
前言:
目前Chat GPT的使用如火如荼,但对于中国区的用户来说非常痛,是因为美国的产品不允许中国地区使用。虽然有很多用户通过一些第三方的平台,接口调用,最终可以使用GPT的服务,但是中间环节的不确定性让很多真正想要完全安全的使用GPT的用户望而却步。这里我们整理出来2种主要的方法,去完成这个步骤。
关注 2img.ai 获取更多AI资讯和硬核资料
可以明确的是Microsoft的Azure Services是完全可以用的。
OpenAI官方及使用情况
ChatGPT访问网址:chat.openai.com
注册一个账户后登录即可使用。 中国地区用户可能需要科学上网。
主要界面如下:
- 版本选择。
- 套餐选择
- 正常功能使用。
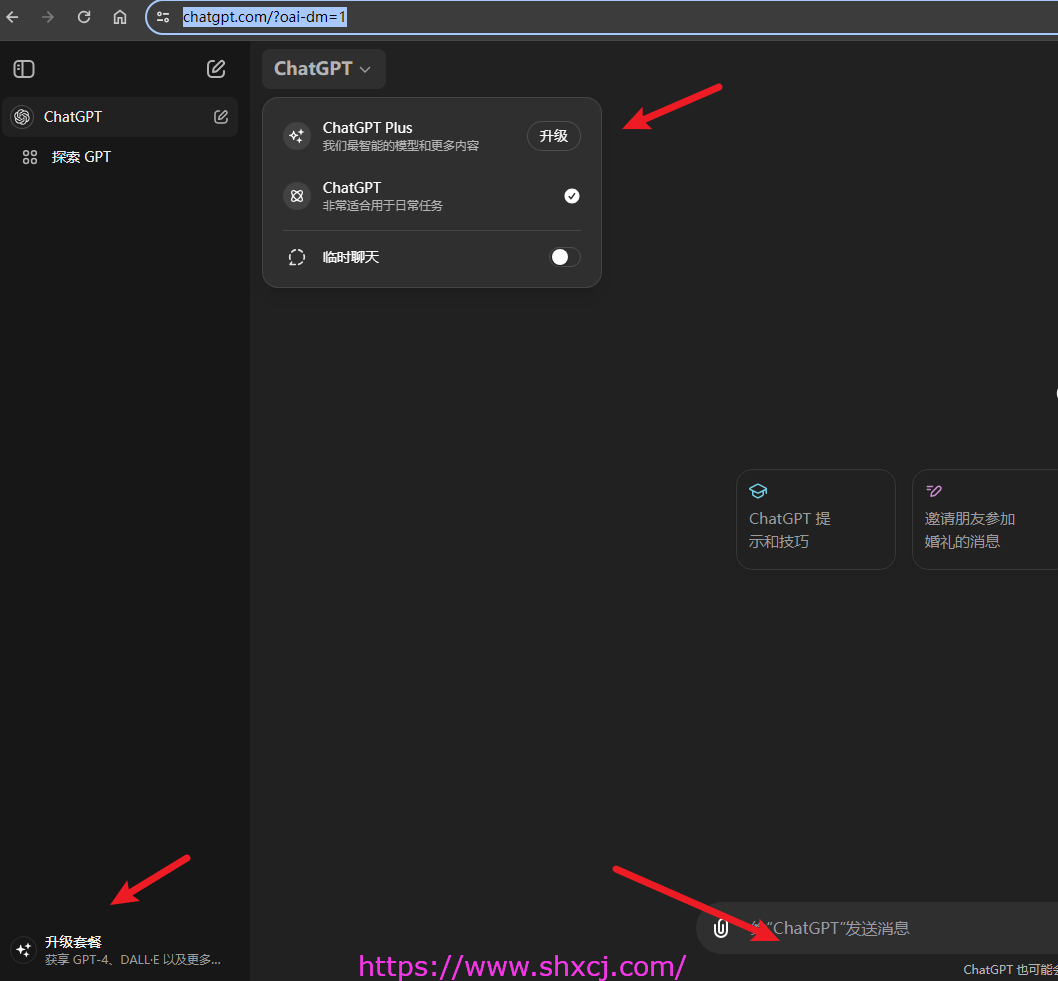

使用简单的聊天功能,是免费的。
但是更多的内容需要付费。基本付费账号类型和对应功能如下:

支付方法中可以看到,支持中国银联
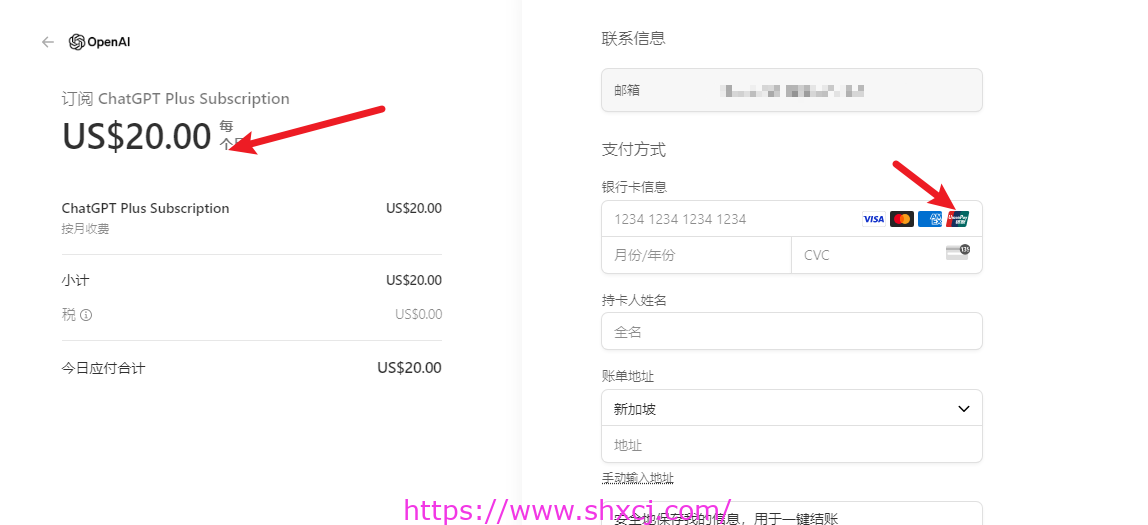
需要尤其提醒开发者的是这个账号的付费和通过API调用的方式支付费用是两回事。
我觉得这方面官方做的非常不友善,具体的信息藏在一个很深的地方。见下图
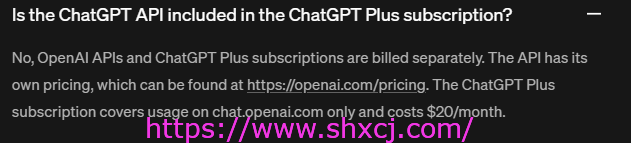
翻译过来就是20美元/月的注册产品和API调用时两个分开的支付。所以大家不要搞错了。
有2个内容本文不做过多讲解,分别是:
- 如何注册GPT的账号。因为网上有很多了。并且使用各种临时美国手机号搞定了注册短信确认
- 如何进行银行卡支付。由于必须要使用美国信用卡。因此很多人使用Depay等虚拟信用卡来实现。但有一定的风险,请用户注意。
使用GPT的基本概念:
Text Generation Model 文本生成模型
OpenAI 的文本生成模型(通常称为生成式预训练转换器或简称“GPT”模型),如 GPT-4 和 GPT-3.5,已经过训练以理解自然语言和形式语言。像 GPT-4 这样的模型允许根据其输入输出文本。这些模型的输入也称为“提示”。设计提示本质上就是如何“编程”像 GPT-4 这样的模型,通常是通过提供说明或一些如何成功完成任务的示例。像 GPT-4 这样的模型可用于各种各样的任务,包括内容或代码生成、摘要、对话、创意写作等。在我们的入门文本生成指南和我们的提示工程指南中阅读更多内容。
Assistant助手
助手是指实体,在 OpenAI API 的情况下,它们由像 GPT-4 这样的大型语言模型提供支持,能够为用户执行任务。这些助手根据模型上下文窗口中嵌入的指令进行操作。他们通常还可以使用工具,让助手执行更复杂的任务,例如运行代码或从文件中检索信息。在我们的助手 API 概述中阅读有关助手的更多信息。
Embedding嵌入
嵌入是一段数据(例如一些文本)的矢量表示,旨在保留其内容和/或含义的各个方面。在某种程度上相似的数据块往往具有比不相关的数据更紧密的嵌入。OpenAI 提供文本嵌入模型,该模型以文本字符串作为输入,并产生嵌入向量作为输出。嵌入可用于搜索、聚类、推荐、异常检测、分类等。在我们的嵌入指南中阅读有关嵌入的更多信息。
