
在理想世界中,我们从一开始就会将人工智能融入软件系统的设计中。但在现实世界中,这并不总是可行的。许多企业拥有运行多年的大型复杂系统,对其进行重大更改既有风险又昂贵。
我们的供应链管理公司AI集成设计
本文介绍如何将 AI 的功能添加到现有应用程序中,即使这些应用程序很难或无法更改。我们将探讨为什么这是一个常见的挑战、AI 集成的好处,以及最重要的是,实现这一目标的实用方法。
这篇文章是关于什么的?
在快节奏的商业世界中,公司通常会拥有经过长期尝试和测试的完善系统和流程。这些现有系统深深植根于公司的运营中,改变它们可能是一项艰巨的任务,可能会扰乱整个工作流程。然而,随着人工智能 (AI) 技术的快速发展,企业渴望利用其能力来增强运营并获得竞争优势。
本文旨在让您相信,即使无法改变现有系统,您仍然可以将 AI 无缝集成到您的业务流程中。我们将探索真实场景,并展示一家公司(尽管是模拟的)如何在不彻底改造现有基础设施的情况下成功整合 AI,从而最大限度地减少中断并最大限度地发挥 AI 的优势。
为什么要读这篇文章?
学习一项非常重要的技能,即如何将人工智能无缝集成到现有生态系统中,而无需对现有稳定流程进行任何更改
通过阅读本文,您将获得宝贵的见解,并学习将 AI 集成到现有业务生态系统中而无需对稳定的工作流程进行重大更改的关键技能。随着越来越多的公司认识到 AI 的价值,同时也意识到彻底改造现有系统的挑战,这项技能变得越来越重要。
我将为您提供实际示例、分步指南和最佳实践,以帮助您应对 AI 集成的复杂性。无论您是企业主、决策者还是技术专业人员,本文都将为您提供必要的知识和工具,以充分发挥 AI 的潜力,同时保持现有系统的完整性。
我们的业务用例是什么
我们有一个模拟的供应链管理公司,它有多个部门,每个部门都公开自己的 REST API,要得到查询答案,它必须经过这些部门、它们的 API 和数据库调用。我们将引入 AI,但保持所有现有流程完好无损。
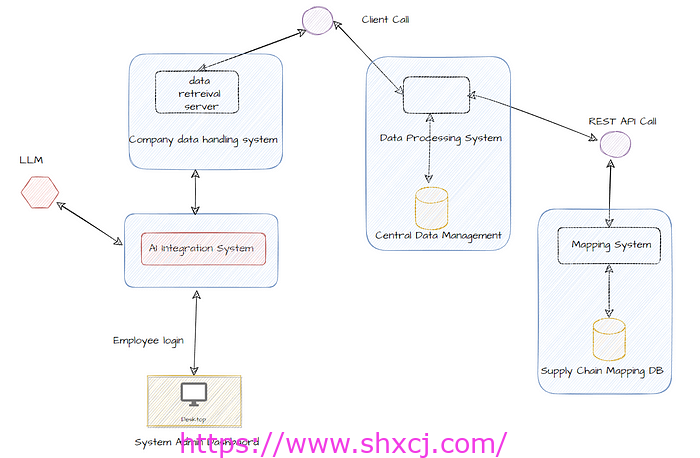

我们的供应链管理公司AI集成设计
该公司的核心部门是“数据处理系统”,负责处理数据管理和处理的核心操作。它通过不同的接口与其他各个部门进行交互。“客户呼叫”组件代表客户请求或查询进入系统的入口点。然后,这些请求被传递到“数据处理系统”进行处理。该系统还与“中央数据管理”组件进行通信,后者是管理和存储与供应链运营相关的数据的集中存储库。
“公司数据处理系统”是另一个重要部门,由“数据检索服务器”组成。该服务器存储和管理公司的内部数据,包括有关库存、订单、物流和其他运营细节的信息。“人工智能集成系统”组件专门用于将人工智能功能集成到现有系统中。它与“公司数据处理系统”交互,并间接访问“中央数据管理”部门,使其能够利用来自多个来源的数据进行人工智能决策或自动化。
“地图系统”部门连接到“供应链地图数据库”(数据库),该数据库存储地理数据、路由信息以及与供应链地图和物流相关的其他详细信息。“系统管理仪表板”允许授权员工登录并访问管理功能或监控系统性能。该仪表板与“AI 集成系统”交互,以提供见解、报告或对 AI 功能的控制。
最后,“REST API 调用”组件公开一个 RESTful API,允许外部系统或应用程序与其交互并可能利用其功能或数据。
我们先建立我们供应链管理公司的IT系统
仪表板和人工智能集成系统
第一部分:get_supply_chain_data功能的定义
def get_supply_chain_data ( query ):
"""通过调用 Flask API 获取给定查询的供应链数据。"""
url = f'http://127.0.0.1:5000/supply-chain-data?query= {query} '
response = request.get(url)
if response.status_code == 200 :
return json.dumps(response.json())
else :
return json.dumps({ "error" : "API 请求失败" , "status_code" : response.status_code})
- 此函数通过向 Flask API 端点发出 HTTP GET 请求来检索供应链数据。
- 它接受一个
query参数,代表与供应链活动相关的查询。 - 该 URL 是使用提供的查询参数构建的。
- 该函数检查响应状态代码。如果是 200(OK),则返回响应的 JSON 表示形式。否则,它将返回包含错误消息和状态代码的 JSON 对象。
第二部分:run_conversation功能的定义
def run_conversation (user_prompt) :
messages = [
{
"role" : "system" ,
"content" : "您是一个调用LLM的函数,使用从get_supply_chain_data函数中提取的数据来回答与供应链管理相关的问题。 在您的回复中包含相关的供应链活动和数据。"
},
{
"role" : "user" ,
"content" : user_prompt,
}
]
tools = [
{
"type" : "function" ,
"function" : {
"name" : "get_supply_chain_data" ,
"description" : "获取给定查询的供应链数据" ,
