于2014 年 ( Transformers 诞生之前) 提出,用于图像处理和其他任务。生成对抗网络
生成对抗网络 (GAN) 的概念早于 Transformer,涉及两个参与零和博弈的深度神经网络。第一个网络是生成器,它创建合成样本;第二个网络是鉴别器,它负责区分真实样本和合成样本。生成器的目标是生成可以欺骗鉴别器的样本,使其无法区分真实样本和合成样本。
Transformer 与 GAN 的结合(称为 TransGAN)表明,Transformer 既可以充当 GAN 中的生成器,也可以充当鉴别器。这些模型利用 Transformer 的优势来捕捉数据的复杂特征。这种方法在2021 年由Yifan Jiang、Shiyu Chang和Zhangyang Wang 发表的同名论文中进行了详细介绍。TransGAN:两个纯 Transformer 可以组成一个强大的 GAN,而且可以扩展
TransGAN 是 Transformer 生成对抗网络的缩写。该模型是一种 GAN,其生成器和鉴别器均采用 Transformer 架构。与传统 GAN 不同,TransGAN 不使用 CNN 作为生成器或鉴别器,而是同时采用 Transformer 结构。
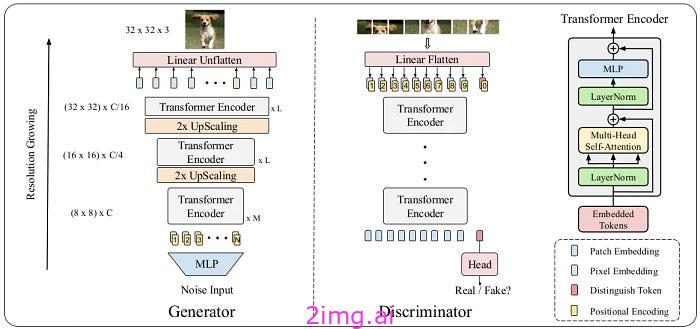
这幅图清晰地展示了 TransGAN 的架构以及生成器和鉴别器的结构。输入图像是一张 3×3 的彩色照片。来源
生成器Generator
在 TransGAN 中,生成器使用 Transformer 架构来生成数据序列。生成器从随机噪声输入开始,该输入通常是具有高斯(正态)分布的随机值的向量。此噪声输入被转换为更高维的特征空间。此阶段涉及多个前馈层和 MHA 层。
基于 Transformer 的生成器逐步生成数据序列。在每个步骤中,生成器生成一部分数据(例如,图像的一个像素),然后将此输出用作下一步的输入。注意力机制可帮助生成器对数据中存在的长期依赖关系和复杂性进行建模。
在生成完整的数据序列后,这些序列被转换成完整的样本(例如,完整的图像)。这种转换包括重建复杂的特征和最终的细节。
鉴别器Discriminator
TransGAN 中的 Discriminator 负责判断 Generator 生成的样本是真是假,它采用 Transformer 架构来分析生成的数据序列。
最初,鉴别器接收可能是真实图像或虚假图像的样本。这些样本作为图像块序列输入到模型中。每个图像块代表图像的一小部分,例如16×16像素块。每个图像块首先转换为矢量表示。此矢量表示通常通过嵌入层获得,该嵌入层将每个图像块转换为指定维度的矢量。然后将这些矢量与位置嵌入相结合,以保留每个图像块的空间信息。
然后将编码的块序列输入到多个多头注意力 (MHA) 层。这些层允许鉴别器对图像不同块之间的长期依赖关系和关系进行建模。MHA 帮助模型同时关注图像的不同特征。
注意力层的输出被输入到多个前馈层。这些层提取并处理组合特征,从而产生更复杂、更丰富的图像表示。然后,前馈层的最终输出被输入到聚合层。该层将所有提取的特征组合成一个综合表示。然后,这个综合表示连接到最后一层,例如密集层,最终决定图像是真是假。
在 GAN 中使用 Transformer 已显示出良好的效果。然而,与其他方法相比,TransGAN 的效率可能受到其对更多计算资源的依赖以及对更大训练数据集的需求的限制。换句话说,TransGAN 可能在具有足够计算资源和丰富训练数据的环境中表现良好。
ViTGAN
ViTGAN 模型是一种用于图像生成的新型深度学习模型,由Kwonjoon Lee及其同事于2022 年在一篇论文中提出。ViTGAN:使用 Vision Transformers 训练 GAN
该模型结合了Transformer模型和生成对抗网络(GAN),可以生成逼真的高质量图像。ViTGAN模型使用Transformer模型作为编码器。该模型处理输入token序列并生成一个隐藏向量,该向量存储有关图像内容的信息。ViTGAN利用GAN网络。生成器将隐藏向量转换为图像,而鉴别器则尝试确定图像是真实的还是假的。这两个网络同时训练,以便生成器可以生成更逼真的图像,而鉴别器可以更好地区分假图像。

