
直到几个月前,提示词工程才被大肆宣传。整个就业市场都充斥着提示词工程师的角色,但现在情况已不再如此。
提示词工程不是任何艺术或科学,它只是一种聪明的汉斯现象,人类为系统提供必要的背景信息,以便以更好的方式回答。
人们甚至写了书/博客,比如《前 50 个提示,以充分利用 GPT》,等等。但大规模实验清楚地表明,没有一种单一的提示或策略可以解决各种问题,只是有些提示单独看起来更好,但综合分析后就会出现问题。
所以,今天我们要讨论DSPY:将声明性语言模型调用编译成自我改进的管道,这是斯坦福大学为自我改进管道开发的框架,其中 LLM 被视为由编译器优化的模块,类似于 PyTorch 中的抽象。

介绍
正如我上面提到的,互联网上充斥着各种推销书籍和博客。其中大多数只是在向你推销一堆垃圾。现在,正如我所说,其中一些可能确实有效,但这不是构建应用程序的好方法。不知道什么时候某些东西不起作用很重要,我们需要定义一个安全的假设空间,系统在其中可以工作,也可以不工作。
在 Google 上搜索“快速工程”书籍的前几个结果。这些书中写有文字提示,而不是使用 CoT 或 ReAct 等技术
甚至有论文表明,通过某些情感提示,法学硕士的表现会提高。对我来说,我仍然对这种论文的真实性持保留态度。它能持续多久?对每个主题都是如此吗?是否有主题进行这种情感提示可能会导致更糟糕的结果?有很多这样的论文,它们无意中发表了不成熟的研究。另一篇这样的论文是《自回归的余烬》,很多东西后来被证明是错误的。
https://arxiv.org/pdf/2307.11760
但更大的问题是,我需要用什么样的科学/系统的方式告诉系统,“如果你不立即给出答案,我可能会被解雇,或者我的祖母病了,等等”。这只是人们随机试图侵入法学硕士的行为。
理解提示问题
例如,当我说“使用 RAG 添加 5 次 CoT,使用困难的负面示例”时,从概念上讲非常清楚,但在实践中很难实现。LLM 对提示非常敏感,因此将这种结构放在提示中在大多数情况下都不起作用。LLM 的行为对提示的编写方式非常敏感,这使得操纵它们变得非常困难。
因此,当我们构建管道时,不仅仅是我试图说服 LLM 以某种方式给出输出,而且更多的输出应该受到限制,以便它可以作为更大管道中其他模块的输入。
为了解决这个问题,已经有很多研究,但它们在很多方面都很有限。他们中的大多数人都在努力使用字符串模板,这些模板很脆弱,不可扩展。语言模型会随着时间的推移而改变,提示会中断。如果我们想将模块插入不同的管道,这是行不通的。我们希望它与更新的工具、新的数据库或检索器进行交互,这是行不通的。
这正是 DSPy 旨在解决的问题,将 LLM 作为一个模块,根据它与管道中其他组件的交互方式自动调整其行为。
DSPy 范式:让我们编程 — 而不是提示 — LM
因此,DSPy 的目标是将重点从调整 LLM 转移到良好的总体系统设计。
但该怎么做呢?