"parameters" : {
"type" : "object" ,
"properties" : {
"query" : {
"type" : "string" ,
"description" : "与供应链活动相关的查询" ,
}
},
"required" : [ "query" ],
},
},
}
]
...
- 此功能管理用户与AI模型之间的对话。
- 它准备消息,包括一条来自系统的消息和一条来自用户并包含其提示的消息。
- 它准备了 AI 模型在对话过程中可以使用的工具。在本例中,它包含一个名为“get_supply_chain_data”的函数及其描述和参数。
第 3 部分:Gradio 界面设置
background_path = os.path.join(os.getcwd(), 'images', 'background.png').replace("\\", "/")
with gr.Blocks(css=f"""
...CSS Styling...
""") as demo:
...
- 这部分设置了 Gradio 界面以供用户交互。
- 它构建了界面中使用的背景图像的路径。
- 界面布局和样式使用上下文管理器中的 CSS 定义
gr.Blocks。
第 4 部分:Gradio 界面组件
gr.Markdown(f"""
<div class="header">
<h1>Supply Chain Management Company</h1>
<p>Your AI-powered supply chain management</p>
</div>
""")
gr.Markdown(f"""
<img src="{background_path}" class="background-image">
""")
with gr.Row():
...
- 这些行定义了 Gradio 界面的组件,包括带有标题和描述的标题头以及图像。
- 标题提供有关供应链管理系统的信息。
- 该图像作为界面的背景。
第 5 部分:设置用户输入和输出组件
with gr.Row():
with gr.Column(scale=1):
user_input = gr.Textbox(
label="Enter your query",
placeholder="Ask a question about supply chain management...",
lines=3,
elem_id="user-input"
)
submit_button = gr.Button("Submit", variant="primary", elem_classes="submit-button")
with gr.Column(scale=2):
output_text = gr.Textbox(
label="Response",
lines=10,
elem_id="output-text"
)
- 此部分在行列布局内设置用户输入(文本框和提交按钮)和输出(文本框)的组件。
- 用户可以在文本框中输入与供应链管理相关的查询。
- 提交查询后,AI 模型的响应将显示在输出文本框中。
第六部分:更新供应链统计数据
stats_text = gr.Text(value="Loading...", label="Supply Chain Stats", interactive=False, elem_classes="stats")
submit_button.click(
gradio_interface,
inputs=user_input,
outputs=output_text,
)
threading.Thread(target=update_stats_text, daemon=True).start()
- 本节初始化一个文本组件来显示供应链统计数据。
- 它为提交按钮设置了一个单击事件处理程序。单击按钮时,
gradio_interface将使用用户输入调用该函数,并将输出显示在输出文本框中。 - 另外,它还启动一个单独的线程来不断更新界面上显示的供应链统计数据。
第 7 部分:启动 Gradio 界面
demo.launch()
- 最后,该系列推出了 Gradio 界面,允许用户与人工智能驱动的供应链管理系统进行交互。
公司数据处理系统
第 1 部分:导入库并设置日志记录
import json
import os
import logging
import requests
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s - %(message)s')
logger = logging.getLogger(__name__)
- 我导入了必要的库,例如
json、、和。osloggingrequests - 我设置了日志记录来跟踪程序执行期间的信息、警告和错误。
第 2 部分:类别SupplyChainDataRetriever定义
class SupplyChainDataRetriever:
def __init__(self, database_folder, mapping_api_url='http://localhost:5001/mapping'):
self.database_folder = database_folder