Token标记
文本生成和嵌入模型以称为标记的块形式处理文本。标记表示常见的字符序列。例如,字符串“tokenization”分解为“token”和“ization”,而像“the”这样的简短而常见的单词则表示为单个标记。请注意,在句子中,每个单词的第一个标记通常以空格字符开头。查看我们的标记器工具来测试特定字符串并查看它们如何转换为标记。根据粗略的经验法则,1 个标记大约为 4 个字符或 0.75 个英文单词。
需要记住的一个限制是,对于文本生成模型,提示和生成的输出的总和不得超过模型的最大上下文长度。对于嵌入模型(不输出标记),输入必须短于模型的最大上下文长度。每个文本生成和嵌入模型的最大上下文长度可以在模型索引中找到。
目前GPT的主流模型情况
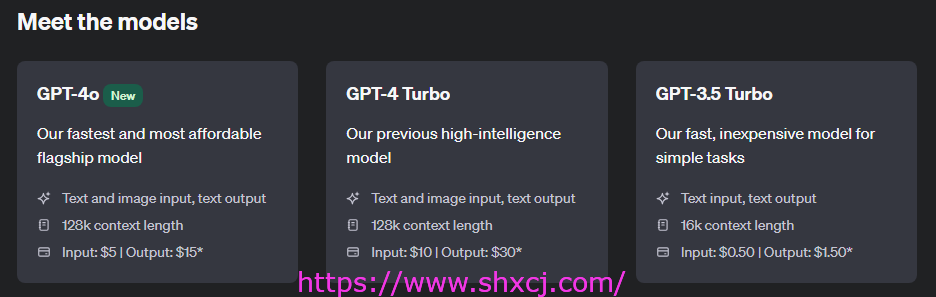
模型概述
OpenAI API 由一系列具有不同功能和价格点的模型提供支持。您还可以通过微调对我们的模型进行自定义,以满足您的特定用例。
| 模型 | 描述 |
| GPT-4o | 速度最快、价格最实惠的旗舰机型 |
| GPT-4 Turbo 和 GPT-4 | 上一组高智能模型 |
| GPT-3.5 Turbo | 一种用于简单任务的快速、廉价模型 |
| DALL·E | 根据自然语言提示生成和编辑图像的模型 |
| TTS | 一组可以将文本转换为自然语音音频的模型 |
| Whisper | 可以将音频转换为文本的模型 |
| Embeddings | 一组可以将文本转换为数字形式的模型 |
| Moderation | 可以检测文本是否敏感或不安全的微调模型 |
| GPT base | 一组无需遵循指令就能理解并生成自然语言或代码的模型 |
| Deprecated | 已弃用的型号的完整列表以及建议的替代品 |
GPT-4o
GPT-4o(“o” 代表“omni”)是我们最先进的模型。它是多模式的(接受文本或图像输入并输出文本),具有与 GPT-4 Turbo 相同的高智能,但效率更高——它生成文本的速度提高了 2 倍,成本降低了 50%。此外,GPT-4o 在我们所有模型中,对非英语语言的视觉和性能都最好。GPT-4o 在 OpenAI API 中可供付费客户使用。
| 模型 | 描述 | 上下文窗口 | 训练数据 |
| GPT-4O | 新的 GPT-4o 我们最先进的多模式旗舰模型,比 GPT-4 Turbo 更便宜、更快。目前指向gpt-4o-2024-05-13。 | 128,000 个代币 | 截至 2023 年 10 月 |
| gpt-4o-2024-05-13 | gpt-4o目前指向这个版本。 | 128,000 个代币 | 截至 2023 年 10 月 |
GPT-4 Turbo 和 GPT-4
GPT-4 是一个大型多模态模型(接受文本或图像输入并输出文本),由于其更广泛的常识和高级推理能力,它可以比之前的任何模型更准确地解决难题。GPT-4 在 OpenAI API 中可供付费客户使用。与 一样,GPT-4 针对聊天进行了优化,但对于使用聊天完成 API 的gpt-3.5-turbo传统完成任务也非常有效。