ViTGAN 中的生成器和鉴别器都可以利用 Vision Transformer (ViT) 架构。在生成器端(左),它将随机输入块转换为图像。此过程包括多个转换器层,用于将随机输入转换为输出图像。在鉴别器端(右),它可以使用相同的 ViT 架构来处理图像。它将图像块转换为标记,然后使用转换器层来决定输入图像是真实的还是生成的。来源
ViTGAN 的优势之一是能够生成与真实图像相媲美的高质量图像。它还可用于生成各种类型的图像,包括人脸、风景和物体,非常适合制作 Deepfake 图像。ViTGAN 允许用户通过调整不同的模型参数来控制图像。
然而,与任何模型一样,ViTGAN 也有其缺点。首先是复杂性。ViTGAN 是一个复杂的模型,训练和使用起来可能具有挑战性,需要大量数据进行训练。它的速度也可能很慢,尤其是在用于生成高分辨率图像时。其最重要的应用之一是为网站、社交网络和其他平台创建视觉内容,以及增强现有图像的质量,例如提高分辨率或消除噪音。它还可用于创建新的图像格式,例如 360 度图像或交互式图像。
ViTGAN 是一种新的图像生成模型,有可能彻底改变图像的生成方式。然而,在广泛采用之前,需要解决一些与复杂性、数据要求和速度相关的挑战。
在 ViT 之前
在引入 Vision Transformer (ViT) 架构之前,许多图像处理任务(例如对象检测、图像字幕和图像生成)可以使用卷积神经网络 (CNN) 等模型或生成对抗网络 (GAN) 和变分自动编码器 (VAE) 等生成模型来实现。
例如,图像中的物体检测使用 CNN。其中最著名的一种是YOLO(You Only Look Once),这是一种 CNN 架构,它直接对整个图像作为输入进行操作,并快速准确地检测物体。另一种架构是R-CNN(基于区域的卷积神经网络)及其后继者,例如Fast R-CNN和Faster R-CNN。这些模型识别图像中的有趣区域,然后应用 CNN 检测这些区域中的物体,在物体检测方面取得良好的性能。
对于图像字幕,通常使用 CNN 和 RNN 的组合。首先,使用 CNN 从图像中提取特征。然后,将这些特征输入 RNN 或 LSTM(长短期记忆)网络以生成描述性文本。
对于图像生成,使用了 GAN(生成对抗网络)等生成模型。该模型包括两个相互竞争的网络——生成器和鉴别器。生成器创建新图像,鉴别器尝试将生成的图像与真实图像区分开来。此外,VAE(变分自动编码器)是另一种生成网络,用于通过学习输入数据的分布来生成新数据。
ViTGAN 与 TransGAN
ViTGAN 和 TransGAN 都融合了 GAN(生成对抗网络)和 Transformer 架构的元素,但它们在关键方面有所不同。在 ViTGAN 中,Vision Transformer 模型是生成器的主要组件,而 CNN(卷积神经网络)仍可用于鉴别器。该架构利用自注意力来有效捕捉图像细节。ViTGAN 旨在通过利用 Transformer 在建模像素之间的长期关系方面的优势来提高生成图像的质量。
另一方面,TransGAN 仅采用 Transformer 架构,而不依赖 CNN。这与常规做法有很大不同,因为大多数 GAN 模型都在一定程度上采用了 CNN。TransGAN 在生成器和鉴别器中都使用了 Transformer 模块。该模型的主要目标是通过利用 Transformer 中固有的自注意力机制来解决 GAN 中常见的学习和稳定性挑战。
综上所述,虽然 ViTGAN 和 TransGAN 都集成了 GAN 和 Transformer 概念,但 ViTGAN 将 Transformer 与 CNN 相结合,尤其是在鉴别器中,以提高图像生成质量。另一方面,TransGAN 的生成器和鉴别器都完全依赖于 Transformer 架构,旨在通过 Transformer 中自注意力的高级功能来解决常见的 GAN 挑战.