self.query_mapping = self.fetch_query_mapping(mapping_api_url)
- 我定义了一个名为“
SupplyChainDataRetriever根据用户查询检索供应链数据”的类。 - 该类使用
database_folder路径和可选项进行初始化mapping_api_url,以获取查询映射。
第 3 部分:获取查询映射
def fetch_query_mapping ( self,mapping_api_url ):
try:
response = request.get(mapping_api_url)
response.raise_for_status()
return response.json()
except request.exceptions.RequestException as e:
print ( f"获取 query_mapping 时出错:{e} " )
return {}
logger.info( f"使用数据库文件夹创建的 SupplyChainDataRetriever 实例:{database_folder} " )
- 此方法从指定的 API 端点获取查询映射。
- 它向发送 HTTP GET 请求
mapping_api_url并处理任何异常。 - 如果成功,它将返回包含查询映射的 JSON 响应。
第 4 部分:检索供应链数据
def get_supply_chain_data(self, query):
query = query.lower()
logger.info(f"Received query: {query}")
for activity, filename in self.query_mapping.items():
...
- 此方法根据用户的查询检索供应链数据。
- 它首先将查询转换为小写以进行不区分大小写的匹配,并记录收到的查询。
- 然后,它遍历查询映射字典以找到查询和已知供应链活动之间的匹配。
第 5 部分:匹配查询和活动
activity_words = set(activity.split(' '))
query_words = set(query.split())
if activity_words & query_words:
...
- 在这里,我将活动和查询分成几组词。
- 我使用集合交集检查活动和查询之间的共同词汇
第 6 部分:从文件读取数据
file_path = os . path .join( self .database_folder, filename)
if os . path .exists(file_path):
with open (file_path, 'r' ) as file:
data = json. load (file)
return data
else :
logger. error (f "未找到文件:{file_path}" )
- 如果找到匹配的活动,我会根据
database_folder和文件名构建文件路径。 - 我检查该文件是否存在,如果存在,我就从文件中读取 JSON 数据并返回它。
- 如果该文件不存在,我会记录一条错误消息。
第 7 部分:处理无匹配活动
error_message = { “error”:“未找到给定查询的数据” }
logger.warning(f “未找到查询的数据:{query}”)
return error_message
- 如果查询未找到匹配的活动,我会记录警告并返回错误消息。
我以这种方式设计代码,以创建一个强大而高效的系统,用于根据用户查询检索供应链数据,同时确保正确的错误处理和记录以用于调试目的。
数据处理系统
第 1 部分:导入库并设置日志记录
from flask import Flask, request, jsonify
from data_retriever import SupplyChainDataRetriever
import logging
- 我导入了必要的库,例如 Flask,用于创建 Web 应用程序,以及日志记录,用于在程序执行期间跟踪信息、警告和错误。
第 2 部分:初始化 Flask 应用和数据检索器
app = Flask(__name__)
data_retriever = SupplyChainDataRetriever('数据库')
- 我创建了一个名为的 Flask 应用程序实例
app。 - 我实例化了一个
SupplyChainDataRetriever名为的对象,data_retriever用于根据用户查询检索供应链数据。我传递了名为的文件夹,'database'其中包含存储数据的 JSON 文件。
第 3 部分:用于供应链数据检索的 Flask Route
@app.route('/supply-chain-data', methods=['GET'])
def supply_chain():
"""
Flask route to handle supply chain data retrieval requests.
Query Parameters:
query (str): The user's query related to a supply chain activity.
Returns:
JSON response: The corresponding supply chain data or an error message.