为了从心理层面思考这个问题,我们可以将 LLM 视为:设备:执行指令并通过类似于 DNN 的抽象进行操作。
例如,我们在 PyTorch 中定义了一个卷积层,它可以对来自其他层的一组输入进行操作。从概念上讲,我们可以堆叠这些层并在原始输入上实现所需的抽象级别,我们不需要定义任何 CUDA 核心和许多其他指令。所有这些都已在卷积层的定义中抽象化。这就是我们希望用 LLM 做的事情,其中 LLM 是抽象模块,以不同的组合堆叠以实现某种类型的行为,无论是 CoT、ReAct 还是其他什么。
为了获得期望的行为,我们需要改变一些事情:

NLP 签名
这些只是我们希望 LLM 实现的行为的声明。这仅定义了需要实现什么,而不是如何实现的规范。规范告诉 DSPy转换的作用,而不是如何提示 LLM 执行转换。
![]()
![]() 签名示例
签名示例
- 签名处理结构化格式和解析逻辑。
- 签名可以被编译成自我改进和管道自适应的提示或微调。
DSPY 使用以下方式推断字段的作用:
- 他们的名字,例如 DSPy 将使用上下文学习来以不同于答案的方式解释问题。
- 它们的踪迹(输入/输出示例)
注意:所有这些都不是硬编码的,而是系统在编译过程中解决的。
模块
在这里,我们使用签名来构建模块,例如,如果我们想构建一个 CoT 模块,我们会使用这些签名来构建它。这会自动生成高质量的提示,以实现某些提示技术的行为。
更技术性的定义:模块是通过抽象提示技术来表达签名的参数化层。
![]()
![]() 模块类型
模块类型
声明之后,模块的行为就像一个可调用函数。
参数:为了表达特定的签名,任何 LLM 调用都需要指定:
- 要调用的特定 LLM
- 提示说明
- 各签名字段的字符串前缀
- 演示使用了少量的镜头提示和/或微调数据
优化器
为了使这个系统发挥作用,优化器基本上会采用整个管道并根据某个指标对其进行优化,并在此过程中自动提出最佳提示,甚至语言模型的权重也会在此过程中更新。
高层的想法是,我们将使用优化器来编译我们的代码,从而进行语言模型调用,以便我们管道中的每个模块都被优化为为我们自动生成的提示,或者为我们的语言模型生成一组新的经过微调的权重,以适合我们正在尝试解决的任务。
实例
单一的搜索查询通常不足以完成复杂的 QA 任务。例如,其中的一个例子HotPotQA包括有关“Right Back At It Again”作者出生城市的问题。搜索查询通常正确地将作者标识为“Jeremy McKinnon”,但缺乏确定作者出生时间的预期答案的能力。
在检索增强型 NLP 文献中,应对这一挑战的标准方法是构建多跳搜索系统,例如 GoldEn(Qi 等人,2019 年)和 Baleen(Khattab 等人,2021 年)。这些系统读取检索到的结果,然后生成其他查询以在必要时收集其他信息,然后得出最终答案。使用 DSPy,我们只需几行代码就可以轻松模拟此类系统。
目前,为了实现这一点,我们需要编写非常复杂的提示,并以非常混乱的方式构建它们。但不好的是,一旦我改变问题类型,我可能需要完全改变系统设计,但使用 DSPy 则不需要。
配置语言模型和检索模型
import dspy
turbo = dspy.OpenAI(model= 'gpt-3.5-turbo')
colbertv2_wiki17_abstracts = dspy.ColBERTv2(url= 'http://20.102.90.50:2017/wiki17_abstracts')
dspy.settings.configure(lm=turbo,rm=colbertv2_wiki17_abstracts)加载数据集
我们利用上述HotPotQA数据集,这是一组通常以多跳方式回答的复杂问答对。我们可以通过类加载 DSPy 提供的此数据集HotPotQA:
建筑特色
import dspy.datasets from HotPotQA
# 加载数据集。
dataset = HotPotQA(train_seed= 1 , train_size= 20 , eval_seed= 2023 , dev_size= 50 , test_size= 0 )
# 告诉 DSPy,“question”字段是输入。任何其他字段都是标签和/或元数据。
trainset = [x.with_inputs( 'question' ) for x in dataset.train]
devset = [x.with_inputs( 'question' ) for x in dataset.dev]
len (trainset), len (devset)
# 输出
( 20 , 50 )
现在我们已经加载了数据,让我们开始定义 Baleen 管道子任务的签名。
我们将首先创建以作为输入并作为输出的GenerateAnswer签名。contextquestionanswer
class GenerateAnswer (dspy.Signature):
"""用简短的事实答案回答问题。"""
context = dspy.InputField(desc= "可能包含相关事实" )
question = dspy.InputField()
answer = dspy.OutputField(desc= "通常在 1 到 5 个字之间" )
class GenerateSearchQuery (dspy.Signature):
"""编写一个简单的搜索查询,帮助回答一个复杂的问题。"""
context = dspy.InputField(desc= "可能包含相关事实" )
question = dspy.InputField()
