


推理过程是使用大型语言模型时大幅增加金钱和时间成本的因素之一。对于较长的输入,此问题会显著增加。下面,您可以看到模型性能与推理时间之间的关系。
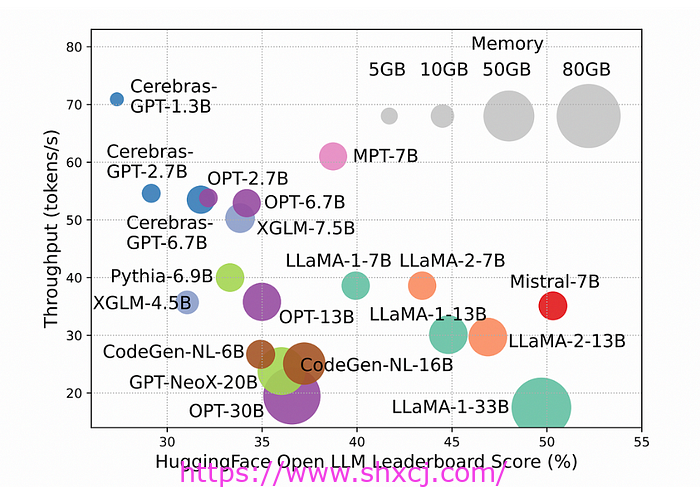
性能得分与推理吞吐量
每秒生成更多 token 的快速模型在 Open LLM 排行榜上的得分往往较低。扩大模型规模可以提高性能,但代价是降低推理吞吐量。这使得它们很难在实际应用中部署 。
提高 LLM 的速度并减少资源需求将使个人或小型组织能够更广泛地使用它们。
为了提高 LLM 效率,提出了不同的解决方案;一些解决方案侧重于模型架构或系统。但是,ChatGPT 或 Claude 等专有模型只能通过 API 访问,因此我们无法更改其内部算法。
我们将讨论一种简单且廉价的方法,该方法仅依赖于改变给予模型的输入——即时压缩Prompt Compression。
首先,让我们来解释一下 LLM 如何理解语言。理解自然语言文本的第一步是将其拆分成多个部分。这个过程称为标记化。标记可以是整个单词、音节或当前语音中经常使用的字符序列。

根据经验,标记的数量比单词的数量高 33%。因此,1000 个单词对应大约 1333 个标记。
让我们具体看看 gpt-3.5-turbo 模型的 OpenAI 定价,因为这是我们以后将使用的模型。