"""
query = request.args.get('query', '')
if not query:
logger.error("Missing query parameter")
return jsonify({'error': 'Missing query'}), 400
logger.info(f"Received query: {query}")
data = data_retriever.get_supply_chain_data(query)
logger.info(f"Returning data: {data}")
return jsonify(data)
- 我定义了一个 Flask 路由
/supply-chain-data来处理作为 HTTP GET 请求发送的供应链数据检索请求。 - 该路线需要一个名为的查询参数
'query',该参数代表用户与供应链活动相关的查询。 - 如果缺少查询参数,我会记录错误并返回带有错误消息和状态代码 400(错误请求)的 JSON 响应。
- 我记录收到的查询,使用对象检索相应的供应链数据
data_retriever,并在将其作为 JSON 响应返回之前记录数据。
第 4 部分:启动 Flask 应用程序
if __name__ == '__main__':
logger.info("Starting Flask application")
app.run(debug=True)
- 如果直接执行脚本(不作为模块导入),我启动了 Flask 应用程序。
- 我记录了一条消息,表明 Flask 应用程序正在启动。
- 我启动了 Flask 开发服务器并启用了调试模式,以便在开发过程中轻松进行调试。
我以这种方式构建代码,使用 Flask 创建 Web 服务,该服务提供 API 端点,用于根据用户查询检索供应链数据。日志记录配置可确保记录相关信息以用于调试和监控目的。
地图系统
第一部分:类别MappingAPI定义
class MappingAPI:
def __init__(self, mapping_file_path=None):
self.app = Flask(__name__)
self.app.add_url_rule('/mapping', 'mapping', self.get_mapping, methods=['GET'])