在“你只需要关注!”之后
在《Attention is All You Need》这篇介绍 Transformer 架构发展的论文发表后,出现了许多关于使用该架构生成视频和图像的文章和研究。2018年,Niki Parmar等人在一篇题为《 Image Transformer 》的论文中提出了使用 Transformer 架构进行图像生成的想法。图像转换器
Transformer 架构不使用线性序列进行文本处理,而是利用注意力机制来学习句子中单词之间的关系。《Image Transformer》论文表明,Transformer 架构可用于图像生成,方法是用像素替换单词,并使用注意力机制来学习图像中像素之间的关系。这使得 Image Transformer 能够理解图像模式并生成与输入图像风格和内容相似的新图像。这篇论文启发了该领域的大量研究,并促进了使用 AI 进行图像生成的新方法和更先进的方法的开发,例如 GAN(生成对抗网络)和扩散模型。
与以前的图像生成方法相比,Image Transformer 架构具有多项优势,包括更高的图像质量和更多细节。它还允许用户使用不同的参数更好地控制所生成图像的内容。最重要的是,它的计算效率更高,可以更快地生成图像。目前,我们看到 Image Transformer 应用于各种任务,例如生成艺术、幻想和抽象图像、编辑图像(例如更改颜色、添加细节和删除对象)、在视频游戏中生成逼真的图形、制作用于虚拟和增强现实的逼真图像和视频,以及许多其他不断更新和改进的应用程序。
在图像转换器中嵌入层
Image Transformer 使用嵌入层,但它们与用于处理文本的 Transformer 模型中的嵌入层不同。在 Image Transformer 中,必须将像素和图像信息转换为合适的向量空间。这通常由初始 CNN 层完成,然后是嵌入层。嵌入层将提取的特征转换为适合在 Transformer 网络中使用的向量空间。
嵌入阶段之后,Image Transformer 中的步骤与 Text Transformer 中的步骤类似。第一阶段是自注意力,借助位置编码等技术,帮助模型了解图像中每个块的相对位置。然后,模型将重点放在图像的重要部分。接下来是前馈阶段,帮助模型将信息从前几层传输到后续层。最后阶段涉及适合当前特定任务(例如图像分类或对象检测)的输出层。这些阶段在编码器中执行。
编码器-解码器图像转换器
在图像变换器架构中,编码器负责将输入(在本例中为图像)转换为特征空间。另一方面,解码器负责将特征空间转换为输出图像。图像变换器中的编码器采用标准变换器架构,并针对处理图像进行了多项修改。这些修改可能包括调整层或添加新层以更好地适应图像的特征。例如,在使用变换器架构处理图像时,通常使用 CNN 层或多头注意力 (MHA) 层,而不是基于文本的变换器架构中使用的自注意力层。此外,可以调整网络的架构和大小以适应图像的数量和复杂性。
类似地,图像 Transformer 中的解码器采用了标准 Transformer 架构,并进行了一些修改以方便生成图像。相比之下,文本生成 Transformer 中的解码器可以使用标准 Transformer 架构或经过修改的架构,例如自回归 Transformer。
例如,如果我们使用图像转换器根据描述性句子生成猫的图像,编码器将处理描述性句子并提取有关猫的各种特征的信息,例如形状、颜色和大小。空间注意力将帮助编码器专注于句子的关键部分,例如指代猫的颜色、形状和大小的单词。随后,解码器将利用编码器提取的信息来生成具有句子中描述的特征的猫的图像。
