
概要
首先,什么是Ollama
Ollama 是一个用于构建和运行自定义 AI 模型的平台。它允许开发者和企业使用自己的数据来训练专门的 AI 模型,并且提供了一些工具,使得在不同应用场景中能够部署这些模型。Ollama 的目标是让用户能够更容易地创建和管理自己的人工智能应用,同时提供高效的计算资源和易于使用的接口。
它也支持与开源模型兼容,让开发者能在本地环境中运行和定制 GPT 类模型,从而减少对外部云服务的依赖。对于那些希望实现私有化部署的企业或者个人,Ollama 提供了一种灵活且易于操作的解决方案。
个人技术博客: fuqifacai.github.io
更多技术资讯下载: 2img.ai
相关配图由微信小程序【字形绘梦】免费生成


其次,谁在维护Ollama
它的开源地址:https://github.com/ollama/ollama
它的官网:https://ollama.com/
从搜索引擎上获取的信息,这家公司是由几个年轻人创建的。但确实没有更多的资讯了。这很奇怪。
再次,Ollama主要怎么玩
用户可以访问官网,或者Github上的库,看到指引。大致如下:
- 安装不同操作系统的可执行包,然后确保服务正确运行
- 使用模型下载或运行的指令,下载各种模型,具体模型的名字和使用方法参见官网页面:https://ollama.com/search
- 直接在内置的指令界面中进行聊天。 或者更好的通过各种web化的界面,进行更友好的交互使用。比如ollama-webui-lite
总之:
总体来看,我个人的感受,什么是Ollama,它主要能帮助到我们什么
- 它是一个LLM的框架、工具,可以帮助我们下载,使用,训练各种其余厂商提供的大模型能力。
- 它提供一些API的能力,你可以调用这个框架,结合到你自己的应用中。