if mapping_file_path is None:
mapping_file_path = os.path.join('center_dept_database', 'mapping.json')
self.mapping_file_path = mapping_file_path
- 我定义了一个名为的类,
MappingAPI用于创建一个基于 Flask 的 API,用于提供中心和部门之间的 JSON 映射。 - 在构造函数(
__init__)中,我实例化了一个 Flask 应用程序(app),并为端点添加了一个 URL 规则/mapping,该get_mapping规则在通过 HTTP GET 访问时调用该方法。 - 我将映射文件的默认路径设置为
'center_dept_database/mapping.json',但可以在初始化对象时提供不同的路径来覆盖它MappingAPI。
第 2 部分:检索地图数据
def get_mapping(self):
with open(self.mapping_file_path, 'r') as file:
mapping_data = json.load(file)
return jsonify(mapping_data)
- 该方法从指定的 JSON 文件中检索映射数据
mapping_file_path。 - 它打开文件,读取其内容,并将 JSON 数据加载到 Python 字典中(
mapping_data)。 - 然后,它使用 Flask 的函数将映射数据作为 JSON 响应返回
jsonify。
第 3 部分:启动 Flask 应用程序
def run(self, host='0.0.0.0', port=5001):
print(f"Starting MappingAPI on {host}:{port}")
self.app.run(host=host, port=port, debug=True)
if __name__ == '__main__':
mapping_api = MappingAPI()
mapping_api.run()
- 该
run方法启动 Flask 开发服务器。 - 它使用可选参数