图像字幕
在使用文本生成 Transformer 描述图像时,模型必须能够从图像中识别出重要信息并将其以文本形式呈现。在此任务中,编码器块处理图像并提取有关图像中存在的对象、颜色和各种纹理的信息。基于序列的注意力机制可帮助编码器关注图像的重要部分,例如对象和关键细节。然后,解码器使用编码器提取的信息来生成描述图像的句子。
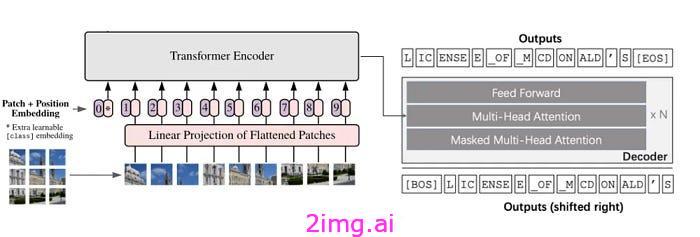
以下是使用 Transformer 架构进行图像字幕制作的步骤。来源
例如,如果有一张院子里有只狗的图片,模型应该能够提取狗的类型、颜色、毛皮质地、大小、在图片中的位置以及狗可能从事的活动(例如睡觉或玩耍)等信息,并用与这些信息一致的句子来描述它。一个例句可能是:“一只长毛的白狗正在院子里玩耍。”在这句话中,图像中的重要信息(狗的颜色、毛皮质地、在图片中的位置和活动)以文字形式描述。
接下来,我们将探索 Transformers 在生成或解释视频方面的应用和功能。请继续关注!
图像 Transformer 与文本生成 Transformer 的比较
这两种架构既有相似之处,也有不同之处。图像 Transformers 和文本生成 Transformers 都使用注意力机制,在处理和生成输出时专注于输入数据的特定部分。两种架构都使用编码器-解码器结构。编码器处理输入数据,解码器使用编码器提取的信息生成输出。两种架构都使用具有多层的深度神经网络来学习数据之间的复杂关系。
然而,这两种架构之间的差异主要在于它们的任务。图像 Transformer 是为处理和生成图像而设计的,而文本生成 Transformer 是为处理和生成文本而设计的,因此它们处理的数据类型不同。
最重要的区别之一是,在 Image Transformer 架构中,空间注意力用于在处理和生成过程中关注图像的不同部分。空间注意力包括两个主要阶段。第一阶段是计算注意力值,其中模型计算图像中每个像素的注意力值。该值表示模型对该像素的关注程度。可以使用小型神经网络为图像中的每个像素预测注意力值,或者使用高斯函数等函数根据像素与图像中心之间的距离计算注意力值。
计算注意力后,这些值将用于调整与每个像素相关的信息的权重。这意味着注意力值越高的像素对模型的输出影响就越大。应用注意力值的方式有很多种,例如将每个像素的注意力值乘以相应的像素权重,或者计算所有像素信息的加权平均值。
使用空间注意力机制的诸多优势包括帮助模型专注于图像的重要部分以产生更准确的输出、忽略图像中的噪声和不相关信息,以及在最终输出中保留细节和细微特征。相比之下,文本生成 Transformers 使用顺序注意力机制来关注句子中的不同单词。
问题
我们正在探索的问题是为什么过去没有将 Transformer 模型用于图像。有几个主要原因需要考虑。首先,由于计算复杂性,使用 Transformer 处理图像需要大量内存和计算,而考虑到图像的尺寸很大,这很有挑战性。另一个原因是,与具有时间序列的语言相比,图像数据的结构性较低。图像具有不同的结构,需要对模型进行调整和调整。此外,Transformer 模型需要大量正确标记的数据进行训练,这在过去很难获得。在下一节中,我们将深入研究使用 Transformer 生成视频的视频变压器网络 (VTN) 的架构。敬请期待!