query = dspy.OutputField()构建管道
那么,让我们来定义程序本身SimplifiedBaleen。有很多可能的方法来实现这一点,但我们将把这个版本保留为关键元素。
import dsp.utils from deduplicate
clss SimplifiedBaleen(dspy.Module):
def __init__(self,passages_per_hop= 3,max_hops= 2):
super()。__init__()
self.generate_query = [dspy.ChainOfThought(GenerateSearchQuery)for _ in range(max_hops)]
self.retrieve = dspy.Retrieve(k=passages_per_hop)
self.generate_answer = dspy.ChainOfThought(GenerateAnswer)
self.max_hops = max_hops
def forward(self,question):
context = []
for hop in range(self.max_hops):
query = self.generate_query[hop](context=context,question=question)。query
passages = self.retrieve(query)。passages
context = deduplicate(context + passages)
pred = self.generate_answer(context=context,question=question)
return dspy.Prediction(context=context,answer=pred.answer)
我们可以看到,该__init__方法定义了几个关键的子模块:
- generate_query:对于每一跳,我们将有一个带有签名
dspy.ChainOfThought的预测器GenerateSearchQuery。 - 检索:该模块将通过模块使用生成的查询对我们定义的 ColBERT RM 搜索索引进行搜索
dspy.Retrieve。 - generate_answer:该
dspy.Predict模块将与签名一起使用GenerateAnswer以产生最终答案。
该forward方法在简单的控制流中使用这些子模块。
- 首先,我们将循环至
self.max_hops时间。 - 在每次迭代中,我们将使用 的预测器生成一个搜索查询
self.generate_query[hop]。 - 我们将使用该查询检索前 k 个段落。
- 我们将把(去重复的)段落添加到我们的
context累加器中。 - 循环结束后,我们将用它
self.generate_answer来产生答案。 context我们将返回已检索到的和预测的预测answer。
执行管道
让我们在零样本(未编译)设置下执行该程序。
这并不一定意味着性能会很差,而是意味着我们直接受到底层 LM 的可靠性限制,无法从最少的指令理解我们的子任务。通常,当在最简单和最标准的任务(例如,回答有关流行实体的简单问题)上使用最昂贵/最强大的模型(例如,GPT-4)时,这是完全没问题的。
#向这个简单的 RAG 程序提出任何你喜欢的 问题。 my_question = "David Gregory 继承的城堡有多少层?" #获取预测。这包含`pred.context`和`pred.answer`。uncompiled_baleen = SimplifiedBaleen() # 未编译(即零样本)程序pred = uncompiled_baleen(my_question) # 打印上下文和答案。print(f "问题:{my_question}" ) print(f "预测答案:{pred.answer}" ) print(f "检索到的上下文(截断):{[c[:200] + '...' for c in pred.context]}" ) #输出问题: David Gregory 继承的城堡有多少层?预测答案:五层检索到的上下文(截断):[ 'David Gregory (physician) |大卫·格雷戈里 (David Gregory,1625 年 12 月 20 日 - 1720 年) 是苏格兰医生和发明家。他的姓氏有时拼写为 Gregorie,这是苏格兰的原始拼写。他继承了金恩……', '博林遗产 | 博林遗产是英国作家菲利帕·格雷戈里的一部小说,于 2006 年首次出版。它是她之前的小说“另一个博林女孩”的直接续集,......', '加埃塔的格雷戈里 | 格雷戈里从 963 年起直到去世一直是加埃塔公爵。他是加埃塔的多西比利斯二世和他的妻子奥拉尼亚的第二个儿子。他继承了他的兄弟约翰二世的王位,约翰二世留下了唯一的女儿......', '金奈尔迪城堡 | 金奈尔迪城堡是一座塔楼,有五层楼和一个阁楼,位于苏格兰阿伯丁郡阿伯奇德以南两英里处。另一个名字是 Old Kinnairdy....', 'Kinnaird Head | Kinnaird Head(苏格兰盖尔语:“An Ceann Àrd”,“高岬角”)是伸入北海的岬角,位于苏格兰东海岸阿伯丁郡弗雷泽堡镇内...', 'Kinnaird Castle, Brechin | Kinnaird Castle 是一座 15 世纪的城堡,位于苏格兰安格斯。这座城堡一直是卡内基家族(Southesk 伯爵)的居所,已有 600 多年的历史....']