我们可以看到,推理过程对于输入标记(对应于发送给模型的提示)和输出标记(模型生成的文本)都有成本。
输入 token 消耗资源最多的应用之一是检索增强生成。输入甚至可以达到数千个 token。
在 RAG 中,用户查询被发送到矢量数据库,其中检索最相似的信息并与查询一起发送到 LLM。在矢量数据库中,我们可以添加模型在初始训练期间未看到的个人文档。
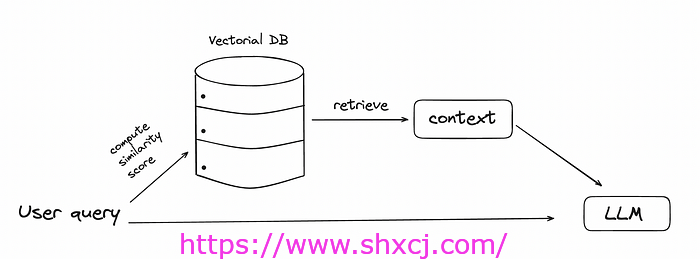
根据从数据库中检索到的文本块数量,发送到 LLM 的标记数量可能很大。
Prompt Compression 即时压缩
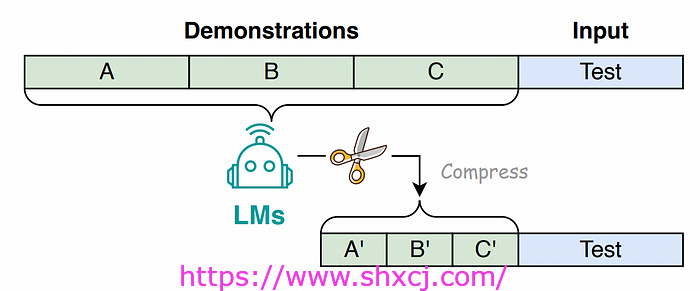
提示压缩可以缩短原始提示,同时保留最重要的信息。它还可以加快语言模型处理输入的速度,以帮助其快速生成准确的答案。
这种技术利用了这样一个事实:语言中经常包含不必要的重复。研究表明,英语在段落或章节长度的文本中有很多冗余——大约 75% 。
这意味着大多数单词都可以根据上下文中前面的单词来预测。
AutoCompressors
我们将要讨论的第一个压缩方法是 AutoCompressors。它的工作原理是将长文本汇总为短向量表示(称为摘要向量)。然后,这些压缩的摘要向量充当模型的软提示 。
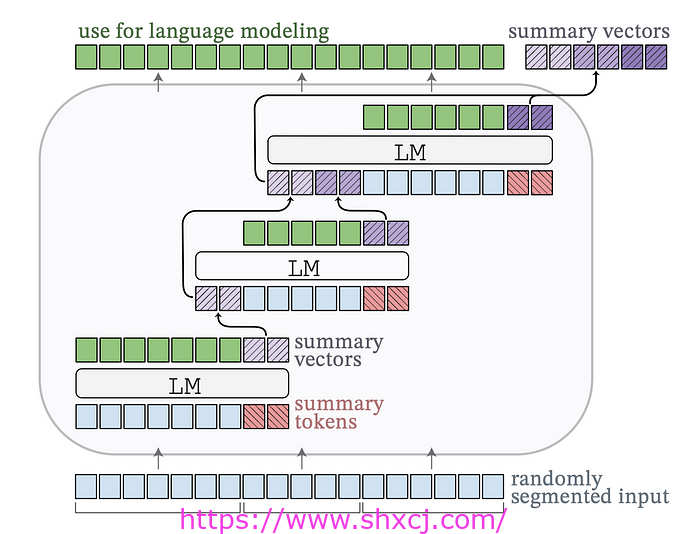
在软提示期间,预先训练的模型保持冻结状态,并针对每个特定任务在输入文本的开头添加少量可训练的标记。这些标记不是固定的,而是通过训练学习的。
它们在整个模型的背景下进行端到端优化,以最适合特定任务。
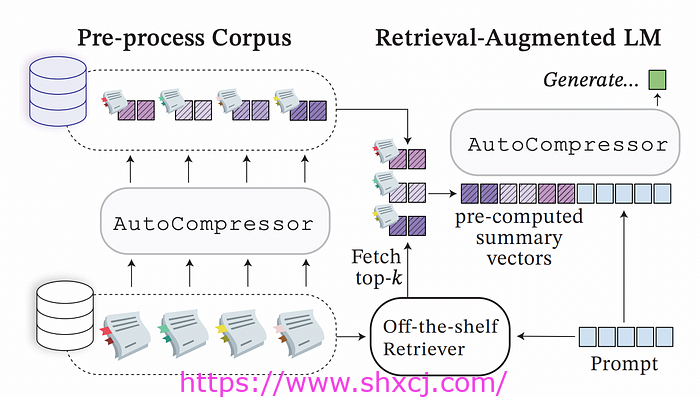
对于 RAG,可以对索引文档进行预处理,以便将其转换为摘要向量。在检索阶段,检索到的块被融合并发送到 LLM。
融合过程意味着它们的矢量表示被端到端连接起来,形成一个更长的矢量。这些矢量基本上是堆叠在一起的。
为了创建这些摘要向量,您可以选择自己训练压缩器,也可以使用预先训练的压缩器。
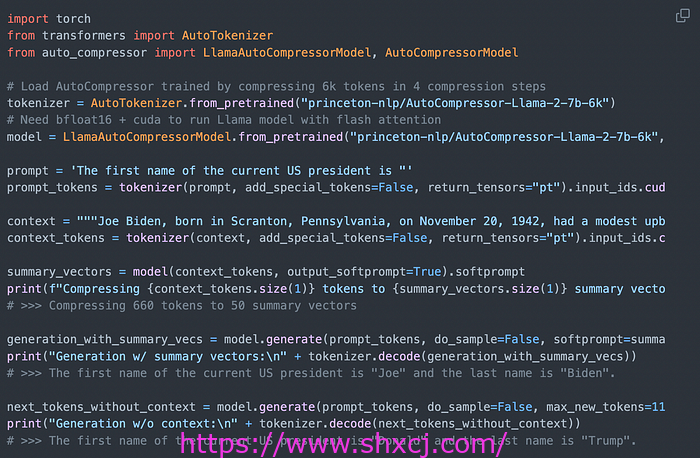
使用 API 与预先训练的 AutoCompressor 模型的示例
AutoCompressor-Llama-2–7b-6k是 LLama-2–7B 模型的微调版本。它在单个 NVIDIA A100 80GB GPU 上进行了微调。训练数据包括来自 RedPajama 的 150 亿个标记,每个标记分为 6,144 个标记的序列。
LLama-2 模型本身在训练期间保持冻结状态。仅使用 LoRA 优化了摘要标记嵌入和注意力权重。
选择性语境