视频转换网络 (VTN)
2021 年,由Daniel Neimark、Omri Bar、Maya Zohar 和 Dotan Asselmann撰写的研究论文发表。该论文讨论了视频变换器网络 (VTN),并重点推进了用于视频生成的 Transformer 架构。它旨在开发用于视频制作的 Transformer 架构。
视频转换网络
本文介绍了一种基于 Transformer 的视频识别框架 VTN。受到视觉领域最新发展的启发……
在这篇论文发表之前,大多数 Transformer 主要用于自然语言处理和文本生成。然而,“视频 Transformer 网络”提出了一种专门为视频生成而设计的 Transformer 架构。该架构可以将图像序列作为输入并创建新的视频。该模型使用自学习功能来理解时间模式和多媒体视角,从而制作出更真实、更高质量的视频。让我们仔细看看这个架构是如何运作的。在 VTN 架构中,与传统的 Transformer 模型类似,采用编码器-解码器结构来处理和生成序列。编码器从输入的视频帧中提取特征,而解码器生成新的视频序列。
嵌入 VTN 的方法
在视频转换网络 (VTN) 中,编码器和解码器都使用了嵌入。嵌入本质上是将文本或视觉输入转换为模型可以访问的低维空间,从而减少处理所需的信息量,同时保留重要细节。
在编码器中,嵌入将图像或视频特征转换到嵌入空间以提取必要信息。在解码器中,嵌入用于将先前的输出(例如文本模型中的单词或视频模型中的帧)转换到嵌入空间,使模型能够理解并使用相关信息来生成下一个输出。
此外,VTN 广泛使用自注意力机制来捕获视频帧内和帧之间的长距离依赖关系。这意味着该模型可以识别和理解帧之间的时间和语义关系,从而能够制作连贯而逼真的视频。此功能使模型能够学习复杂的时间关系并生成一致的视频序列。
自注意力机制在 VTN 中的作用
VTN(视频转换网络)为视频序列中的每一帧计算一个注意力矩阵。该注意力矩阵用于为每个帧分配权重,表示其在生成当前帧中的重要性。通过考虑帧之间的关系并使用序列中所有帧的信息,VTN 可以生成连贯的视频,捕捉帧之间复杂的时间关系。
VTN 的应用
视频转换网络 (VTN) 的引入为该领域的研究和开发开辟了新途径,从而显著提高了视频生成能力。VTN 可以生成时间和空间上连贯的逼真视频。此功能在内容生成、动画和视频编辑等应用中特别有用。它们可以帮助模型更好地理解视频内容,这对视频分析、视频中的物体检测、监控视频和运动预测等任务大有裨益。
只需一张静态图像,VTN 便可以生成一系列传达相同概念的视频。它们可以重建视频序列中缺失或损坏的区域,同时保留周围帧的连贯性。VTN 可以通过生成保留主要内容和细节的高分辨率序列来提高低质量视频的清晰度。
VTN 的一个重要应用是从文本提示或其他类型的数据生成视频。今天推出的先进模型(例如Vidu 和 Sora)利用此功能来制作逼真而复杂的视频。
VTN 的引入激发了许多后续研究,这些研究深入研究和改进 Transformer 架构在视频生成的应用。研究人员致力于创建更高效的模型,能够同时更准确地处理空间和时间信息。例如,使用时间注意机制旨在改进时间注意机制,以更好地建模视频帧之间的关系,或使用扩展 Transformer 模型以同时处理空间和时间信息的时空 Transformer。
