前言:
上一章,我们介绍局部重绘的各种基础知识和技巧点
本章,我们介绍如何将我们的涂鸦或者草图,直接生成更好看的图片
AIGC的强大能力,冲击最大,最直接的就是原画师,原画师的随手涂鸦,或者更专业点说手绘的内容,在RA/SD的AIGC体系下,高效的被运行和提升。
很多人会问,AIGC会代替原画师吗?很抱歉的回复你,大概率会。以RA/SD为代表的AIGC体系产品,不仅在生成能力,生产效率,想象力,调整能力,都会在近期大量冲击美术市场。
本文的涂鸦草图内容生成实景图,应该是一个非常具有代表性的展现了。
知识点:
- 涂鸦生图草图
基础知识:
“涂鸦生图”功能的原理,涉及将用户的简笔画(涂鸦)转换为详细、艺术化的图像。这一过程依赖于扩散模型及其相关技术,以在提供基本结构或提示的基础上生成复杂的图像。
以下是涂鸦生图的详细原理和步骤:
基本原理
- 输入涂鸦:
- 用户提供一个简笔画或涂鸦,作为生成图像的基础。这通常是一个简单的线条图,表示图像的基本结构和布局。
- 条件生成(Conditional Generation):
- 扩散模型通过条件生成技术,根据输入的涂鸦生成图像。条件生成技术使模型能够根据提供的特定条件(如涂鸦、文本提示)生成相应的图像。
- 扩散过程:
- 扩散过程是指模型通过多次迭代生成图像,从初始的噪声图像逐步逼近目标图像。每一步生成过程中,模型会考虑输入的条件(如涂鸦)来调整生成的图像。
详细步骤
- 初始化:
- 输入涂鸦被处理为图像生成的初始条件。通常会将涂鸦转换为一个适合模型处理的格式,如特定的张量表示。
- 扩散模型的反向过程:
- 扩散模型开始反向过程,从高噪声图像逐步生成低噪声、详细的图像。这个过程包括多个迭代步骤,每一步都会生成一个逐步细化的图像。
- 噪声注入和调整:
- 在每一步迭代中,模型会注入少量噪声,同时根据涂鸦的结构调整生成的图像。模型使用噪声和条件提示来探索不同的图像细节,从而逐步生成高质量的图像。
