关键要点
- 今天,我们发表了深入探讨 Stable Diffusion 3 底层技术的研究论文。
- 根据人类偏好评估,Stable Diffusion 3 在排版和提示遵循方面优于最先进的文本到图像生成系统,例如 DALL·E 3、Midjourney v6 和 Ideogram v1。
- 我们新的多模态扩散变换器 (MMDiT) 架构对图像和语言表示使用单独的权重集,与以前版本的稳定扩散相比,这提高了文本理解和拼写能力。
- 具体API :https://platform.stability.ai/docs/api-reference
- 模型下载地址:https://huggingface.co/stabilityai/stable-diffusion-3-medium

表现
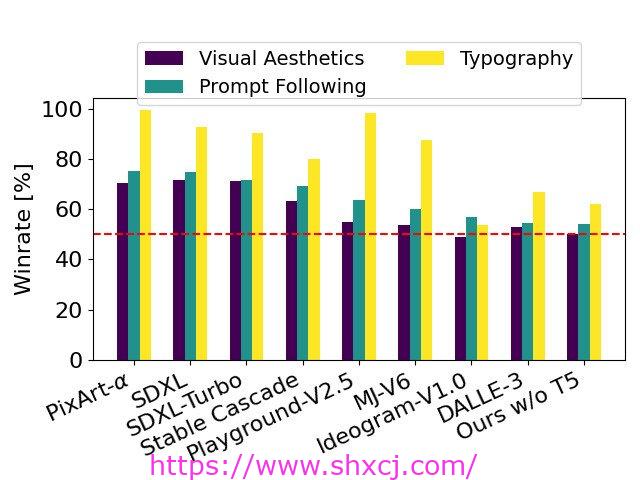
以 SD3 为基准,该图表概述了基于人类对视觉美学、快速跟随和排版的评估,它胜过竞争模型的领域。
我们已经将 Stable Diffusion 3 的输出图像与其他各种开放模型(包括SDXL、SDXL Turbo、Stable Cascade、 Playground v2.5 和 Pixart-α)以及闭源系统(如 DALL·E 3、Midjourney v6 和 Ideogram v1)进行了比较,以根据人工反馈评估性能。在这些测试中,向人工评估者提供了每个模型的示例输出,并要求他们根据模型输出与所给提示的上下文的接近程度(“提示遵循”)、文本根据提示呈现的效果(“排版”)以及哪幅图像的美学质量更高(“视觉美学”)来选择最佳结果。
根据我们的测试结果,我们发现 Stable Diffusion 3 在上述所有领域都等同于或优于当前最先进的文本到图像生成系统。
在早期未优化的消费级硬件推理测试中,我们最大的 SD3 模型(具有 8B 参数)可装入 RTX 4090 的 24GB VRAM,使用 50 个采样步骤时需要 34 秒才能生成分辨率为 1024×1024 的图像。此外,在初始版本中,Stable Diffusion 3 将有多种变体,范围从 800m 到 8B 参数模型,以进一步消除硬件障碍。

架构细节
对于文本到图像的生成,我们的模型必须同时考虑文本和图像两种模态。这就是我们将这种新架构称为 MMDiT 的原因,指的是它能够处理多种模态。与之前的稳定扩散版本一样,我们使用预训练模型来得出合适的文本和图像表示。具体来说,我们使用三种不同的文本嵌入器(两个 CLIP 模型和 T5)来编码文本表示,并使用改进的自动编码模型来编码图像标记。
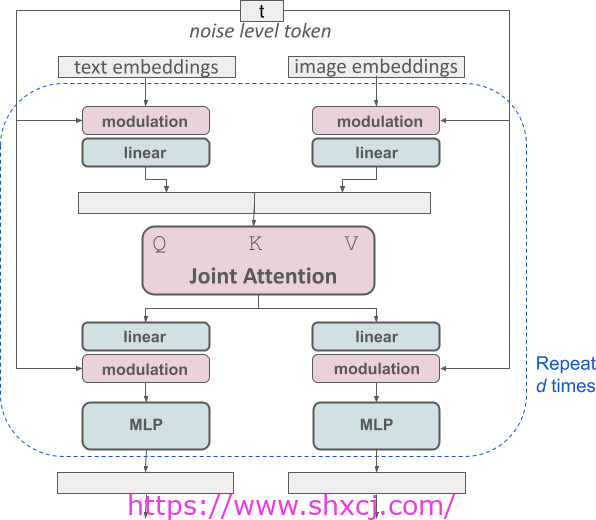
我们修改的多模扩散变换器块的概念可视化:MMDiT。
SD3 架构建立在Diffusion Transformer(“DiT”,Peebles & Xie,2023)的基础上。由于文本和图像嵌入在概念上完全不同,我们对这两种模态使用两组独立的权重。如上图所示,这相当于为每种模态配备两个独立的变换器,但将两种模态的序列连接起来进行注意操作,这样两种表示都可以在自己的空间中工作,同时考虑到另一种表示。