与旧模型相比,VTN 解决了一些弱点。例如,传统上用于处理时间序列的循环神经网络 (RNN) 和 LSTM 通常难以有效捕获长期依赖关系。VTN 通过利用自注意力机制克服了这些限制。与 RNN 相比,Transformer 通常表现出更好的可扩展性,并且可以有效处理更大、更复杂的数据集。
VTN 与图像变换的区别
图像变换处理修改单个图像,而 VTN 用于创建视频序列,需要考虑帧之间随时间变化的连接。在 VTN 中,自注意力专门用于捕获这些长距离依赖关系,包括连续帧中的细微变化或整个视频中的整体运动。另一方面,图像变换技术主要关注图像的空间特征。因此,图像变换技术和 VTN 之间的关键区别在于它们如何处理时间和空间信息。
视频视觉转换器(ViViT)
ViViT 架构由谷歌研究部门在 2021 年的一篇论文中提出,旨在使用变换器模型处理和分析视频数据。
ViViT:视频视觉转换器
我们提出了基于纯 Transformer 的视频分类模型,借鉴了此类模型在……方面取得的最新成功。
在 ViViT 架构中,视频处理使用 Transformer 架构完成,无需使用 CNN 进行初始特征提取。用于处理视频和图像的 Vision Transformers (ViTs) 中的编码器-解码器结构相似,但由于输入数据(图像与视频)的性质不同,该架构的实现和应用存在差异。例如,VTN 中的编码器结构必须同时考虑时间和空间维度。视频的编码器-解码器结构(如 ViViT — Video Vision Transformers)通常涉及调整以同时模拟时间和空间信息。由于视频是动态的并且包含时间信息,因此这些模型通常使用多个帧作为输入。视频是帧序列(静态图像),它们一个接一个地快速显示以显示运动和随时间的变化,这些特征被转换为低维向量(嵌入)。这些向量包含来自每个帧的关键信息,模型需要这些信息来理解帧之间的时间和空间关系。
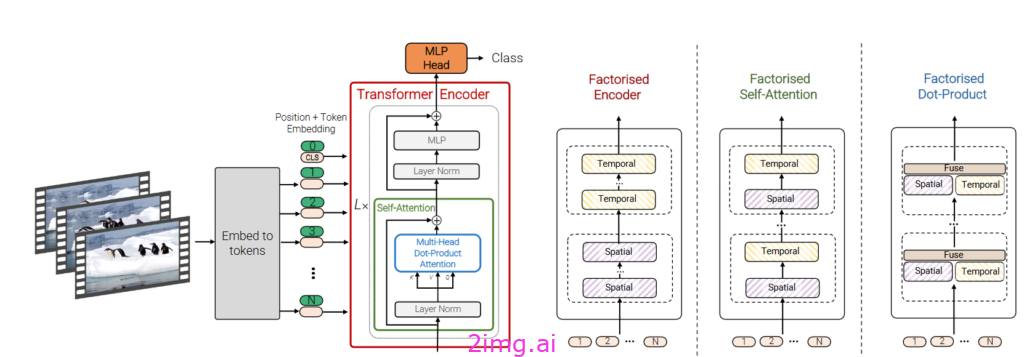
这张图片取自原始论文,清楚地说明了 ViViT 的功能。在左侧,我们可以看到编码器块架构的清晰描述,其中输入标记是图像帧。在右侧,您可以观察到不同注意力模式随时间和空间的相应分解和分析。来源
此外,他们采用自注意力机制来提取特征并理解图像中的块或视频中的帧之间的关系。对于视频,除了关注块之间的空间关系之外,对帧之间的时间关系进行建模也是必不可少的。这通常是通过使用帧序列上的注意机制来实现的。该机制使模型能够考虑帧之间的时间和空间关系。在每个阶段,自注意力都会计算一个权重矩阵,指示每个帧与其他帧的关系。这个矩阵有助于模型从整个视频序列中提取重要信息。由于额外的时间维度,与图像相比,这通常需要更多的计算复杂度和资源。
ViViT 解码器部分的处理步骤通常包括与其他 Transformer 模型中的解码器类似的步骤。首先,将输入 token 转换为特征向量 (Embedding)。对于视频,这些 token 可以表示从帧块中提取的特征。将时空信息添加到特征向量是位置编码步骤,使模型能够理解每个 token 在序列中的位置。
ViViT 中 Masked MHA 的关键步骤
ViViT 模型中生成视频的过程类似于生成文本序列,但不同之处在于每个步骤都会产生一个视频帧作为输出。解码器部分通常用于生成输出,如分类标签、视频描述或类似任务。但是,对于从头开始创建视频帧(视频生成),其他架构(如视频 GAN或视频自动编码器)更常用。在这种情况下,解码器中的多头注意力 (MMHA) 起着重要作用。