基于自我信息得分的上下文过滤示例
在信息论中,熵衡量信息的不可预测性或不确定性。在语言模型中,它表示预测序列中下一个标记的不确定性程度。熵越高,表示不可预测性越大。
当 LLM 高度确定地预测标记时,这些标记对模型整体熵的贡献较小。这促使我们引入一种基于从数据中删除可预测标记的快速压缩方法。
这个想法是,如果删除困惑度较低的标记,对 LLM 对上下文的理解影响很小,因为这些标记本身并没有添加太多新信息。困惑度较高的标记被认为具有较高的自信息值。
为了压缩提示,像 Llama 或 GPT-2 这样的基础语言模型会为每个词汇单元分配一个自信息值(基本上就是说看到它时有多惊讶)。
词汇单元可以是短语、句子或标记,具体取决于我们的选择。然后,基础模型按降序对单元进行排序,并仅保留第一个 p 百分位数的单元,其中 p 是我们可以设置的变量。作者选择了基于百分位数的方法而不是绝对值方法,因为这种方法更灵活。
让我们看一个以不同词汇单位压缩的文本的例子。

使用选择性上下文对不同词汇单位和比例的文本进行压缩。
在这三个词汇单位之间,句子级压缩保持原始句子完整。此外,较低的缩减比率可使文本压缩得更多。
长LLM
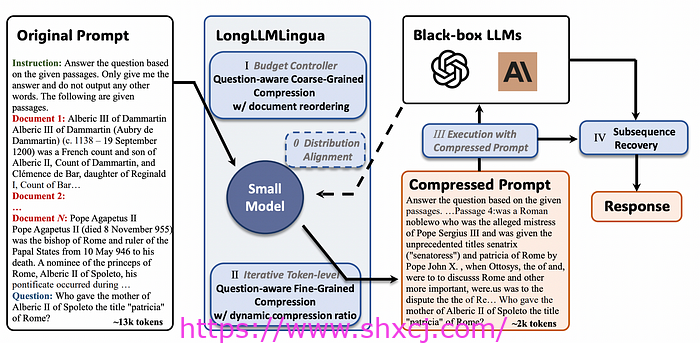
LongLLMLingua
我们要讨论的最后一种压缩方法是 LongLLMLingua。LongLLMLingua 以 LLMLingua 为基础,后者使用 Llama 之类的基础 LLM 来评估提示中每个标记的困惑度,并丢弃困惑度较低的标记。这种方法基于信息熵,类似于 Selective Context。
但是,LLMLingua 并不直接删除 token,而是使用预算控制器、token 级提示压缩算法和分布对齐机制。
LLMLingua 的问题在于它在压缩过程中没有考虑到用户的问题,这可能会导致保留不相关的信息。LongLLMLingua 声称通过将用户的问题纳入压缩过程来改进这一缺点。
他们提出的四个新组件是问题感知的粗到细压缩方法、文档重新排序机制、压缩比以及压缩后子序列恢复策略,以提高 LLM 对关键信息的感知。
问题感知粗粒度压缩意味着新方法不再单独查看每个文档,而是检查每个文档与问题的关系。如果某个文档让问题在模型看来更符合预期或“不那么令人意外”,那么它就会被视为更重要。
问题感知细粒度压缩
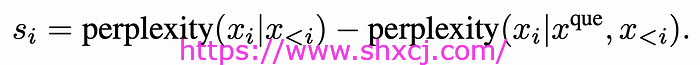
对比困惑度方程
首先,我们测量一个单词通常有多令人惊讶(不考虑问题)。这就是困惑度(x_i | x<i),它表示在给定所有单词之前看到单词 x_i 的困惑度或惊讶度。然后,我们再次测量困惑度,但这次包括上下文中的问题。这就是困惑度(x_i | x^que, x<i),它表示在给定问题和所有单词之前看到单词 x_i 的惊讶度。
这个想法是为了找出问题对每个单词的惊讶程度有多大影响。如果一个单词在加上问题后变得不那么令人惊讶,那么它可能与问题非常相关。
然后,我们根据第一步得到的重要性得分,按降序对文档进行重新排序。这样,最重要的文档就排在最前面。
后续恢复