- 它很适用于本地部署,让你具备本地大模型框架等一切你可以拥有的AI世界的内容。
类似这样的框架,目前来看,还不少,本文详细介绍下Ollama,至于和横向产品的比较在后续的文档中展开。

正文
本文的重点,罗列和分析各厂商大模型的情况和性能。
1 大模型列表
| 模型名称 | 总结评分 | 中文能力 | 授权协议 | 心得 |
| deepseek-r1 | 80 | 支持 | MIT License | DeepSeek 的第一代推理模型,在数学、代码和推理任务中实现了与 OpenAI-o1 相当的性能。内容确实很丰富,但是质量不是很高。 |
| llama3.3 | 90 | 支持 | 协议相对宽松。Llama使用了“开源协议+使用政策”的模式约束和调整与开发者的关系,前者协议主要用来调整关系,而后者政策主要用来约束行为 具体访问 https://www.llama.com/llama3/license/ | 感觉质量蛮高的。就是对GPU性能加载有要求 |
| phi4 | 92 | 支持 | MIT License | 非常有趣的模型。个人非常喜欢。代码质量真的超级高。微软出品。 |
2 各大模型详细解释和学习
2.1 Deepseek-r1
总体评价
70分感觉
我问【字形绘梦】
显示其余的老旧信息。
模型介绍
DeepSeek 的第一代推理模型,在数学、代码和推理任务中实现了与 OpenAI-o1 相当的性能。
模型
DeepSeek-R1
ollama run deepseek-r1:671b提炼模型
DeepSeek 团队已经证明,较大模型的推理模式可以提炼为较小的模型,从而获得比在小模型上通过 RL 发现的推理模式更好的性能。