在 ViViT 模型中,解码器架构的初始阶段,有一个 MMHA 层,用于检查先前的输出标记并模拟它们之间的关系。在此阶段使用掩码,以便模型只能考虑先前的标记而不考虑未来的标记。这在视频生成中至关重要,因为每个帧都需要基于先前的帧生成。使用掩码 MHA 可确保模型仅考虑先前的帧,而无法访问未来的信息,这对于保持视频生成的顺序完整性非常重要。
接下来,还有另一个 MHA 层,用于检查编码器的输出。此层对编码器部分从视频中提取的特征与解码器部分中的当前标记之间的关系进行建模。此层不使用掩码,因为模型需要考虑所有编码器标记。编码器-解码器注意阶段的输出被输入到前馈神经网络 (FFN) 中,该网络包含多个密集层。后续步骤遵循 Transformer 架构,与编码器部分一样,解码器也使用层规范化和残差连接。
ViViT 和其他视频 Transformer 模型中的解码器部分与 NLP 中的 Transformer 模型的运行方式类似,但它专门处理视频数据及其时空特征。在解码器中使用 Masked MHA 来阻止访问未来的 token 并保持顺序生成过程至关重要。
重要提示:ViTs 和 ViViTs 中的整体编码器-解码器结构和注意力机制相似。但是,由于需要在视频中建模时间信息,因此在实现和细节上存在差异。这些差异使模型能够有效地处理其输入数据类型,无论是图像还是视频。
视频GPT
2021年,Yusen Zhou等人在论文中提出了VideoGPT,这是一种基于Transformer的模型,其结构与GPT模型类似。
VideoGPT:使用 VQ-VAE 和 Transformers 生成视频
我们提出了 VideoGPT:一种概念上简单的架构,用于将基于可能性的生成模型扩展到自然……
该模型旨在根据输入文本或视频帧序列创建短视频。如果输入是文本,编码器会将其转换为嵌入向量。如果输入是初始视频帧,则会对其进行类似处理。该模型将这些输入视为序列数据。视频帧在进入模型之前经过预处理并转换为适当的序列。
使用 Transformer 架构,该模型通过解码器生成与输入文本或帧对齐的新视频帧。在解码器部分,它使用编码器生成的数值表示来预测下一个视频帧。此过程涉及逐帧视频生成,根据先前的输入和对可用信息的关注准确预测下一帧,包括预测未来帧和完成视频序列。

在图片的左侧,你可以看到一种称为 VQ-VAE(矢量量化变分自动编码器)的自动编码器模型,它将输入数据(视频)编码到低维潜在空间中,然后将该潜在空间重建回输入数据。此阶段类似于原始的 VQ-VAE 训练方法。目标是让模型将视频数据压缩到潜在空间中,同时将质量损失降至最低。右侧是潜在空间中自回归 Transformer 的第二个训练阶段,其中 VQ-VAE 生成的潜在序列用作自回归 Transformer 模型的训练数据。来源
解码器生成的视频帧随后被连接起来形成完整的视频。在 VideoGPT 模型中,解码器根据从编码器收到的信息预测和生成未来帧来生成视频序列,从而生成最终视频。然而,VideoGPT 和类似模型的使用仍处于研发阶段。虽然这项技术在各种应用(如自动视频内容生成、动画创作、广告等)中具有巨大潜力,但由于技术复杂性和对高计算资源的需求,它尚未在商业上得到广泛采用。
