
今天介绍一个名为 BEARCUBS 的基准测试,用于评估AI在实时网络环境中的信息搜索、浏览和事实识别能力。
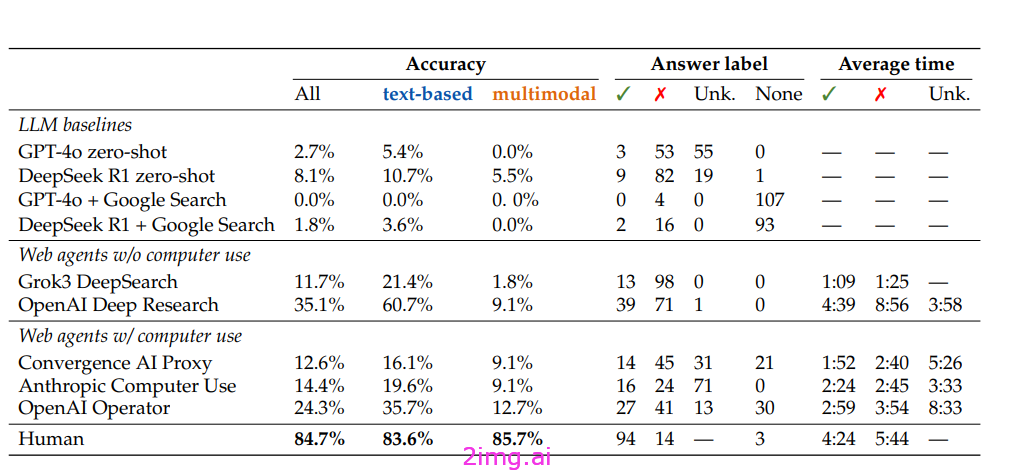
以下是人类和各种AI 大模型目前的能力比对:人类84.7% ,最强的AI目前是OpenAI DeepSearch 35.1%
看来AI赶上人类的智商也就在1-2年左右了。

1. 核心主题:BEARCUBS基准的提出与意义
- 什么是BEARCUBS?
- BEARCUBS 是一个包含 111个信息搜索问题 的基准测试,旨在评估网络代理在真实网络环境中的表现。
- 全称是 BEnchmark for Agents with Real-world Computer Use and Browsing Skills(具备现实世界计算机使用和浏览技能的代理基准)。
- 每个问题都有一个简短、明确的答案,并附带经过人类验证的浏览轨迹,便于透明地评估代理的性能和策略。
- 为什么需要BEARCUBS?
- 现代网络代理具备通过虚拟键盘和鼠标与网页交互的计算机使用能力,有潜力协助人类完成复杂任务。
- 但现有基准(如WebArena、WebShop)多基于合成或模拟环境,无法充分反映代理在动态、不可预测的现实网络中的能力。
- BEARCUBS 通过要求代理访问实时网络内容并执行多模态交互(如视频理解、3D导航),填补了这一评估空白。

2. BEARCUBS的特点与创新
- 实时网络交互:
- 与传统基准不同,BEARCUBS要求代理直接访问真实网页,而非模拟页面,捕捉了现实网络的复杂性与不可预测性。
- 多模态交互:
- 问题分为两类:
- 文本交互问题:可通过阅读和导航文本内容解决。
- 多模态问题:需要理解视频、图像、音频或实时交互(如在线游戏),无法通过纯文本变通方法绕过。
- 这增加了评估的多样性和挑战性。
- 问题分为两类:
- 定期更新机制:
- 为应对网络污染(评估问题可能泄露到训练数据或公共网站),BEARCUBS计划定期替换失效或受污染的问题,保持基准的适用性。

3. 构建过程与设计标准
- 问题设计标准:
- 问题需简短且无歧义。
- 答案需易于评估(单一、明确、简洁)。
- 答案需对抗谷歌搜索(无法通过搜索片段或顶级结果直接获得)。
- 答案必须公开可访问(无需付费或登录)。
- 数据收集:
- 包含111个问题,覆盖文本(56个)和多模态(55个)两类。
- 由作者和Upwork自由职业者共同编写,经过至少两名作者验证,确保质量。
- 剔除了可通过文本变通解决的多模态问题(共13个),以保证多模态交互的必要性。
- 统计数据:
- 涉及108个独特顶级URL。
- 平均每题需6.1个步骤,访问3.4个网页。
4. 实验与结果
- 人类表现:
- 人类准确率为 84.7%,表明问题可解但具有挑战性。
- 常见失败点包括搜索效率低下和领域知识不足。
- 平均耗时4分46秒,平均遇到1.5个死胡同。
- 代理表现:
- 测试了五种前沿代理,包括具备计算机使用能力的代理(如OpenAI的Operator)和非计算机使用代理(如OpenAI的Deep Research)。
- 最佳代理(Operator)准确率仅为 24.3%,Deep Research整体表现最好(35.1%),但在多模态问题上表现不佳(9.1%)。
- 代理在可靠来源选择和多模态能力上普遍不足。
- 对比分析:
- 人类在文本和多模态任务上均显著优于代理。
- 代理在多模态问题上的低表现凸显了其局限性。
5. 讨论与改进方向
- 当前挑战:
- 轨迹透明度:代理提供的行动轨迹细节差异大,影响评估。
- 来源可信度:代理常依赖不可靠来源或无来源回答。
- 多模态能力:代理在视频、游戏等交互中表现欠佳。
- 策略规划:代理搜索效率低,重复无效操作。
- 改进建议:
- 提升轨迹可解释性,提供清晰的搜索和推理过程。
- 加强来源可信度评估,确保答案可靠。
- 增强多模态交互能力,适应动态网络环境。
- 优化任务规划,减少冗余行动。
6. 与其他工作的对比
- 与现有基准相比,BEARCUBS强调实时网络和多模态交互的独特性:
- WebArena、WebShop:基于合成环境,交互单一。
- AssistantBench:关注真实网络但限制多模态交互。
- BEARCUBS填补了多模态和实时性结合的空白。
7. 结论
- 主要贡献:
- 提出了BEARCUBS,一个评估网络代理在真实网络环境中能力的基准。
- 通过实验揭示了代理在多模态交互和来源选择上的不足。
- 未来方向:
- 增强代理的多模态能力、轨迹透明度和规划能力,推动网络代理发展。
总结
BEARCUBS的基准测试,旨在评估具备计算机使用能力的网络代理在实时网络环境中的信息搜索和多模态交互能力。文档详细阐述了BEARCUBS的设计理念、构建过程、实验结果及当前代理的局限性,强调其通过实时性和多模态性区别于现有基准的创新性。通过人类与代理的性能对比,文档指出现有代理在可靠来源选择和多模态能力上的不足,并提出了改进建议。BEARCUBS通过定期更新保持挑战性,为未来网络代理研究提供了重要参考。
RA/SD 衍生者AI训练营。发布者:稻草人,转载请注明出处:https://www.shxcj.com/%e4%ba%ba%e7%b1%bb%e5%92%8cai%e7%9a%84%e8%83%bd%e5%8a%9b%e8%af%84%e6%b5%8b%e5%92%8c%e8%af%a6%e7%bb%86%e5%af%b9%e6%af%94/