以下是使用 DeepSeek-R1 生成的推理数据,针对研究界广泛使用的几种密集模型进行微调而创建的模型。评估结果表明,提炼出的较小密集模型在基准测试中表现优异。
问题测试
我问【字形绘梦微信小程序】
它有一定的智能,竟然开始设计一个小程序了。考虑到了,产品设计,需求,框架,前后端设计等。
我问【
在C#中如何使用RestRequest库请求multipart/form-data的Post内容,直接给我代码接口
】
回答非常多的内容。有结构层次,但是代码可用度不太高。

2.2 llama 3.3
总体评价
90分感觉(硬件显存有点要求)
加载后感觉显存要求高,处理性能慢。
模型介绍:
Meta 的全新先进 70B型号具有与 Llama 3.1 405B 型号相似的性能。
Meta Llama 3.3 多语言大型语言模型 (LLM) 是一个经过预训练和指令调整的生成模型,大小为 70B(文本输入/文本输出)。Llama 3.3 指令调整纯文本模型针对多语言对话用例进行了优化,在常见行业基准上的表现优于许多可用的开源和封闭聊天模型。
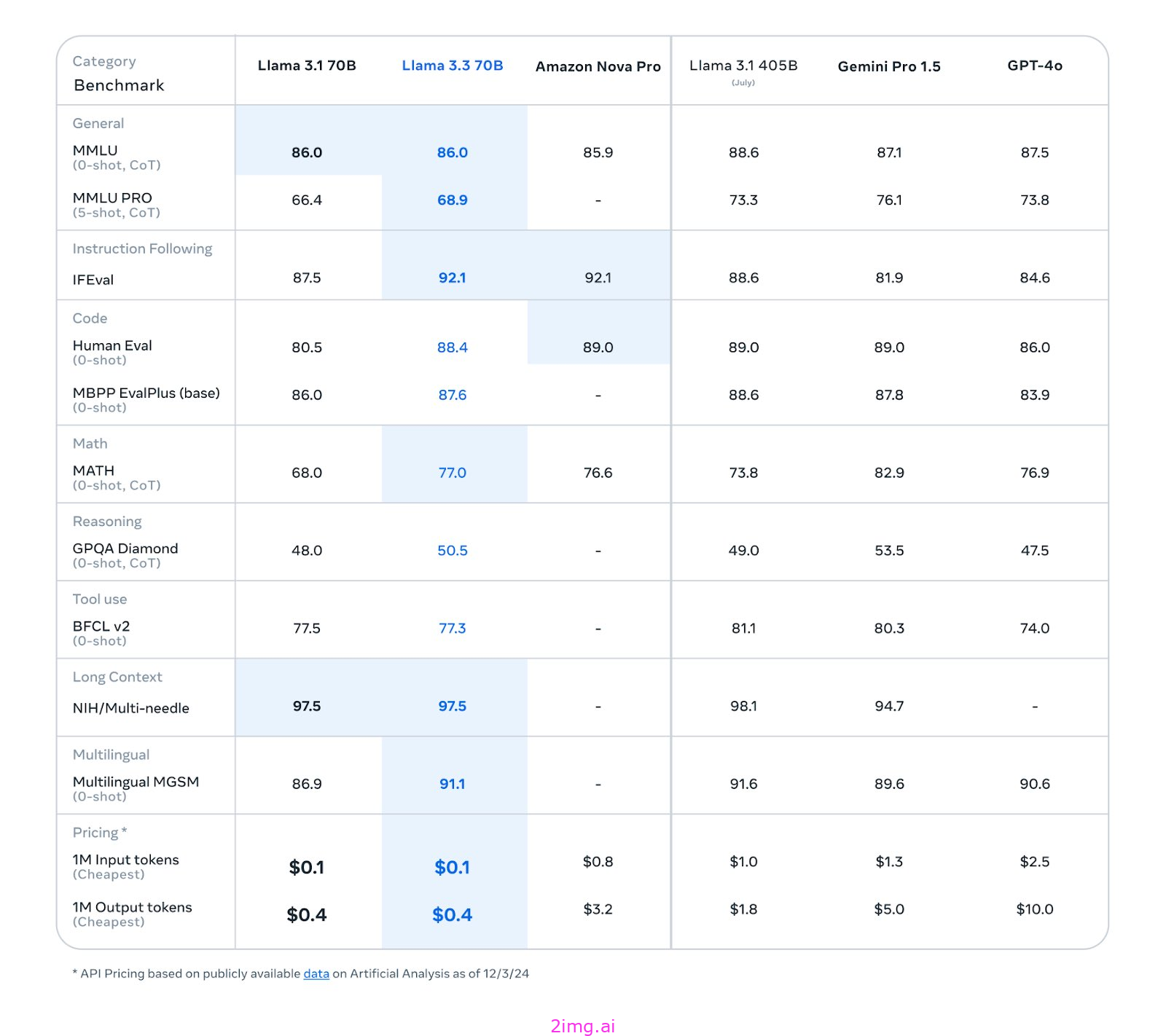
支持的语言:英语、德语、法语、意大利语、葡萄牙语、印地语、西班牙语和泰语。
新功能
此版本引入了新功能,包括更长的上下文窗口、多语言输入和输出以及开发人员可能与第三方工具集成的功能。除了通常适用于所有生成式 AI 用例的最佳实践之外,使用这些新功能进行构建还需要进行特定考虑。
工具使用:与标准软件开发一样,开发人员负责将 LLM 与他们选择的工具和服务集成。他们应该为自己的用例定义明确的政策,并评估他们使用的第三方服务的完整性,以了解使用此功能时的安全性和保障限制。有关安全部署第三方保障措施的最佳实践,请参阅《负责任使用指南》。
