
语言模型的最新突破是使用神经网络架构来表示文本。自 2018 年以来,大型语言模型的发展非常迅速,这一点毋庸置疑。
一切始于 2013 年的 Word2Vec 和 N-Grams,它们是语言建模领域的最新成果。RNN 和 LSTM 随后于 2014 年问世。随后,注意力机制取得了突破。
正是注意力机制的突破催生了大型预训练模型和 Transformer。
BERT 和 GPT 均基于 Transformer 架构。本文对这两个模型进行了比较和对比。
故事从词嵌入开始。
什么是词嵌入?
词嵌入是自然语言处理 (NLP) 中的一种技术,其中单词在连续向量空间中表示为向量。这些向量捕获语义含义,使具有相似含义的单词具有相似的表示。
例如,在词嵌入模型中,“国王”和“女王”这两个词的向量会很接近,反映出它们相关的含义。同样,“汽车”和“卡车”这两个词的向量也可能非常接近。“猫”和“狗”也是如此。
但是,您不会期望“汽车”和“狗”具有非常接近的向量。
词嵌入的一个著名例子是Word2Vec。
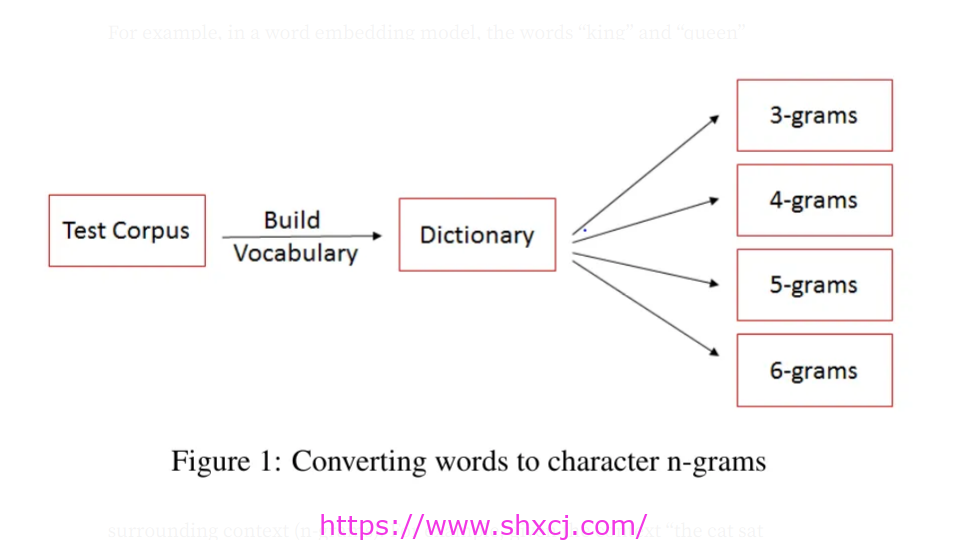

图片来源:Mahajan、Patil 和 Sankar。2013 年
Word2Vec 是一种神经网络模型,它通过在单词的上下文窗口上进行训练来使用 n-gram。主要有两种方法:
连续词袋 (CBOW):根据目标词周围的上下文 (n-gram) 预测该词。例如,给定上下文“the cat sat on the”,CBOW 会预测单词“mat”。
Skip-gram:根据目标单词预测周围的单词。例如,给定单词“cat”,Skip-gram 会预测上下文单词“the”、“sat”、“on”和“the”。
这两种方法都有助于捕捉语义关系;相似的词具有相似的向量表示。这通过提供有意义的词嵌入来促进各种 NLP 任务。
Word2Vec 使用来自大型语料库的上下文来学习词语联想。这种方法通过根据词语的使用模式提供丰富的词语表示,实现了各种 NLP 任务,例如情绪分析和机器翻译。
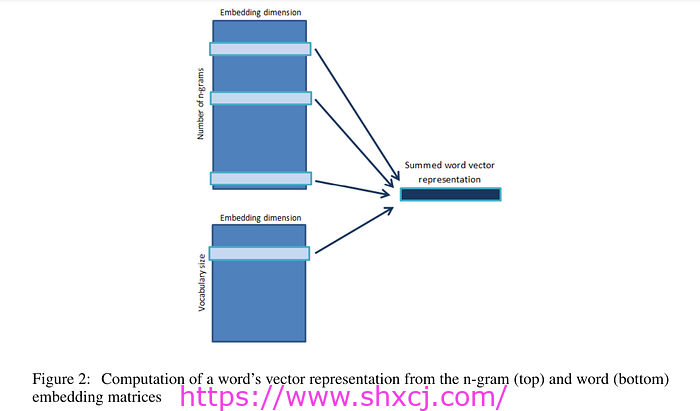
图片来源:Mahajan、Patil 和 Sankar。2013 年使用 n-gram 的 Word2Vec 由 Mahajan、Patil 和 Sankar 在他们 2013 年的论文《使用字符 N-Grams 的 Word2Vec》中提出。