子序列恢复示例,红色文本代表原始文本,蓝色文本是使用 LLaMA 2-7B 分词器后的结果
压缩后,日期或名称等关键实体可能会发生变化。例如,“2009”可能会变成“209”,或者“Wilhelm Conrad Rontgen”可能会变成“Wilhelmgen”。
为了避免这个问题,我们首先在 LLM 的响应中找出与压缩提示的一部分匹配的最长子字符串。此子字符串被视为关键实体。接下来,我们找到与压缩实体相对应的原始未压缩子序列。然后,我们用原始实体替换压缩实体。
带有 LlamaIndex 和快速压缩的 RAG
我们将使用 Nicolas Cage 的 Wikipedia 页面进行实际的 RAG 应用。模型可能已经在其训练数据中看到了有关演员的信息,因此我们指定我们仅根据检索到的上下文来期望答案。我们正在使用WikipediaReader()加载器加载 Wikipedia 页面。
from llama_index import(
VectorStoreIndex、
download_loader、
load_index_from_storage、
StorageContext,
)
WikipediaReader = download_loader(“WikipediaReader”)
loader = WikipediaReader()
documents = loader.load_data(pages=[ 'Nicolas Cage' ])
现在,我们正在构建一个简单的向量存储索引。只需一行即可完成文档的分块、嵌入和索引。
检索器将用于返回与用户查询最相关的文档。它通过计算查询与嵌入空间内各种文档块之间的相似度来实现这一点。我们希望检索前 2 个最相似的块。
index = VectorStoreIndex.from_documents(document)
retriever = index.as_retriever(similarity_top_k = 2)
现在我们的数据已存储在索引中,我们启动用户查询。retriever.retrieve (question)函数搜索索引以找到与查询最相似的 2 个数据块。
question = “尼古拉斯·凯奇在哪里上学?”
contexts = retriever.retrieve(question)
# 预期答案:比佛利山高中
上下文列表包含NodeWithScore数据实体,其中包含元数据和与其他节点的关系信息。目前,我们只对内容感兴趣。
context_list = [n.get_content() for n in contexts]
context_list
这是检索到的上下文。即使我们选择只获取前两个文档,我们仍然需要处理大量文本。

我们将这些相关块与原始查询结合起来以创建提示。我们将使用提示模板而不是 f 字符串,因为我们想在后续重复使用它。
然后我们将这个提示输入到gpt-3.5-turbo-16k中以生成响应。
# 原始提示的响应
from llama_index.llms import OpenAI
from llama_index.prompts import PromptTemplate
llm = OpenAI(model= "gpt-3.5-turbo-16k" )
template = (
"我们在下面提供了上下文信息。\n"
"---------------------\n"
"{context_str}"
"\n---------------------\n"
"根据此信息,请回答问题:{query_str}\n"
)
qa_template = PromptTemplate(template)
# 您可以创建文本提示(用于完成 API)
prompt = qa_template.format ( context_str= "\n\n" .join(context_list), query_str=question)
response = llm.complete(prompt)
print ( str (response))
输出:
尼古拉斯·凯奇就读于比弗利山庄高中,后来就读于加州大学洛杉矶分校戏剧、电影和电视学院。
现在,让我们测量使用不同的快速压缩技术后的 RAG 性能。
选择性语境
我们将使用0.5 的reduce_ratio并观察模型的表现。如果压缩保留了我们感兴趣的信息,我们将降低该值以压缩更多文本。
from selective_context import SelectiveContext
sc = SelectiveContext(model_type= 'gpt2' , lang= 'en' )
context_string = "\n\n" .join(context_list)
context, Reduced_content = sc(context_string, Reduce_ratio = 0.5 , Reduce_level= "Sent" )
prompt = qa_template.format ( context_str= "\n\n" .join(Reduced_content), query_str=question)
response = llm.complete(prompt)
print ( str (Response))
这是减少的内容。