在训练过程中测量视觉保真度和文本对齐时,我们新颖的 MMDiT 架构的表现优于成熟的文本到图像主干,例如UViT(Hoogeboom 等人,2023 年)和DiT(Peebles & Xie,2023 年) 。
通过使用这种方法,信息可以在图像和文本标记之间流动,从而提高生成的输出中的整体理解力和排版效果。正如我们在论文中所讨论的那样,这种架构还可以轻松扩展到多种模式,例如视频。

得益于 Stable Diffusion 3 改进的快速跟随功能,我们的模型能够创建专注于各种不同主题和品质的图像,同时还能保持图像本身风格的高度灵活性。

通过重新加权来改善整流流
稳定扩散 3 采用整流流 (RF) 公式(Liu 等人,2022 年;Albergo 和 Vanden-Eijnden,2022 年;Lipman 等人,2023 年),其中数据和噪声在训练期间以线性轨迹连接。这会产生更直的推理路径,然后允许以更少的步骤进行采样。此外,我们在训练过程中引入了一种新颖的轨迹采样计划。此计划为轨迹的中间部分赋予更多权重,因为我们假设这些部分会带来更具挑战性的预测任务。我们使用多个数据集、指标和采样器设置针对LDM、EDM和ADM等 60 种其他扩散轨迹测试了我们的方法,以进行比较。结果表明,虽然以前的 RF 公式在少步采样方案中表现出更好的性能,但它们的相对性能会随着步骤的增多而下降。相比之下,我们的重新加权 RF 变体可以持续提高性能。
缩放整流流变压器模型

我们使用重新加权的 Rectified Flow 公式和 MMDiT 主干对文本到图像合成进行了扩展研究。我们训练的模型范围从具有 450M 个参数的 15 个块到具有 8B 个参数的 38 个块,并观察到验证损失随着模型大小和训练步骤而平稳下降(上行)。为了测试这是否会转化为模型输出的有意义的改进,我们还评估了自动图像对齐指标(GenEval)以及人类偏好分数(ELO)(下行)。我们的结果表明这些指标与验证损失之间存在很强的相关性,表明后者是整体模型性能的有力预测指标。此外,扩展趋势没有饱和的迹象,这使我们对未来可以继续提高模型性能充满信心。
灵活的文本编码器
通过移除用于推理的内存密集型 4.7B 参数 T5 文本编码器,SD3 的内存需求可以显著降低,而性能损失很小。移除此文本编码器不会影响视觉美观度(不使用 T5 的胜率:50%),并且只会导致文本一致性略有降低(胜率 46%),如上图“性能”部分所示。但是,我们建议包括 T5 以充分利用 SD3 生成书面文本的功能,因为我们观察到不使用 T5 的排版生成性能下降幅度更大(胜率 38%),如以下示例所示:

仅在渲染涉及许多细节或大量书面文本的非常复杂的提示时,删除 T5 进行推理才会导致性能显著下降。上图显示每个示例有三个随机样本。
Paragoger衍生者AI训练营。发布者:稻草人,转载请注明出处:https://www.shxcj.com/archives/2859