循环神经网络 (RNN) 是一种专为顺序数据设计的神经网络。它们按顺序处理输入,保持隐藏状态以捕获有关先前输入的信息,使其适合于时间序列预测和自然语言处理等任务。RNN 类型的网络可以追溯到 1925 年,当时Ising 模型用于模拟磁相互作用,类似于 RNN 用于序列学习的状态转换。
长短期记忆 (LSTM) 网络是一种特殊类型的 RNN,旨在克服标准 RNN 的局限性,尤其是消失梯度问题。
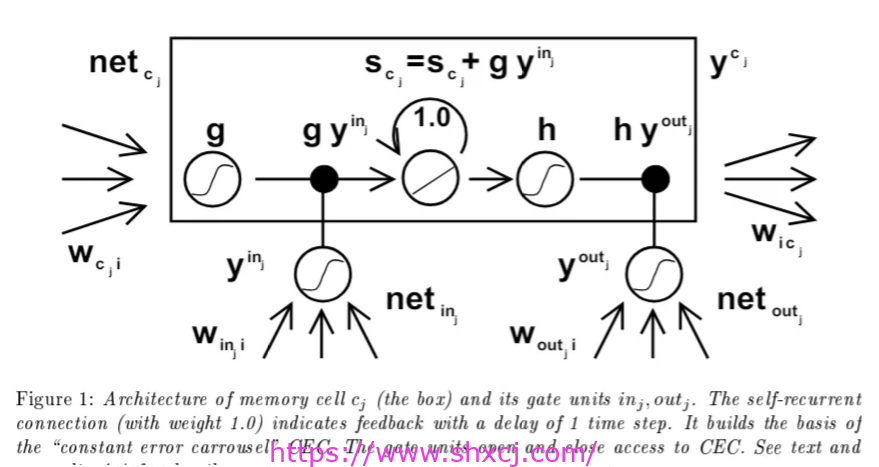
图片来源:Hochreiter 和 Schmidhuber。 1997
LSTM 使用门(输入门、输出门和遗忘门)来调节信息流,使其能够保持长期依赖性并记住长序列中的重要信息。LSTM 由 Hochreiter 和 Schmidhuber 于 1997 年发明,并在他们题为“长短期记忆”的论文中提出。
以下是上面显示的 LSTM 单元架构的实现:
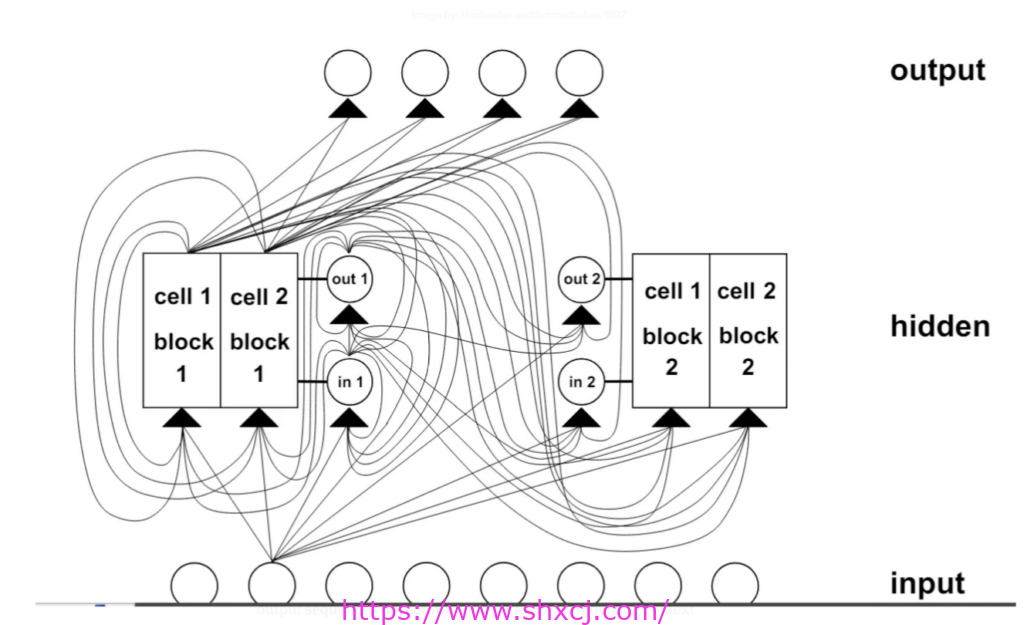
图片来源:Hochreiter 和 Schmidhuber。 1997
Word2Vec、RNN 和 LSTM 的比较
目的: Word2Vec 主要是一种词嵌入技术,根据单词的上下文为其生成密集的向量表示。另一方面,RNN 和 LSTM 用于建模和预测序列。
架构: Word2Vec 采用浅层两层神经网络,而 RNN 和 LSTM 则采用更复杂、更深层的架构,专门用于处理顺序数据。(架构的隐藏层越多,网络越深。)
输出: Word2Vec 输出固定大小的单词向量。RNN 和 LSTM 输出向量序列,适用于需要随时间推移理解上下文的任务,如语言建模和翻译。
内存处理:与标准 RNN 和 Word2Vec 不同,LSTM 能够通过其门控机制有效地管理长期依赖关系,从而使其在执行复杂序列任务时更加强大。
Word2Vec 是(曾经是)创建词嵌入的理想选择,而 RNN 和 LSTM在涉及序列数据和长期依赖关系的任务方面表现出色。
什么是注意力机制?
注意力机制是神经网络的一个关键组成部分,尤其是在 transformer 和大型预训练语言模型中,它允许模型在生成输出时专注于输入序列的特定部分。它为输入中的不同单词或标记分配不同的权重,使模型能够优先处理重要信息并更有效地处理长距离依赖关系。
注意力机制的论文题为“Attention Is All You Need”,由 Ashish Vaswani 等人撰写。