| 模型 | 描述 | 上下文窗口 | 训练数据 |
| GPT-4-Turbo 版 | 新的 带视觉的 GPT-4 Turbo 最新的带视觉功能的 GPT-4 Turbo 模型。视觉请求现在可以使用 JSON 模式和函数调用。当前指向gpt-4-turbo-2024-04-09。 | 128,000 个代币 | 截至 2023 年 12 月 |
| GPT-4-涡轮-2024-04-09 | 带有 Vision 模型的 GPT-4 Turbo。Vision 请求现在可以使用 JSON 模式和函数调用。gpt-4-turbo目前指向此版本。 | 128,000 个代币 | 截至 2023 年 12 月 |
| GPT-4-Turbo 预览版 | GPT-4 Turbo 预览模型。当前指向gpt-4-0125-preview。 | 128,000 个代币 | 截至 2023 年 12 月 |
| gpt-4-0125-预览 | GPT-4 Turbo 预览模型旨在减少模型无法完成任务的“懒惰”情况。最多返回 4,096 个输出标记。 | 128,000 个代币 | 截至 2023 年 12 月 |
| gpt-4-1106-预览 | GPT-4 Turbo 预览模型具有改进的指令跟踪、JSON 模式、可重现输出、并行函数调用等功能。最多返回 4,096 个输出标记。这是一个预览模型 | 128,000 个代币 | 截至 2023 年 4 月 |
| GPT-4-Vision-预览 | GPT-4 模型除了具备所有其他 GPT-4 Turbo 功能外,还具备理解图像的能力。这是一个预览模型,我们建议开发人员现在使用,gpt-4-turbo其中包括视觉功能。目前指向gpt-4-1106-vision-preview。 | 128,000 个代币 | 截至 2023 年 4 月 |
| GPT-4-1106-视觉预览 | GPT-4 模型除了具备所有其他 GPT-4 Turbo 功能外,还具备理解图像的能力。这是一个预览模型,我们建议开发人员现在使用,gpt-4-turbo其中包括视觉功能。最多返回 4,096 个输出标记。 | 128,000 个代币 | 截至 2023 年 4 月 |
| GPT-4 型 | 目前指向gpt-4-0613。参见持续模型升级。 | 8,192 个代币 | 截至 2021 年 9 月 |
| gpt-4-0613 | 从 2023 年 6 月 13 日起的快照gpt-4,具有改进的函数调用支持。 | 8,192 个代币 | 截至 2021 年 9 月 |
| gpt-4-32k | 目前指向gpt-4-32k-0613。参见持续模型升级。该模型从未被广泛推广,以支持 GPT-4 Turbo。 | 32,768 个代币 | 截至 2021 年 9 月 |
| gpt-4-32k-0613 | 从 2023 年 6 月 13 日起的快照gpt-4-32k,改进了函数调用支持。该模型从未被广泛推广,以支持 GPT-4 Turbo。 | 32,768 个代币 | 截至 2021 年 9 月 |