使用选择性上下文减少内容。
压缩到了句子层面,但不幸的是,尼古拉斯·凯奇的学校信息丢失了。我们还尝试了标记和短语层面的压缩,但信息仍然缺失。
输出:
所提供的信息并未提及尼古拉斯·凯奇在哪里上学。
LongLLM
# 设置 LLMLingua
from llama_index.query_engine import RetrieverQueryEngine
from llama_index.response_synthesizers import CompactAndRefine
from llama_index.indices.postprocessor import LongLLMLinguaPostprocessor
node_postprocessor = LongLLMLinguaPostprocessor(
indication_str= "根据上下文,请回答最后一个问题" ,
target_token= 300 ,
rank_method= "longllmlingua" ,
additional_compress_kwargs={
"condition_compare" : True ,
"condition_in_question" : "after" ,
"context_budget" : "+100" ,
"reorder_context" : "sort" , # 启用文档重新排序,
"dynamic_context_compression_ratio" : 0.3 ,
},
)
removed_nodes = withdrawer.retrieve(question)
synthesizer =压缩并优化()
postprocess_nodes函数是我们最关心的函数,因为它缩短了给定查询的节点文本。
from llama_index.indices.query.schema import QueryBundle select .mode import QueryBundle
new_retrieved_nodes = node_postprocessor.postprocess_nodes (
retrieved_nodes, query_bundle = QueryBundle ( query_str = question )
)
现在我们来看看结果。
original_contexts = "\n\n".join([n.get_content() for n in removed_nodes])= " \n \n " .join([n.get_content() for n in removed_nodes])
compressed_contexts = " \n \n " .join([n.get_content() for n in new_retrieved_nodes])
original_tokens = node_postprocessor._llm_lingua.get_token_length(original_contexts)
compressed_tokens = node_postprocessor._llm_lingua.get_token_length(compressed_contexts)
print (compressed_contexts)
print ()
print ( "原始标记:" , original_tokens)
print ( "压缩标记:" , compressed_tokens)
print ( "压缩比率:" , f "{original_tokens/(compressed_tokens + 1e-5):.2f}x" )
原始Token:2362
压缩Token:344
压缩率:6.87x
压缩上下文:

使用 LLMLingua 压缩上下文。
让我们看看模型是否理解压缩上下文。
响应 = 合成器.合成(问题,新检索节点)
打印(str(响应))
输出:
尼古拉斯·凯奇就读于比佛利山庄高中。
从使用longllmlingua压缩的上下文中,可以清楚地看出参与者的学校。我们还将输入令牌减少了近7 倍!这意味着节省了0.00202 美元。想象一下 10 亿个令牌的成本降低。通常,它们的成本为 1000 美元,但通过即时压缩,我们只需支付约 150 美元。
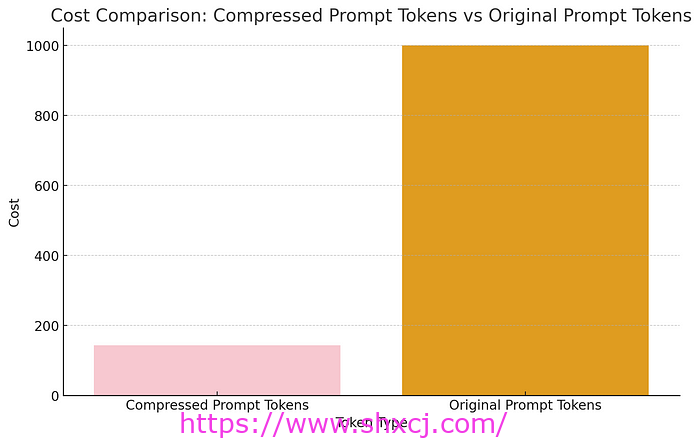
压缩提示与原始提示的成本比较
结论
在讨论的方法中,LongLLMLingua 似乎是 RAG 应用程序中提示压缩最有前景的方法。它将提示压缩了 6-7 倍,同时仍保留了 LLM 生成准确响应所需的关键信息。
Paragoger衍生者AI训练营。发布者:稻草人,转载请注明出处:https://www.shxcj.com/archives/3096