host和port来指定服务器的主机名和端口号。默认情况下,它会监听'0.0.0.0'端口 5001 上的所有接口 ()。 - 当直接执行该脚本时(
if __name__ == '__main__':),它会创建一个实例MappingAPI并使用该方法来运行 Flask 应用程序run。 - 此外,它还会打印一条消息,指示 API 服务器已启动。
我设计此代码是为了创建一个简单的基于 Flask 的 API,用于提供中心和部门之间的 JSON 映射。该 API 提供了一个用于检索映射数据的单一端点,使其易于为各种应用程序部署和配置。
让我们设置
你应该看到类似下面的内容

让我们运行它
- 询问当前库存
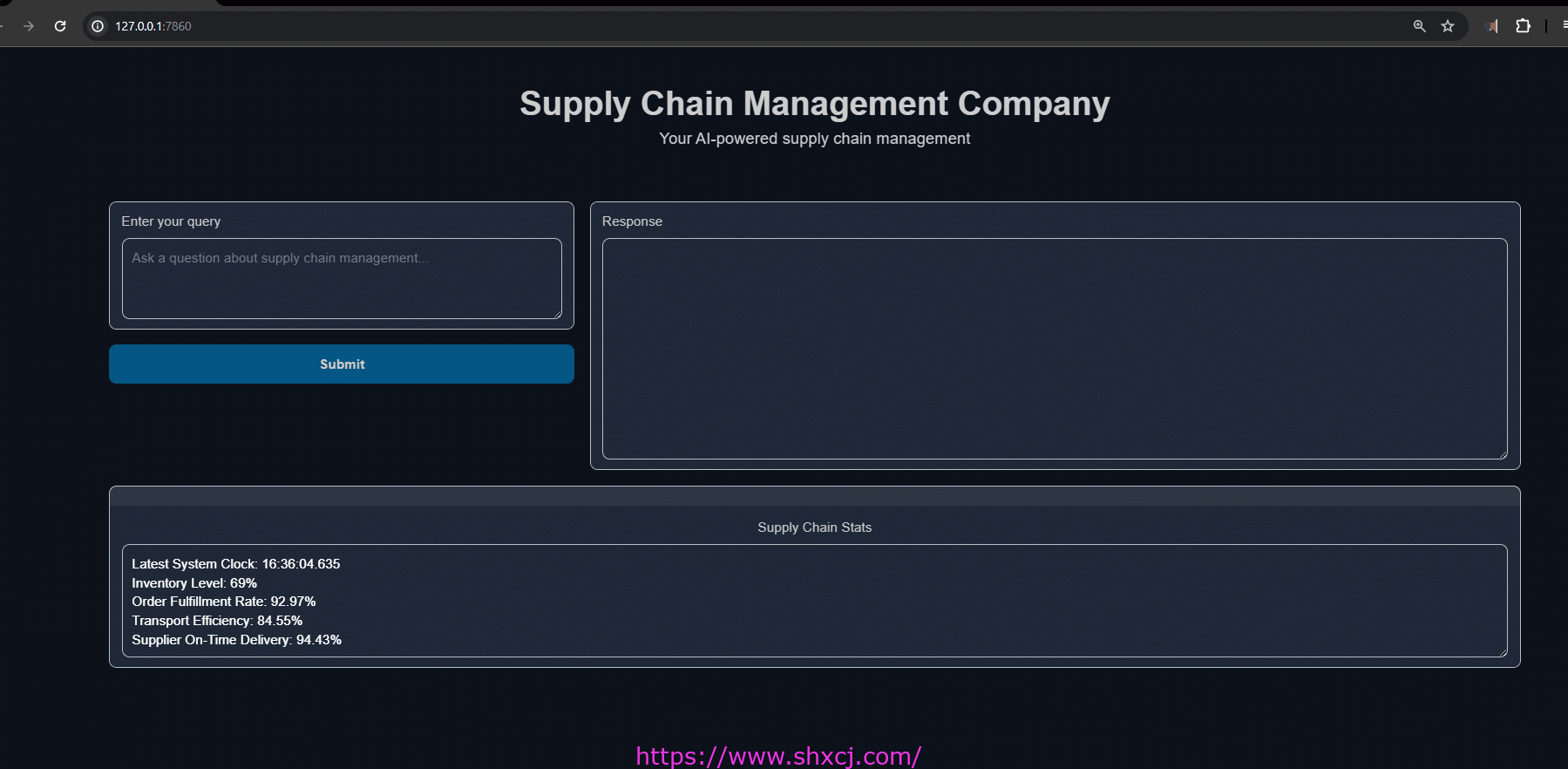
2. 询问具体的发货状态
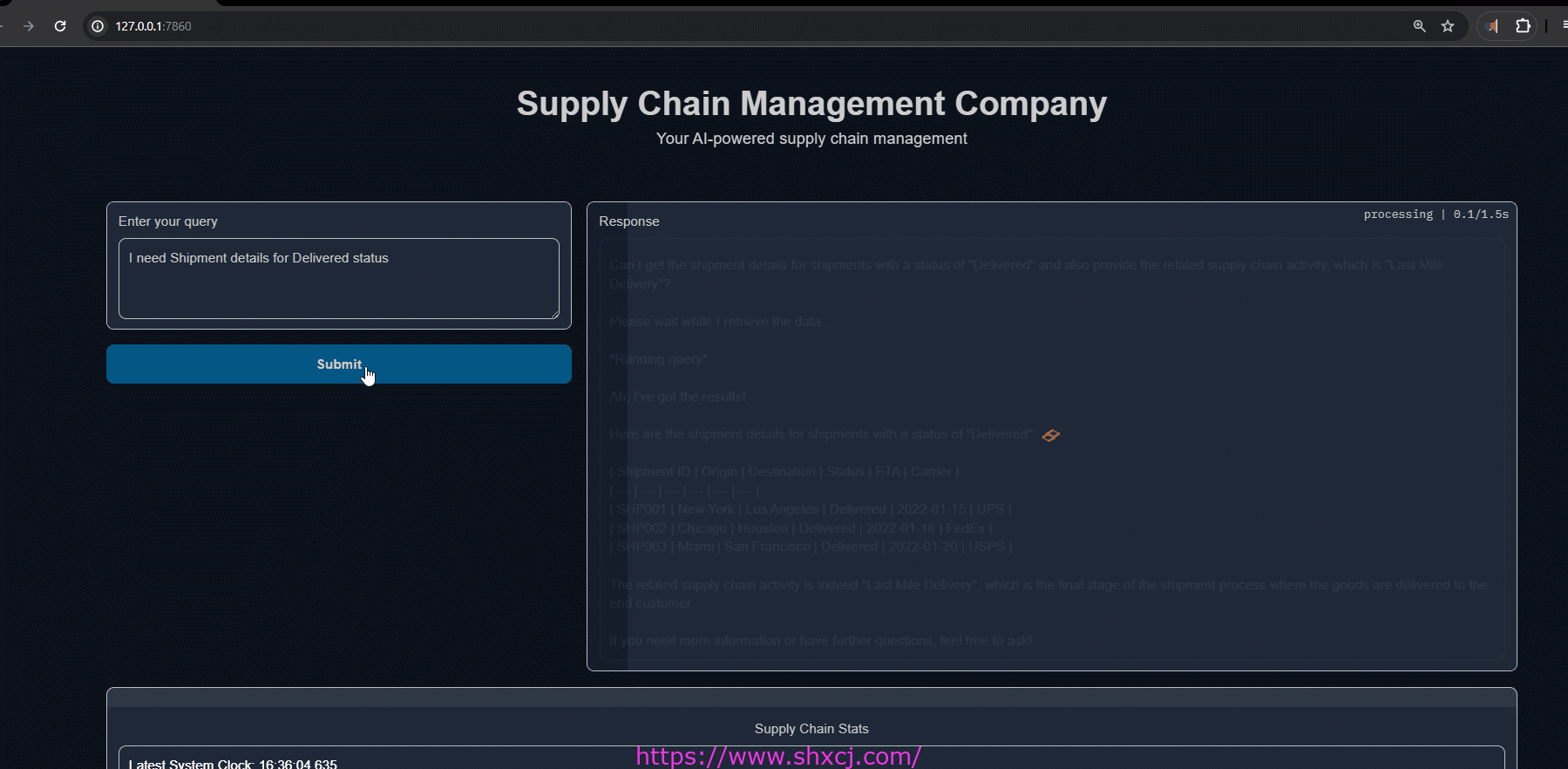
结束语
本文探讨的供应链管理项目是一个有力的例子,展示了如何将尖端的人工智能功能无缝集成到现有的业务系统中,而无需进行重大改造或中断。通过利用现代人工智能技术的灵活性和强大功能,我们能够增强模拟供应链管理系统的功能,同时保留其核心操作和工作流程。
在整个开发过程中,我们非常重视尽量减少对现有系统架构的影响。我们没有试图替换或修改现有组件,而是引入了“ AI 集成系统”,作为现有基础设施和 AI 功能之间的桥梁。这种方法使我们能够保持现有系统的完整性,同时利用 AI 的优势。
这种集成策略的主要优势之一是能够利用现有系统中已有的大量数据。通过 AI 模型访问和处理这些数据,我们能够对用户查询生成更明智、更智能的响应,提供针对特定供应链活动和场景的宝贵见解和建议。
展望未来,将 AI 无缝集成到现有商业生态系统中的重要性只会继续增长。随着技术进步的快速发展以及对智能自动化和决策支持的需求不断增长,采用这种方法的组织将能够更好地利用 AI 带来的机遇,同时最大限度地减少对其运营的干扰。
我希望通过这个模拟现实世界的例子,您能够更深入地了解人工智能集成的潜力以及可以采用的各种策略和最佳实践,以实现成功实施。通过采用这种方法,企业可以释放人工智能的变革力量,同时保留其现有系统中嵌入的投资和机构知识。
RA/SD 衍生者AI训练营。发布者:稻草人,转载请注明出处:https://www.shxcj.com/archives/3116