多语言能力
GPT-4 的表现优于之前的大型语言模型,并且截至 2023 年,优于大多数最先进的系统(这些系统通常具有针对基准的训练或手工工程)。在 MMLU 基准(一套涵盖 57 个科目的英语多项选择题)上,GPT-4 不仅在英语方面的表现远远优于现有模型,而且在其他语言方面也表现出色。
GPT-3.5 Turbo
GPT-3.5 Turbo 模型可以理解和生成自然语言或代码,并且已经使用聊天完成 API针对聊天进行了优化,但对于非聊天任务也同样适用。
请注意:标记黄色的3种模型都在2024年6月过期了。请注意。
| 模型 | 描述 | 上下文窗口 | 训练数据 |
| GPT-3.5-Turbo-0125 | 新的 更新的 GPT 3.5 Turbo 最新的 GPT-3.5 Turbo 模型在响应请求格式时具有更高的准确度,并修复了导致非英语语言函数调用出现文本编码问题的错误。最多返回 4,096 个输出标记。 | 16,385 个代币 | 截至 2021 年 9 月 |
| GPT-3.5-Turbo | 目前指向gpt-3.5-turbo-0125。 | 16,385 个代币 | 截至 2021 年 9 月 |
| gpt-3.5-turbo-1106 | GPT-3.5 Turbo 模型具有改进的指令跟踪、JSON 模式、可重现输出、并行函数调用等。最多返回 4,096 个输出标记。 | 16,385 个代币 | 截至 2021 年 9 月 |
| gpt-3.5-turbo-Instruct | 与 GPT-3 时代模型具有类似的功能。与旧版 Completions 端点兼容,但不与 Chat Completions 兼容。 | 4,096 个代币 | 截至 2021 年 9 月 |
| gpt-3.5-turbo-16k | 目前指向gpt-3.5-turbo-16k-0613。 | 16,385 个代币 | 截至 2021 年 9 月 |
| GPT-3.5-turbo-0613 | gpt-3.5-turbo自 2023 年 6 月 13 日起的快照。将于 2024 年 6 月 13 日弃用。 | 4,096 个代币 | 截至 2021 年 9 月 |
| GPT-3.5-turbo-16K-0613 | gpt-3.5-16k-turbo自 2023 年 6 月 13 日起的快照。将于 2024 年 6 月 13 日弃用。 | 16,385 个代币 | 截至 2021 年 9 月 |
DALL-E
DALL·E 是一个人工智能系统,可以根据自然语言描述创建逼真的图像和艺术作品。DALL·E 3 目前支持根据提示创建具有特定尺寸的新图像。DALL·E 2 还支持编辑现有图像或创建用户提供图像的变体。
DALL·E 3可通过我们的图片 API和DALL·E 2获得。您可以通过ChatGPT Plus试用 DALL·E 3 。
| 模型 | 描述 |
| dall-e-3 | DALL·E 3 最新的 DALL·E 型号于 2023 年 11 月发布。 |