变形金刚的进化过程如下。
标记化是注意力机制的一个非常重要的部分。
注意力机制与 Transformer 的关系
Transformer 使用自注意力机制来并行处理输入序列,而不是像 RNN 那样按顺序处理。这使得 Transformer 能够同时捕获序列中所有 token 之间的上下文关系,从而改善对长期依赖关系的处理并缩短训练时间。
自注意力机制有助于识别输入序列中每个标记与每个其他标记的相关性,从而增强模型理解上下文的能力。
注意力机制与大型预训练语言模型的关系
大型预训练语言模型,例如 BERT 和 GPT,建立在 Transformer 架构上,并利用注意力机制从大量文本数据中学习上下文嵌入。
这些模型利用多层自注意力来捕捉数据中复杂的模式和依赖关系,使它们能够对特定任务进行微调后以高精度执行广泛的 NLP 任务。
注意力机制是 transformer 和大型预训练语言模型成功的基础,使它们能够有效地处理复杂的语言理解和生成任务。
这种对理解上下文的关注与YData Fabric (专为数据科学团队设计的数据质量平台)类似,后者也强调干净且结构良好的数据对于构建高性能 AI 模型的重要性。正如注意力机制可以帮助语言模型理解语言的细微差别一样,良好的数据质量对于 AI 模型从训练数据中学习准确且可推广的模式至关重要。
那么,BERT 和 GPT 是什么
首先,这两个模型都是基于 transformer 架构的。这两个模型都是大型预训练语言模型。
BERT
BERT 代表 Transformers 的双向编码器表示。它是 Google 开发的预训练语言模型,于 2018 年 10 月推出。它基于 Transformer 架构。(如果您读到这里,您就会知道我做了什么。)
Devlin、Ming-Wei、Lee 和 Toutanova 的论文摘要题为“BERT:用于语言理解的深度双向 Transformer 的预训练”,内容如下:
“我们引入了一种新的语言表示模型,称为 BERT,代表来自 Transformers 的双向编码器表示。与最近的语言表示模型不同,BERT 旨在通过联合调节所有层的左右上下文来预训练来自未标记文本的深度双向表示。因此,只需一个额外的输出层即可对预训练的 BERT 模型进行微调,以创建用于各种任务(例如问答和语言推理)的最先进的模型,而无需对特定于任务的架构进行大量修改。”(Devlin、Ming-Wei、Lee 和 Toutanova,2018 年)。