- 最终输出:
- 最终,模型输出一个详细、艺术化的图像,保留了用户输入的涂鸦的基本结构,同时添加了丰富的细节和艺术效果。
关键技术
- 扩散模型(Diffusion Models):
- 扩散模型通过模拟一个逐步去噪的过程,从随机噪声开始逐步生成清晰的图像。每一步生成都依赖于前一步的结果和条件输入。
- 条件生成(Conditional Generation):
- 条件生成技术允许模型根据特定的输入条件生成图像。这在涂鸦生图中尤为重要,因为模型需要根据用户的涂鸦生成相应的图像。
- 去噪自动编码器(Denoising Autoencoders):
- 去噪自动编码器在扩散模型中用于处理噪声注入和去噪过程,确保生成图像的质量和细节。
涂鸦草图生图原理
原图,实际上也借用了图生图的生成原理,将这个草图的关键特征作为生成目标图的依据。

如果不操作什么关键字,直接选择一个大模型,后用图生图。效果图如下
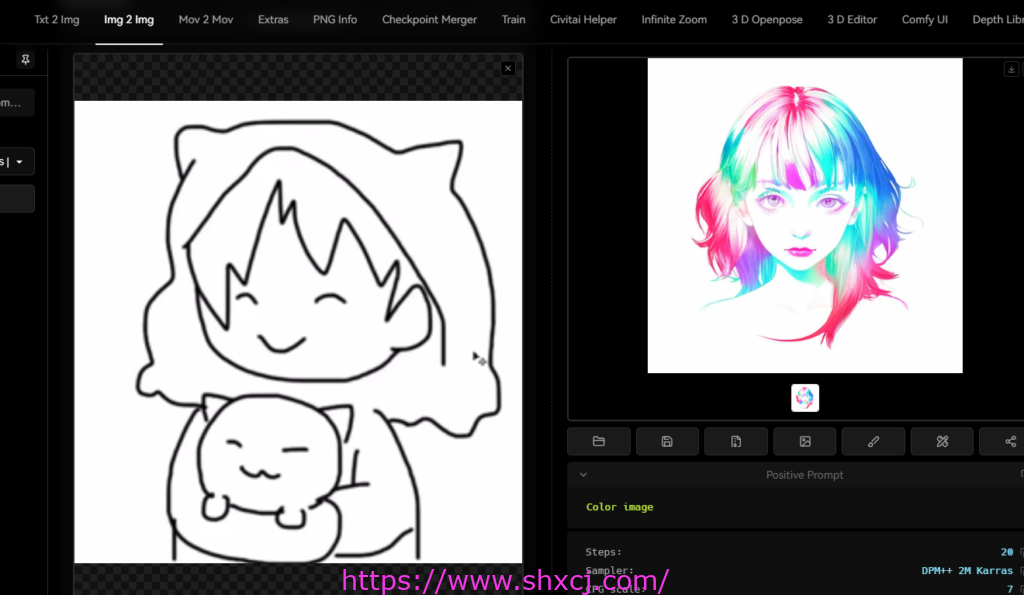
这个效果有点差强人意。
并不能展示我们要的2个人物的效果。 同时还有拥抱的意思。
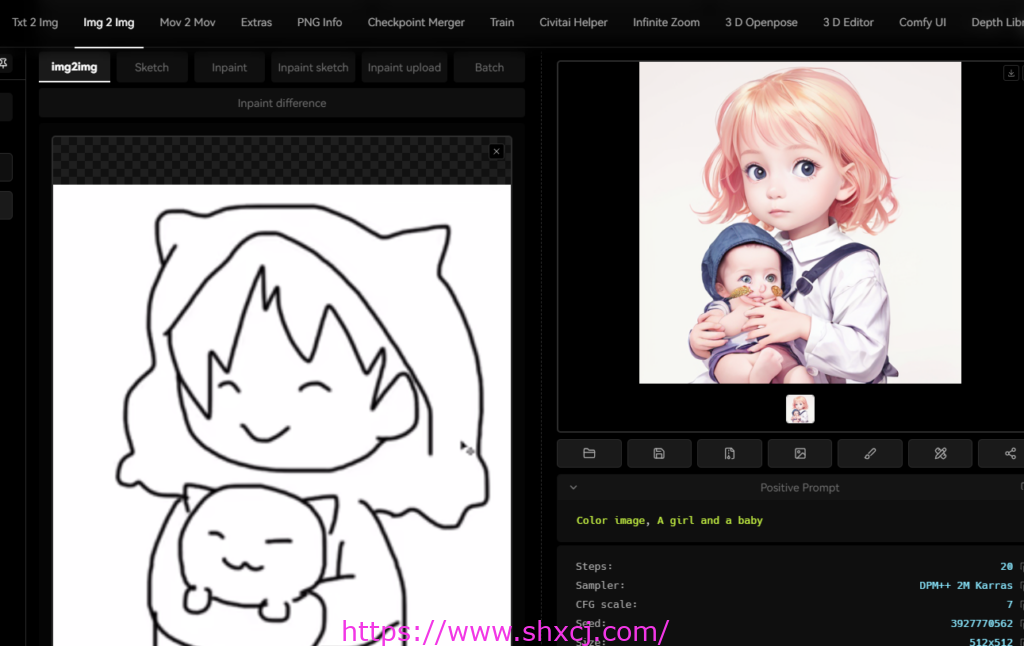
此时,我们通过关键字,强化下我们要表达的内容。
Color image , a girl and a baby .
效果图如下 .
此时我们可以看到。不仅人物,角度, 形状, 都非常贴切我们想要表达的草图的效果。 对吧。
圖中的生成有一個小瑕疵,原圖中抱的東西, AI並不能一定是個baby.
总结
总体来说,这个技术非常有使用价值,我们随便在草稿上画一笔,就能生成很酷的图片。 难道还不酷吗?
Paragoger衍生者AI训练营。发布者:稻草人,转载请注明出处:https://www.shxcj.com/archives/1014