| dall-e-2 | 上一个 DALL·E 模型于 2022 年 11 月发布。DALL·E 的第 2 次迭代比原始模型具有更逼真、更准确且分辨率高 4 倍的图像。 |
Whisper
Whisper 是一种通用语音识别模型。它基于大量多样化音频数据集进行训练,也是一种多任务模型,可以执行多语言语音识别以及语音翻译和语言识别。Whisper v2-large 模型目前可通过我们的 API 使用,模型whisper-1名称为。有关 Whisper 的更多技术细节,可以阅读论文。
Embedding
Embedding嵌入是文本的数字表示,可用于衡量两段文本之间的相关性。嵌入对于搜索、聚类、推荐、异常检测和分类任务非常有用。
| 模型 | 描述 | 输出维度 |
| text-embedding-3-large | Embedding V3 large 最适用于英语和非英语任务的嵌入模型 | 3,072 |
| text-embedding-3-small | Embedding V3 small 比第二代 ada 嵌入模型性能有所提升 | 1,536 |
| text-embedding-ada-002 | 最强大的第二代嵌入模型,取代了 16 个第一代模型 | 1,536 |
Moderation
Moderation审核模型旨在检查内容是否符合 OpenAI 的使用政策。这些模型提供分类功能,可查找以下类别的内容:仇恨、仇恨/威胁、自残、性、性/未成年人、暴力和暴力/图形。
审核模型接受任意大小的输入,并自动将其分解为 4,096 个标记的块。如果输入超过 32,768 个标记,则会使用截断,在极少数情况下,审核检查可能会忽略少量标记。
每次向审核端点发出请求的最终结果都会显示每个类别的最大值。例如,如果一个 4K 令牌块的类别得分为 0.9901,而另一个的得分为 0.1901,则结果将在 API 响应中显示 0.9901,因为它更高。
| 模型 | 描述 | 最大代币数 |
| text-moderation-latest | 目前指向text-moderation-007。 | 32,768 |
| text-moderation-stable | 目前指向text-moderation-007。 | 32,768 |
| text-moderation-007 | 所有类别中最强大的审核模型。 | 32,768 |
语音合成
TTS 是一种将文本转换为自然发音的口语文本的 AI 模型。我们提供两种不同的模型变体,tts-1针对实时文本转语音用例进行了优化,并针对质量进行了优化。这些模型可以与Audio API 中的 Speech 端点tts-1-hd一起使用。
| 模型 | 描述 |
| tts-1 | 文本转语音 1 最新的文本转语音模型,速度进行了优化。 |
| tts-1-hd | 文本转语音 1 HD 最新的文本转语音模型,针对质量进行了优化。 |
GPTbase
GPT 基础模型可以理解和生成自然语言或代码,但未经过指令训练。这些模型旨在替代我们原来的 GPT-3 基础模型,并使用旧版 Completions API。大多数客户应该使用 GPT-3.5 或 GPT-4。