优化管道
然而,零样本方法很快就无法满足更专业的任务、新颖的领域/设置以及更高效(或开放)的模型的要求。
为了解决这个问题,DSPy 提供了编译功能。让我们来编译我们的多跳(SimplifiedBaleen)程序。
让我们首先定义编译的验证逻辑:
- 预测答案与黄金答案相符。
- 检索到的上下文包含黄金答案。
- 所生成的查询都不是杂乱无章的(即,长度均不超过 100 个字符)。
- 生成的查询均未粗略重复(即,没有一个查询的 F1 分数在早期查询的 0.8 或更高范围内)。
defvalidate_context_and_answer_and_hops (example,pred,trace = None):如果不是dspy.evaluate.answer_exact_match(example,pred):返回False如果不是dspy.evaluate.answer_passage_match ( example,pred ):返回Falsehops = [ example.question] + [outputs.query for *_,outputs in trace if 'query' in output]如果max([ len(h)for h in hops])> 100:返回False如果有(dspy.evaluate.answer_exact_match_str(hops [idx],hops [:idx],frac = 0.8)对于idx在范围内(2,len(hops))):返回False返回True
我们将使用 DSPy 中最基本的提词器之一,即BootstrapFewShot使用少量示例优化管道中的预测器。
从dspy.teleprompt导入BootstrapFewShot
提词器 = BootstrapFewShot(metric=validate_context_and_answer_and_hops) compilation_baleen
= teleprompter.compile (SimplifiedBaleen(),teacher=SimplifiedBaleen(passages_per_hop= 2 ),trainset=trainset)
评估管道
现在让我们定义评估函数并比较未编译和已编译的 Baleen 管道的性能。虽然此 devset 不能作为完全可靠的基准,但对于本教程来说还是很有启发的。
从dspy.evaluate.evaluate导入Evaluate
# 定义指标来检查我们是否检索到了正确的文档
def gold_passages_retrieved ( example, pred, trace= None ):
gold_titles = set ( map (dspy.evaluate.normalize_text, example[ "gold_titles" ]))
found_titles = set (
map (dspy.evaluate.normalize_text, [c.split( " | " )[ 0 ] for c in pred.context])
)
return gold_titles.issubset(found_titles)
# 设置 `evaluate_on_hotpotqa` 函数。我们将在下面多次使用它。
evaluation_on_hotpotqa = Evaluate(devset=devset, num_threads= 1 , display_progress= True , display_table= 5 )
uncompiled_baleen_retrieval_score = evaluation_on_hotpotqa(uncompiled_baleen, metric=gold_passages_retrieved, display= False )
compilation_baleen_retrieval_score = evaluation_on_hotpotqa(compiled_baleen, metric=gold_passages_retrieved)
print ( f"## 未编译的 Baleen 的检索分数:{uncompiled_baleen_retrieval_score} " )
print ( f"## 已编译的 Baleen 的检索分数:{compiled_baleen_retrieval_score} " )
#Output
## 未编译的 Baleen 的检索分数:36.0
## 已编译的 Baleen 的检索分数:60.0
结论
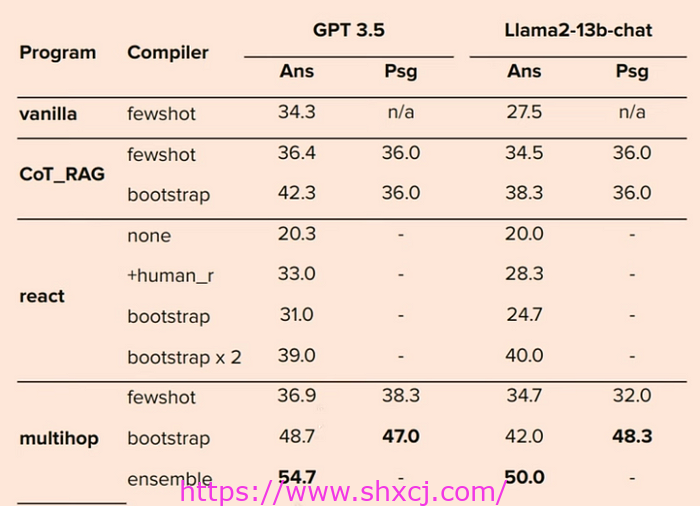
这些结果表明,在 DSPy 中结合多跳设置甚至可以超越人类反馈。他们甚至表明,即使是像 T5 这样小得多的模型,在 DSPy 设置中使用时也可以与 GPT 进行比较。DSPy 是我在 lang chain 发布后遇到的最酷的系统之一,这表明在制作一个更好、系统设计的系统方面有很大的希望,而不是在大型 LLM 管道中疯狂地放置零件。
Paragoger衍生者AI训练营。发布者:稻草人,转载请注明出处:https://www.shxcj.com/archives/2752