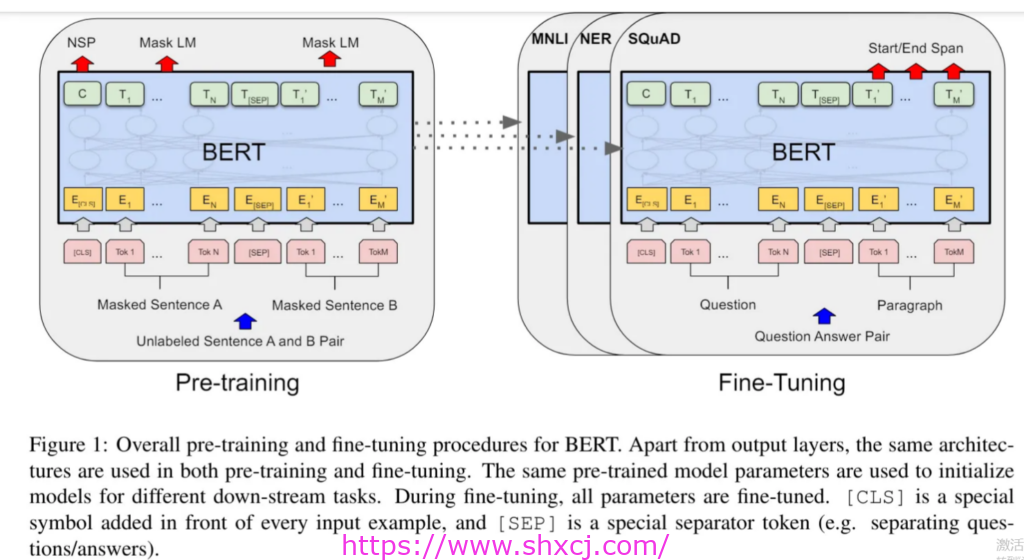
图片来源:Devlin, Ming-Wei, Lee & Toutanova,2018 年
需要注意两点:(1)BERT 是双向的,也就是说它可以同时从左向右移动。(2)回答问题和语言推理是它的主要任务。
BERT 的一些应用包括ClinicalBERT 和 BioBERT。
GPT
GPT 代表生成式预训练 Transformer。它指的是 OpenAI 创建的大型语言模型 (LLM) 系列,以生成类似人类的文本的能力而闻名。GPT模型可以创建新的文本内容,如诗歌、代码、脚本、音乐作品等。它们经过预先训练,并在其核心架构中使用 Transformer 模型。
再说一遍,你看到我做了什么吗?
Radford、Narasimhan、Salimans 和 Sutskever 在发布 GPT 的论文《通过生成式预训练提高语言理解能力》中摘要道:
“自然语言理解包括多种多样的任务,例如文本蕴涵、问答、语义相似性评估和文档分类。尽管大量未标记的文本语料库非常丰富,但用于学习这些特定任务的标记数据却很少,这使得经过判别性训练的模型难以充分发挥作用。我们证明,通过在多样化的未标记文本语料库上对语言模型进行生成性预训练,然后对每个特定任务进行判别性微调,可以在这些任务上实现巨大收益。”(Radford、Narasimhan、Salimans 和 Sutskever,2016 年)。
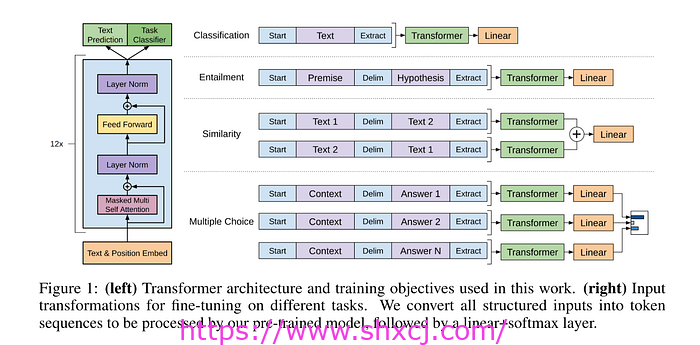
图片来源:Radford、Narasimhan、Salimans 和 Sutskever,2016 年
需要注意两点:(1)GPT 主要具有生成性。(2)GPT 是单向的。
GPT 已经历了多次迭代,其中 GPT-4o是最新、最先进的。
BERT 和 GPT 之间的主要区别
首先,让我们注意一下BERT 和 GPT 之间的主要相似之处
- 两者都基于 Transformer 架构。
- 两者都是来自大量文本的预训练模型。
- 两者均针对各种功能进行了微调。
不同之处在于:

这就是 BERT 不是 GPT 的原因。
Paragoger衍生者AI训练营。发布者:稻草人,转载请注明出处:https://www.shxcj.com/archives/3263