| 模型 | 描述 | 最大代币数 | 训练数据 |
| babbage-002 | GPT-3ada和babbage基础型号的替代品。 | 16,384 个代币 | 截至 2021 年 9 月 |
| davinci-002 | GPT-3curie和davinci基础型号的替代品。 | 16,384 个代币 | 截至 2021 年 9 月 |
生产使用的关键内容
设置您的组织
登录OpenAI 帐户后,可以在组织设置中找到您的组织名称和 ID 。组织名称是您的组织的标签,显示在用户界面中。组织 ID 是您的组织的唯一标识符,可用于 API 请求。
属于多个组织的用户可以传递标头来指定用于 API 请求的组织。这些 API 请求的使用量将计入指定组织的配额。如果未提供标头,则将向默认组织计费。您可以在用户设置中更改默认组织。
您可以从团队页面邀请新成员加入您的组织。成员可以是读者或所有者。读者可以发出 API 请求并查看基本组织信息,而所有者可以修改账单信息并管理组织内的成员。
管理账单限额
要开始使用 OpenAI API,请输入您的账单信息。如果未输入账单信息,您仍然可以登录,但无法发出 API 请求。
在中国区是被禁止使用的。因为账单绑定美国信用卡。
输入账单信息后,您将获得每月 100 美元的批准使用限额,该限额由 OpenAI 设定。随着您在平台上的使用量增加以及您从一个使用层级转移到另一个使用层级,您的配额限额将自动增加。您可以在帐户设置中的限额页面中查看当前的使用限额。
如果您希望在使用量超过一定金额时收到通知,您可以通过使用量限制页面设置通知阈值。当达到通知阈值时,组织所有者将收到电子邮件通知。您还可以设置每月预算,这样一旦达到每月预算,任何后续 API 请求都将被拒绝。请注意,这些限制是尽最大努力实现的,使用量和强制执行的限制之间可能会有 5 到 10 分钟的延迟。
API 密钥
OpenAI API 使用 API 密钥进行身份验证。访问您的API 密钥页面以检索您将在请求中使用的 API 密钥。
这是一种相对简单的访问控制方法,但您必须小心保护这些密钥。避免在代码或公共存储库中公开 API 密钥;相反,将它们存储在安全的位置。您应该使用环境变量或机密管理服务将密钥公开给您的应用程序,这样您就无需在代码库中对它们进行硬编码。
启用跟踪后,可以在使用情况页面上监控 API 密钥的使用情况。如果您使用的是 2023 年 12 月 20 日之前生成的 API 密钥,则默认情况下不会启用跟踪。您可以在API 密钥管理仪表板上启用跟踪。2023 年 12 月 20 日之后生成的所有 API 密钥都已启用跟踪。任何以前未跟踪的使用情况都将显示Untracked在仪表板中。
暂存帐户
随着规模的扩大,您可能希望为暂存环境和生产环境创建单独的组织。请注意,您可以使用两个单独的电子邮件地址(如bob+prod@widgetcorp.com和bob+dev@widgetcorp.com)注册以创建两个组织。这样您就可以隔离开发和测试工作,以免意外中断实时应用程序。您还可以通过这种方式限制对生产组织的访问。
