
前言:
上一节我们主要介绍ControlNet中的图像细节修复和高清放大Tile能力
这一节主要介绍ControlNet中的Seg语义分割。我们之前有学习过有点同名的 4-13 抠图分块神器 Segment Anything 。
在实现的目的上面是类似的,就是针对场景进行各种算法基础下的语义分割和识别能力。主要是基于ControlNet的框架机制下,可以混合做更多的事情。
但工具永远只是工具,就看你具体要怎么使用了。
知识点:
- Seg语义分割
基础官方知识:
通过语义分割控制稳定扩散。
模型文件:control_v11p_sd15_seg.pth
配置文件:control_v11p_sd15_seg.yaml
训练数据:COCO + ADE20K。
可接受的预处理器:Seg_OFADE20K (Oneformer ADE20K)、Seg_OFCOCO (Oneformer COCO)、Seg_UFADE20K (Uniformer ADE20K) 或手动创建的掩模。
现在该模型可以接收 ADE20K 或 COCO 注释两种类型。我们发现识别分段协议对于 ControlNet 编码器来说是微不足道的,并且训练多个分段协议的模型可以带来更好的性能。
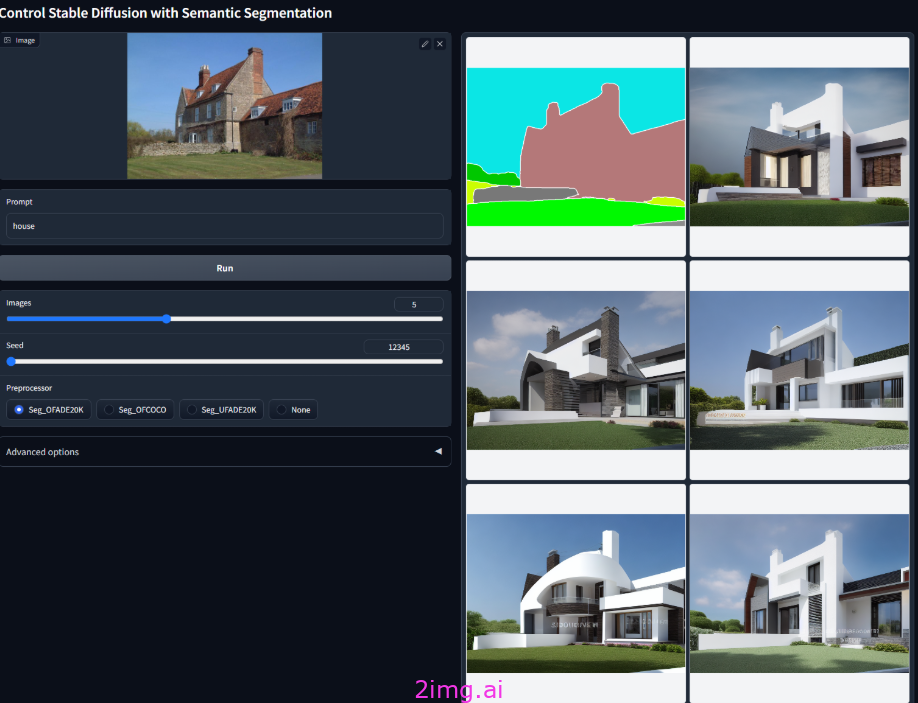

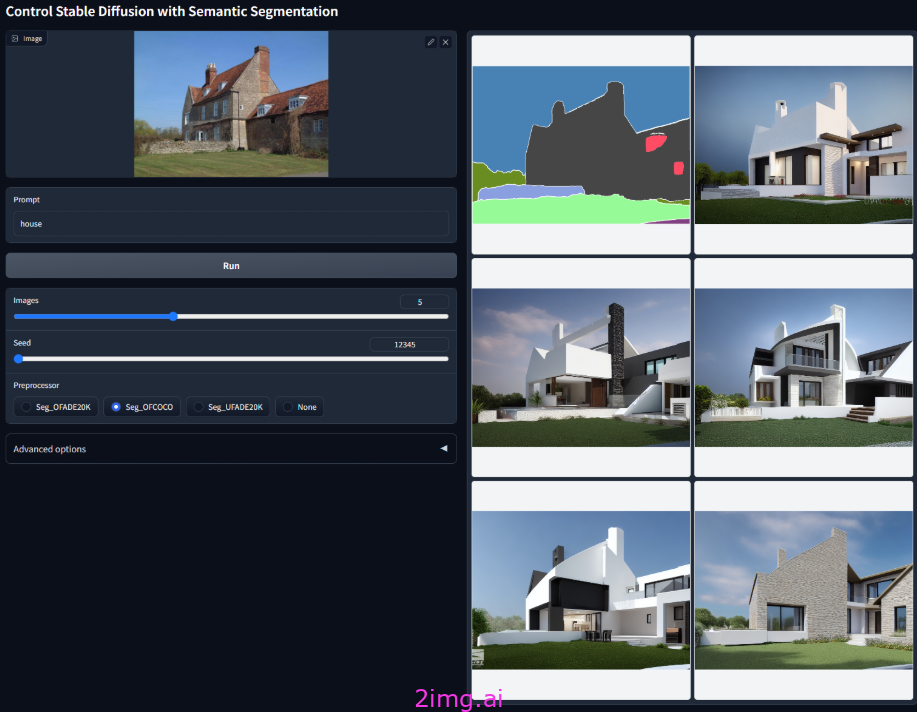
实战
设计中的语义分割图,根据色块生成不同的物体,识别物体对应色块进行画面的区分,然后根据关键词的描述生成该物体在图片中的样子。
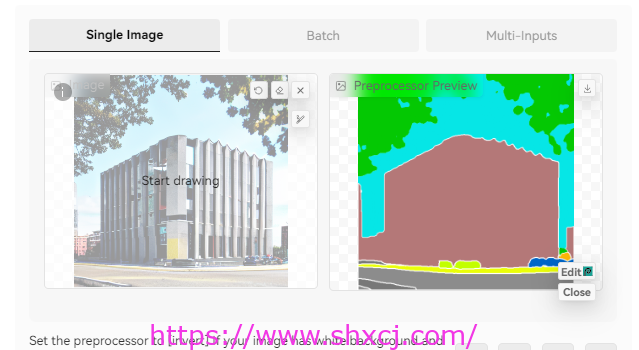
很粗狂的使用效果。一种色块一种颜色区域的最终效果展示。
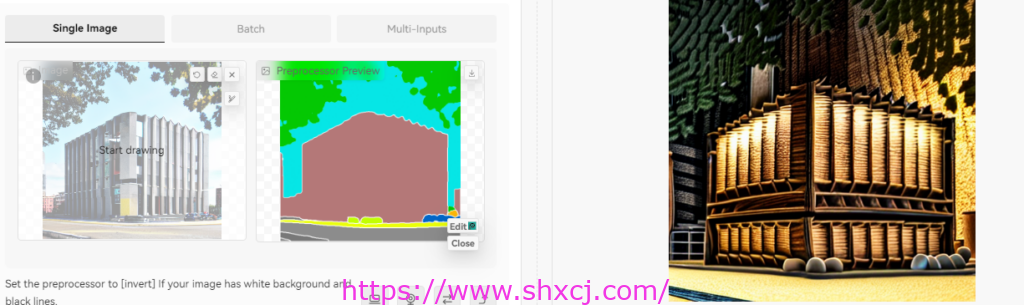
总体上,从分割后的预览效果图上可以看到,seg将房屋作为一个整体分割了出来,也就是说后续新生成的图像仅会保持结构一致,但细节将会发生很大的改变。
RA/SD 衍生者AI训练营。发布者:稻草人,转载请注明出处:https://www.shxcj.com/archives/1443