多语言性: Llama 3.3 除英语外还支持 7 种语言:法语、德语、印地语、意大利语、葡萄牙语、西班牙语和泰语。除了满足安全性和实用性性能阈值的语言外,Llama 还可以输出其他语言的文本。我们强烈建议开发者不要使用此模型使用不受支持的语言进行交流,除非他们根据自己的政策和《负责任使用指南》中分享的最佳实践实施微调和系统控制。
预期用途
预期用例Llama 3.3 适用于多种语言的商业和研究用途。指令调整的纯文本模型适用于类似助手的聊天,而预训练模型可以适应各种自然语言生成任务。Llama 3.3 模型还支持利用其模型的输出来改进其他模型(包括合成数据生成和提炼)。Llama 3.3 社区许可证允许这些用例。
超出范围的使用以任何违反适用法律或法规(包括贸易合规法)的方式进行。以可接受使用政策和 Llama 3.3 社区许可所禁止的任何其他方式使用。以本型号卡中明确提及的支持语言以外的语言使用**。
注意: Llama 3.3 已针对 8 种受支持的语言以外的更多语言进行训练。开发人员可以针对 8 种受支持的语言以外的语言对 Llama 3.3 模型进行微调,前提是他们遵守 Llama 3.3 社区许可证和可接受使用政策,并且在这种情况下,他们有责任确保以安全且负责任的方式使用其他语言的 Llama 3.3。
问题测试
我问【字形绘梦】
没有找到讯息,但是在帮我分析简单的字面意思。结果我很满意。
我问【字形绘梦微信小程序】
总体还可以
我问【在C#中使用RestRequest库请求multipart/form-data的Post,直接给我代码接口】
代码准确度很高。同时对于我用到的依赖也标记了。整体非常好

2.3 Phi4
总体评价
92分感觉。
速度很快。效果有点惊喜。
模型介绍:
Phi-4是一个 14B 参数的最先进的开放模型,建立在合成数据集、来自过滤的公共领域网站的数据以及获得的学术书籍和问答数据集的混合之上。
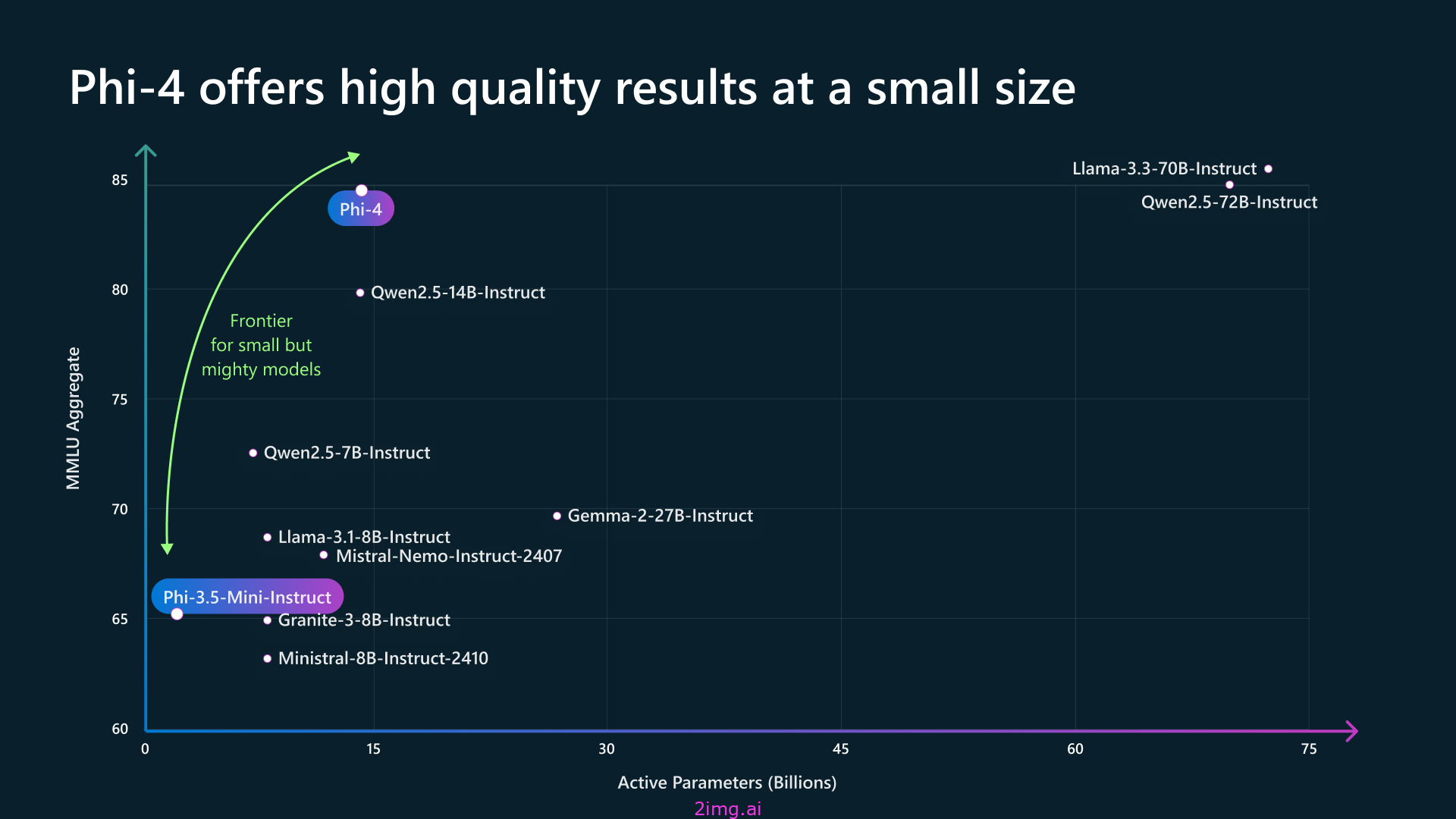
该模型经过了严格的增强和调整过程,结合了监督微调和直接偏好优化,以确保精确遵守指令和强有力的安全措施。
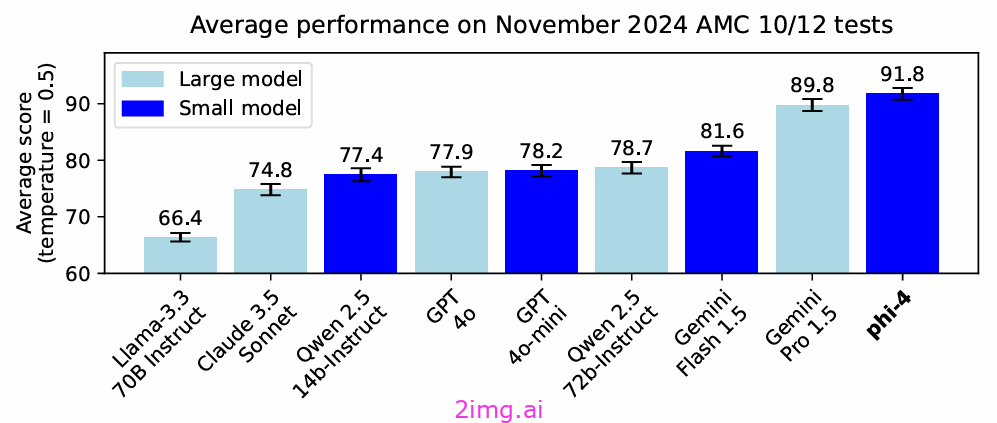
上下文长度: 16k 个 token
主要用例
该模型旨在加速语言模型的研究,作为生成式人工智能功能的基础。它为通用人工智能系统和应用程序(主要是英语)提供用途,这些系统和应用程序需要:
- 内存/计算受限的环境。
- 延迟受限场景。
- 推理和逻辑。
问题测试
我问【字形绘梦】
有图表化的回复,方式让人感觉新颖。非常不错 如下图
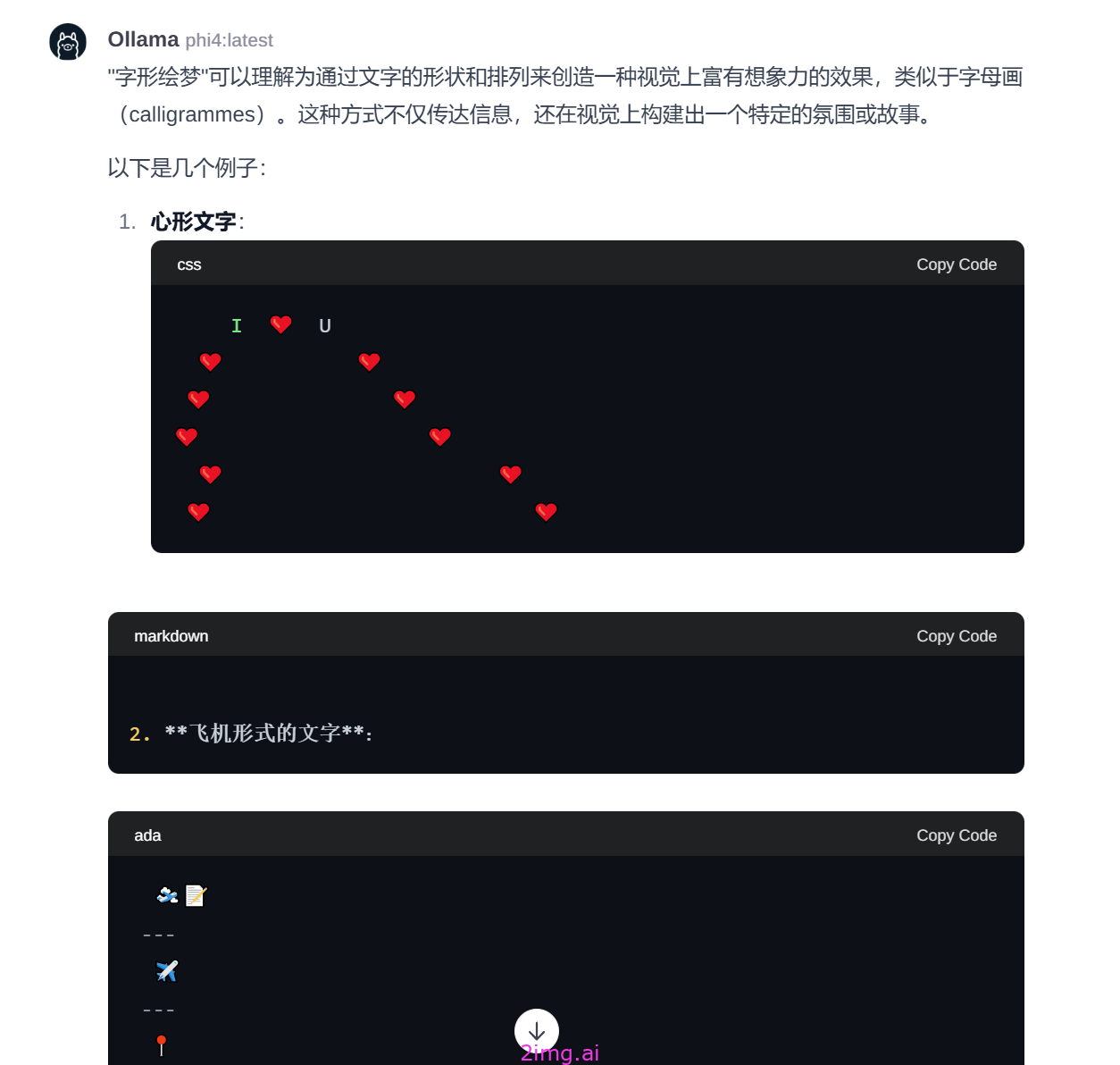
我问【字形绘梦微信小程序】
有点和Deepseek的接近,充分的设计了一个完整的小程序。
我问【在C#中使用RestRequest库请求multipart/form-data的Post,直接给我代码接口】
哇。这个代码的回复可能是最好的。非常完整,结构良好。完成度很高,比Deepseek好非常多,比llama3还要好一些。

RA/SD 衍生者AI训练营。发布者:稻草人,转载请注明出处:https://www.shxcj.com/%e8%be%a3%e5%a6%88%e4%b9%8b%e9%87%8e%e6%9c%9b-3-ollama%e5%90%84%e5%a4%a7%e6%a8%a1%e5%9e%8b%e5%85%a8%e6%96%b9%e4%bd%8d%e5%af%b9%e6%af%941/