如何充值和支付
总体来看,官方的充值接口在这里
https://openai.com/api/pricing
https://platform.openai.com/settings/organization/billing/overview
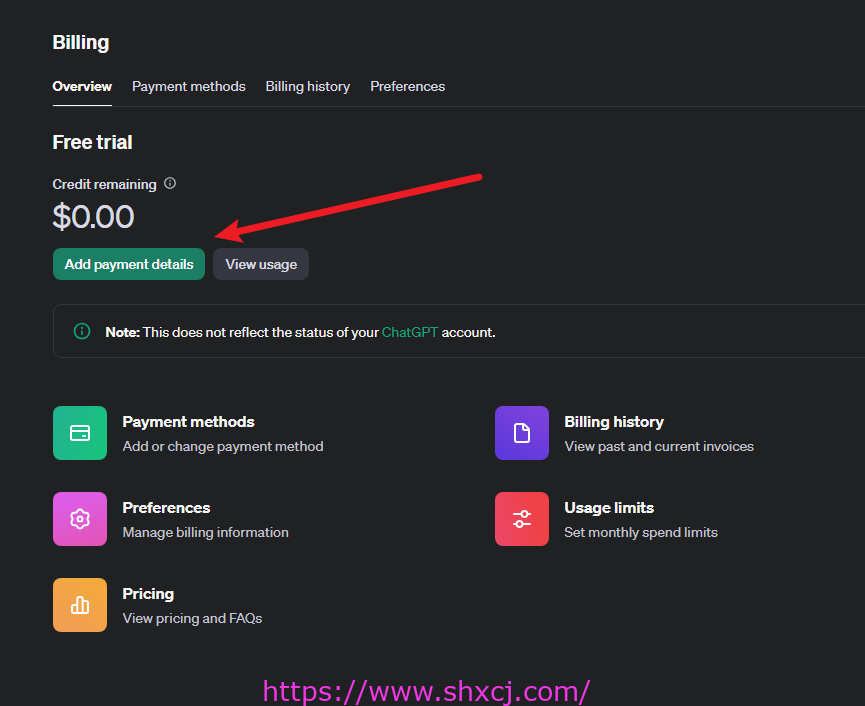
充值的方式只有一种。
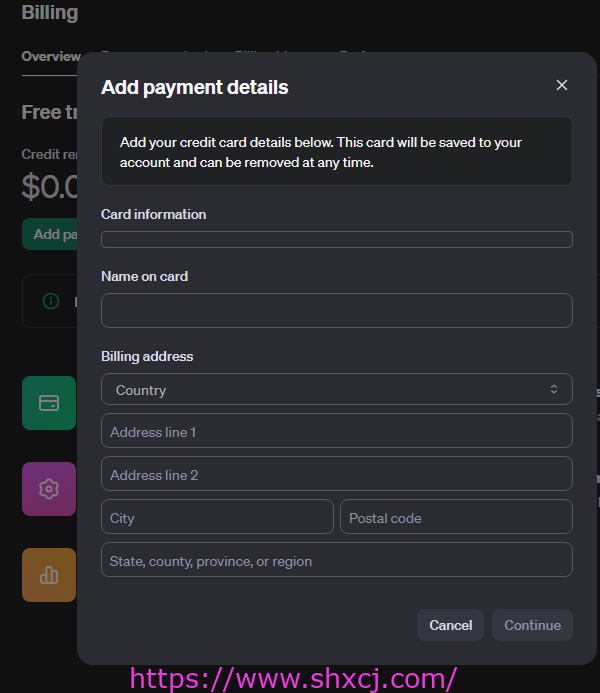
使用美国的信用卡。如下图。
助理 API
我们可以编写自己的应用程序,通过调用我们在GPT上创建的账户体系内建立的Key来在我们的开发语言中调用GPT的API的能力。这里我们借助 Assistants API,您可以在自己的应用程序中构建 AI 助手。助手具有指令,可以利用模型、工具和文件来响应用户查询。Assistant API 目前支持三种类型的工具:代码解释器、文件搜索和函数调用。
概述
助手 API 的典型集成具有以下流程:
- 通过定义自定义指令和选择模型来创建助手。如果有帮助,请添加文件并启用代码解释器、文件搜索和函数调用等工具。
- 当用户开始对话时创建一个主题。
- 当用户提出问题时,向主题添加消息。
- 在线程上运行助手,通过调用模型和工具来生成响应。
调用 Assistants API 需要您传递一个测试版 HTTP 标头。如果您使用的是 OpenAI 的官方 Python 或 Node.js SDK,则会自动处理此操作。
OpenAI-Beta: assistants=v2步骤 1:创建助手
助手代表一个实体,可以配置为使用多个参数(例如、和)来响应用户的消息。modelinstructionstools
from openai import OpenAI
client = OpenAI()
assistant = client.beta.assistants.create(
name="Math Tutor",
instructions="You are a personal math tutor. Write and run code to answer math questions.",
tools=[{"type": "code_interpreter"}],
model="gpt-4o",
)步骤 2:创建话题
线程代表用户与一个或多个助手之间的对话。当用户(或您的 AI 应用程序)开始与您的助手对话时,您可以创建一个线程。
thread = client.beta.threads.create()步骤 3:向话题添加消息
用户或应用程序创建的消息内容将作为消息对象添加到线程中。消息可以包含文本和文件。您可以添加到线程的消息数量没有限制——我们会巧妙地截断任何不适合模型上下文窗口的上下文。
message = client.beta.threads.messages.create(
thread_id=thread.id,
role="user",
content="I need to solve the equation 3x + 11 = 14. Can you help me?"