Transformer 在图像和视频方面面临的主要挑战
值得注意的是,使用 Transformers 执行与图像和视频相关的任务会带来独特的挑战。图像和视频包含复杂的空间信息。虽然 Transformers 可以借助其注意力机制专注于序列的重要部分,但这可能不适合对图像和视频中常见的长距离依赖关系进行建模。然而,较新的 Transformer 架构(例如 Vision Transformer 和 Swin Transformer)专为图像和视频任务而设计,它们采用了更适合对空间依赖关系进行建模的新注意力机制。
其中一个主要挑战是在大型图像和视频数据集上训练 Transformers,这在计算上非常昂贵。Transformers 具有大量参数,需要大量内存和计算能力进行处理。强化学习可以更有效地训练 Transformers,因为它们会收到关于其性能的正面或负面反馈,而不是在标记数据集上进行训练。这使它们能够学习有效的模式,而无需大量标记数据。此外,多任务学习可用于同时训练 Transformers 以执行多个任务,从而使它们能够跨任务共享知识并提高每个任务的性能。
用于图像和视频任务的高质量数据集通常稀缺且昂贵。这使得在这些任务上训练 Transformers 变得具有挑战性,因为它们需要大量数据来学习有效的模式。这些只是正在开发的几个有希望的解决方案,用于解决使用 Transformers 进行图像和视频任务的挑战。随着研究的进步,Transformers 在这些任务中的表现可能会有显著的提高。
结论
在本文中,我们讨论了从原始 Transformer 论文中衍生的各种 Transformer 模型及其在图像和视频任务中的应用。它们的核心思想非常相似,主要区别在于其架构中使用的数据类型。还探讨了 GAN 架构,它是在 Transformer 之前开发的,并被广泛使用。然而,随着 Transformer 的出现,GAN 架构也发生了变化。这两者结合在一起,导致了 ViTGAN 和 TransGAN 架构的诞生。
如今,Transformer 无处不在,各大公司都在用这种架构塑造我们的新世界。随着我们不断前行,这种架构的不断完善让我们更接近 AGI(通用人工智能)。特别是在计算机视觉领域,机器看得越好,我们就越接近 AGI。在撰写本文时发布的 GPT-4o 推出后,通往 AGI 的道路变得更加清晰。有了 GPT-4o,模型可以实时看到视频,立即分析它们,并回答有关它们的问题。谷歌的模型功能类似。
显然,不久之后将转向能够看得更多、更好的模型。从本质上讲,LLM(大型语言模型)正变得更加多模式化。控制权将掌握在那些能够增强机器视觉的人手中,这也可能让世界变得更加可怕,因为现实的界限将发生重大改变,越来越难以区分真实世界和人造世界。这一发展可能不可避免地将我们引向令人难忘的电影《黑客帝国》中提出的深刻问题:“什么是真实的?”
Paragoger衍生者AI训练营。发布者:稻草人,转载请注明出处:https://www.shxcj.com/archives/3550
![14-19 深入浅出帮你理解 [Transformer是你所需要的]](https://www.shxcj.com/wp-content/uploads/2024/07/image-14-480x300.png)