)步骤 4:创建运行
将所有用户消息添加到线程后,您可以使用任何助手运行线程。创建运行使用与助手相关的模型和工具来生成响应。这些响应将作为assistant消息添加到线程中。
from typing_extensions import override
from openai import AssistantEventHandler
# First, we create a EventHandler class to define
# how we want to handle the events in the response stream.
class EventHandler(AssistantEventHandler):
@override
def on_text_created(self, text) -> None:
print(f"\nassistant > ", end="", flush=True)
@override
def on_text_delta(self, delta, snapshot):
print(delta.value, end="", flush=True)
def on_tool_call_created(self, tool_call):
print(f"\nassistant > {tool_call.type}\n", flush=True)
def on_tool_call_delta(self, delta, snapshot):
if delta.type == 'code_interpreter':
if delta.code_interpreter.input:
print(delta.code_interpreter.input, end="", flush=True)
if delta.code_interpreter.outputs:
print(f"\n\noutput >", flush=True)
for output in delta.code_interpreter.outputs:
if output.type == "logs":
print(f"\n{output.logs}", flush=True)
# Then, we use the `stream` SDK helper
# with the `EventHandler` class to create the Run
# and stream the response.
with client.beta.threads.runs.stream(
thread_id=thread.id,
assistant_id=assistant.id,
instructions="Please address the user as Jane Doe. The user has a premium account.",
event_handler=EventHandler(),
) as stream:
stream.until_done()助理的工作原理
Assistants API 旨在帮助开发人员构建能够执行各种任务的强大 AI 助手。
- 助手可以通过特定指令调用 OpenAI 的模型来调整其个性和能力。
- 助手可以并行访问多个工具。这些工具可以是 OpenAI 托管的工具(如code_interpreter和file_search),也可以是你构建/托管的工具(通过函数调用)。
- 助手可以访问持久线程。线程通过存储消息历史记录并在对话长度超过模型上下文长度时截断消息历史记录来简化 AI 应用程序开发。您只需创建一次线程,然后在用户回复时将消息附加到其中即可。
- 助理可以访问多种格式的文件 – 既可以作为其创建文件的一部分,也可以作为助理与用户之间的线程的一部分。使用工具时,助理还可以创建文件(例如图片、电子表格等)并在其创建的消息中引用他们引用的文件。
对象
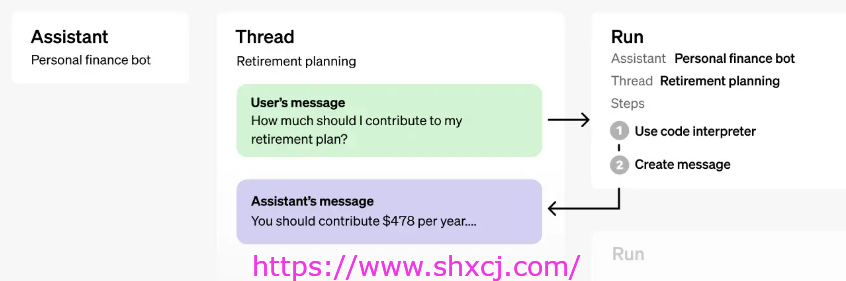
| 目的 | 它代表什么 |
| 助手 | 使用 OpenAI模型并调用工具的专用 AI |
| Thread | 助手与用户之间的对话会话。线程存储消息并自动处理截断以使内容适合模型的上下文。 |
| Message | 由助手或用户创建的消息。消息可以包含文本、图片和其他文件。消息以列表形式存储在主题中。 |
| Run | 在线程上调用助手。助手使用其配置和线程的消息通过调用模型和工具来执行任务。作为运行的一部分,助手将消息附加到线程。 |
| Run Steps | 助手在运行过程中所采取步骤的详细列表。助手可以在运行期间调用工具或创建消息。检查运行步骤可让您了解助手如何获得最终结果。 |
Paragoger衍生者AI训练营。发布者:稻草人,转载请注明出处:https://www.shxcj.com/archives/2602